HPC CHINA 2018 | GPU加速实现高性能计算新突破
2018-10-24 01:00
 分享到微信
分享到微信
 分享到微博
分享到微博
2018 全国高性能计算学术年会(HPC CHINA 2018)于10月20日在青岛闭幕。大会以“HPC+一切皆可计算”为主题,围绕高性能计算技术的研究发展与发展趋势、高性能计算的重大应用等主题展开。年会上,各领域专家学者围绕着高性能计算技术各抒己见,分享了高性能计算在其各自领域的最新研究进展。NVIDIA公司高性能计算及新兴业务中国区总经理刘通在大会主论坛发表了“NVIDIA GPU面向未来计算的持续创新”主题演讲, 为大家介绍了GPU在高性能计算领域的应用以及创新。
GPU领跑运算性能,实现高性能计算新突破
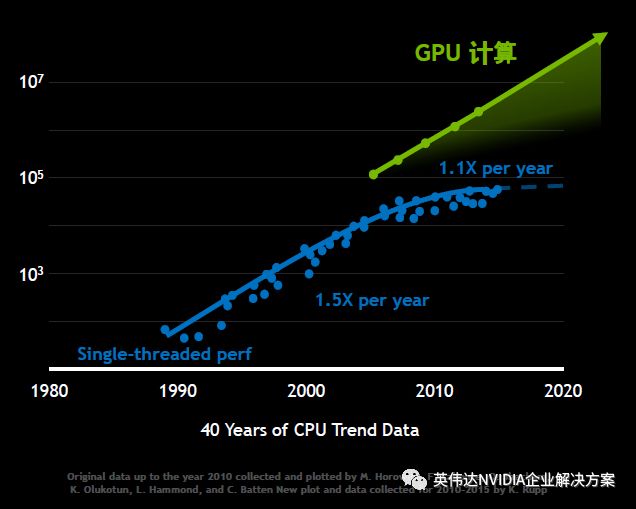
近年来,随着传统处理器在单线程运算方面遭遇到瓶颈,性能加速放缓。GPU为加速计算指明了新方向,GPU加速器每年正在以稳定的速率实现性能提升,其性能提升态势也将持续到未来:
如今 ,GPU框架凭借其强大的并行计算能力,已被众多超级计算机选做算力核心。目前,包括美国Summit、Sierra;日本ABCI;欧洲的Piz Daint在内的诸多全球顶级超级计算机都采用了NVIDIA GPU作为其算力核心。而且,目前已有70%的通用HPC程序已经实现GPU加速:

然而,与其强大算力相对应的是GPU服务器突出的性价比优势。相较于CPU服务器,GPU服务器成本需求更低,原本需要由160台Skylake CPU服务器才能完成的计算量,只需8台V100 GPU 4 卡服务器即可完成,而总体成本仅是Skylake CPU服务器的1/5;1台DGX-2的计算量相当于300台Dual-CPU服务器,总体成本却只有其1/8:

此外,GPU能够实现HPC与AI的融合计算。HPC可为精准计算提供支持,AI则可以提高结果预测准确性加快反应速度。NVIDIA TENSOR CORE GPU能够满足HPC与AI的融合计算,利用多精度混合计算,实现HPC应用性能新突破。

应用广泛,GPU加速计算渗入各个领域
在实现加速计算的同时,GPU加速的超算平台还具有广阔的产业应用范围,能够在精准医药、气象模拟、新材料、无人驾驶、AI等众多领域发挥作用。中国石油东方地球物理公司研究数据处理中心赖能和总工程师在NVIDIA新技术与应用主题分论坛中介绍,中石油正在利用NVIDIA GPU加速计算处理石油海量数据。

在服务产业应用的同时,NVIDIA GPU加速计算也被广泛应用到科学研究中。南京大学周建教授介绍,南京大学高性能计算研究中心在使用NVIDIA GPU加速计算解决VASP杂化泛函数计算时感受了到GPU显著的加速计算效果。在进行CrGeTe3的杂化泛函自洽计算测试时,相较于CPU,GPU的加速计算效果明显。据统计,对于此类较大的系统,1个V100 GPU可以比一个双路CPU服务器快10倍左右:

