
MegatronLM:借助GPU并行性 对有数十亿参数的语言模型进行训练
2019-08-21 21:25
 分享到微信
分享到微信
 分享到微博
分享到微博
更大规模的语言模型对于补全文章、问题回答和对话系统等NLP任务有着重要的作用。近期,训练最大规模的神经语言模型进行训练,已经成为了提高NLP应用的最佳方式。最近发表的两篇关于BERT和GPT-2的论文恰好说明了大规模语言建模的优势。这两篇论文都借助于算力和可用文本语料库的进步,在自然语言理解、建模和生成方面显著超越了当前的最有性能。为了训练这些模型,我们需要数百exaflops的算力和巧妙的内存管理,以减少内存占用。然而,对于那些参数超过10亿的大型模型,单个GPU的内存无法满足模型训练的参数需求,需要通过模型并行性,将参数分割至多GPU。虽然目前有几种模型并行性的方法,但都难于使用,要么是因为其有赖于自定义编译器,或是因其扩展性较差,再或者是其需要对优化器进行更改。
在此项工作中,我们通过对现有 PyTorch Transformer的实施进行一些针对性修改,实现了一种简单而有效的模型并行方式。在这一方法中,我们的代码是使用原生Python编写的,采用混合精度训练,并利用NCCL库在GPU之间进行通信。为了展示这一方法,我们基于512个GPU,采用8路模型并行和64路数据并行,训练出了一个具有83亿参数的Transformer语言模型,这也使其成为了有史以来最大规模的Transformer语言模型,该模型的规模是BERT的24倍,GPT-2的5.6倍。我们已在Github存储库中发布了该方法的实施代码。
我们的实验是基于NVIDIA的DGX SuperPOD进行的。如果不采用模型并行,我们可在单个V100 32GB GPU上训练一个具有12亿参数的基线模型,并在整个训练过程中维持39 TeraFLOPS的性能(该性能水平是DGX-2H服务器中单个GPU性能理论峰值的30%)。随后,我们将模型扩展至83亿参数,使用512个GPU,通过8路模型并行,结果在整体应用中实现了高达15.1 PetaFLOPS的持续性能,与单个GPU相比,其扩展效率达到76%。图1显示了详细的扩展结果。
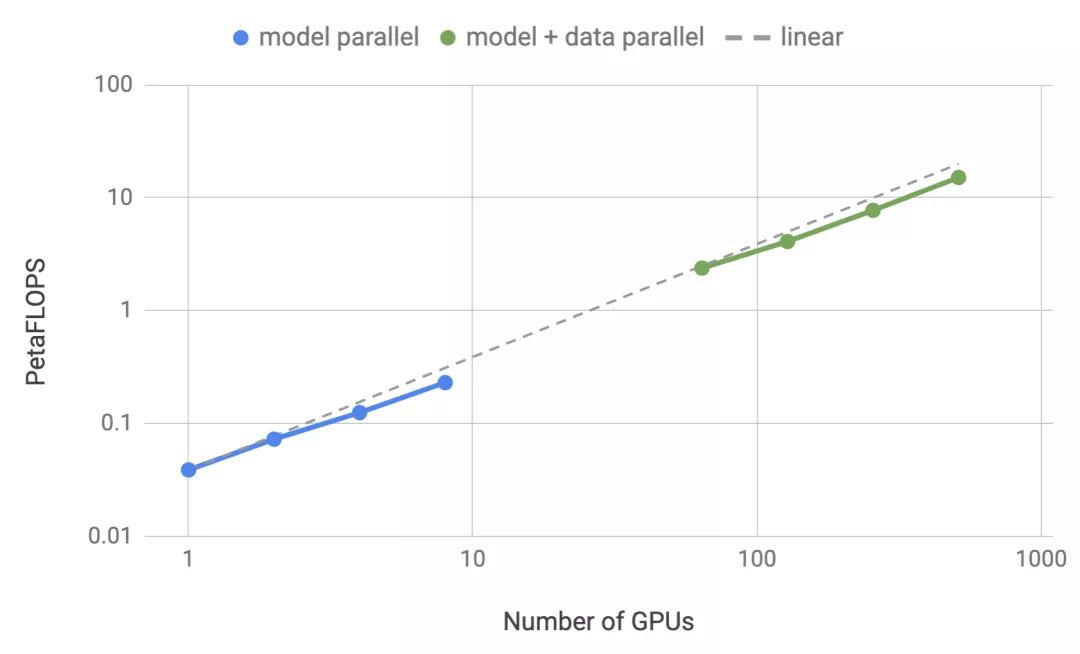
图1:模型(蓝色)和模型+数据(绿色)并行的性能随GPU数量变化的函数。模型并行(蓝色):高达8路模型并行弱扩展,每GPU约10亿参数(例如,2个GPU有20亿参数,4个GPU有40亿参数)。模型+数据并行(绿色):配置类似于模型并行,其中有64路数据并行。
多GPU并行
训练模型的典型范例是使用弱扩展(weak scaling)方法和分布式数据并行,借助多GPU实现训练批尺寸的扩展。这种方法能够让模型在规模更大的数据集上进行训练,但有一项限制,即所有参数必须运行于单个GPU之上。而模型并行训练可通过将模型划分至多个GPU来攻克这一限制。近期出现了几种通用型模型并行框架,如GPipe和Mesh-TensorFlow。GPipe能够在不同处理器上划分层组,而Mesh-TensorFlow可进行层内模型并行。我们的方法在概念上类似于Mesh-TensorFlow,我们关注层内并行并融合GEMM以减少同步。但我们只对现有Pytorch Transformer的实施进行了一些针对性修改,进而使用模型并行来训练大规模的Transformer。我们的方法很简单,模型并行无需任何新的编译器也无需重写代码,仅需插入几句简单的原语(图2中的f和g 运算符)就能完全实现。
我们利用Transformer网络的结构,通过添加几句同步原语来创建一个简单的模型并行实施。Transformer层包括一个自注意力模块(self attention block)和一个两层的多层感知器(MLP)。我们分别为这两个模块中引入模型并行性。我们首先详细介绍MLP模块,如图2a所示,其由两个GEMM组成,中间是GeLU非线性,然后是Dropout层。我们以列并行的方式划分第一个GEMM,让GeLU非线性能够独立地应用于GEMM每个分块的输出。模块中的第二个GEMM沿横向并行,无需任何通信就能直接获取GeLU层的输出。第二个GEMM的输出传递至dropout层之前,在GPU上被减少。这种方法能够将