武汉大学蔡浩教授也在分论坛中进行了介绍,武汉大学过去在使用满带宽振幅分析软件(FALLS)进行分波分析时,存在要处理的事例数巨大;拟合模型非常复杂,参数空间巨大;拟合算法需要的计算步数非常多的困难。然而通过程序优化,拆掉大的数据结构,将计算部分的CUDA代码,全部分解成小的片段,交由GPU计算,提高计算效率;将条件分支全部移到程序外部,交给CPU处理,从而实现了充分调动计算单元:
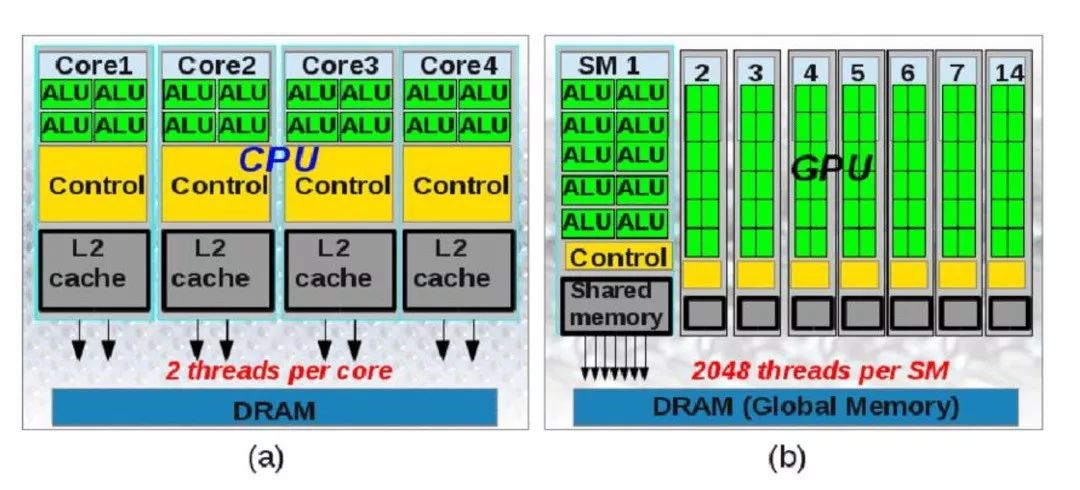
同时,进行算法优化,将所有的求和计算都在GPU中进行,GPU和CPU之间的数据交互降到最低:
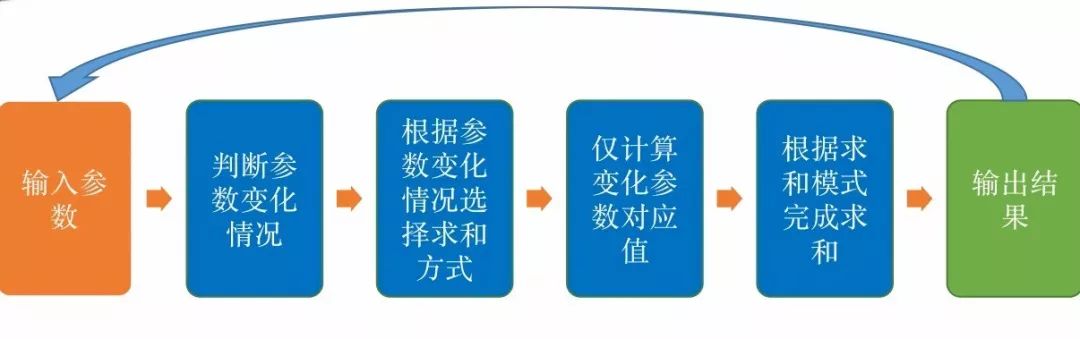
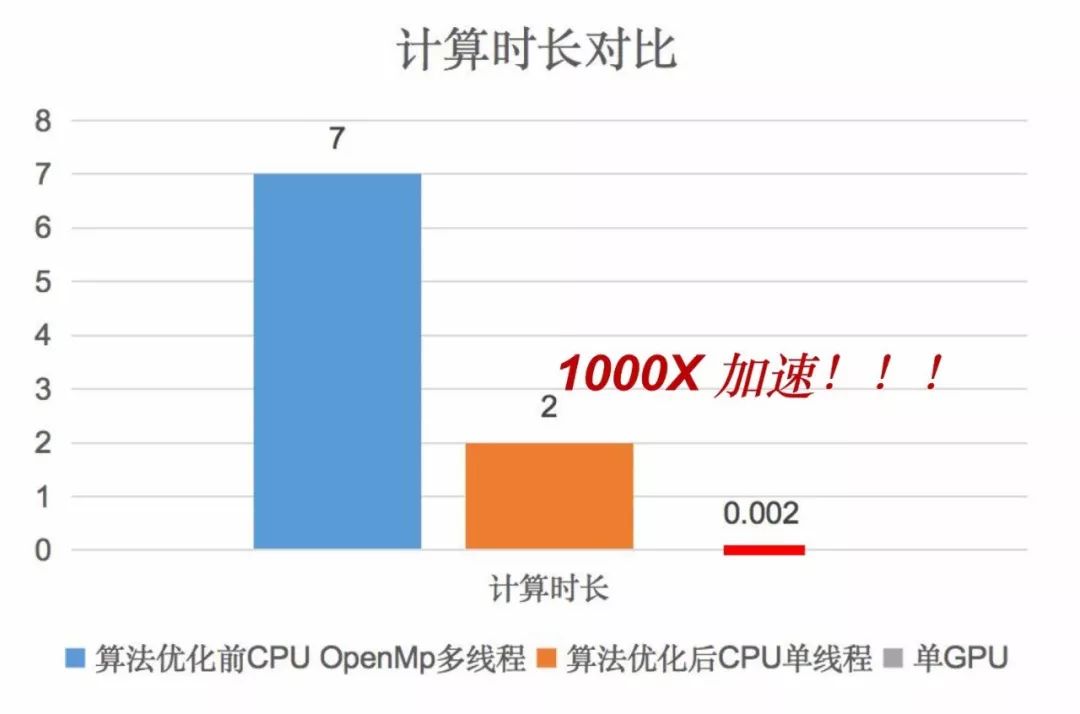
目前,FALLS已经实现了多GPU联合计算,并且实现了线性加速。如今,FALLS可以处理更大的数据量和更大的参数空间,相较于算法优化之前,计算时常实现了1000倍加速:
中科院高能物理研究所石京燕工程师也表示,中科院高能研究所在进行高能物理实验时,同样会面临海量的数据和复杂的计算过程,许多应用程序都对采用GPU加速计算提出了强烈需求。如今,通过在Juno实验中引入GPU加速计算;通过GPU加速计算进行交互式数据分析;基于深度学习进行事件重建,中科院高难研究所已经受益颇丰。
NVIDIA支持高校高性能计算教育
NVIDIA CUDA应用市场总监侯宇涛在10月19日的演讲中表示NVIDIA在关注GPU技术创新的同时,也致力于支持高校中的GPU教育。2018年8月20-24日,NVIDIA支持举办了国内首次OpenACC GPU Hackathon大赛,多支来自国内顶尖高校的队伍参赛。各团队基于NVIDIA V100 GPU对程序应用进行优化,实现了最大40倍速的计算速度提升。

此次HPC CHINA,NVIDIA的专家们还把NVIDIA深度学习学院(DLI)带到了年会现场,为学员现场揭秘深度学习技术及其应用,带领学员动手实验,展示如何通过在Caffe框架上的NVIDIA DIGITS和MINIST手写数据集,在深度学习工作流程中利用深度学习神经网络(DNN),尤其是卷积神经网络(CNN)解决图像分类问题。
NVIDIA GPU关注未来计算,持续创新
如今,具备更高计算能力的GPU技术为HPC应用的高速发展带来前所未有的强大计算引擎。随着HPC与AI的融合在更多领域的应用,计算单元需要同时具备超强的传统HPC计算力和深度学习计算力。最新的NVIDIA GPU系列,完美融合CUDA核心与Tensor核心,同时满足传统计算与AI计算的需求,并且配置一系列加速软件库,为应用开发提供最简洁优化的编程工具。NVIDIA GPU将不断向更高性能发起挑战,无论是硬件还是软件,都将保持着技术的高速创新。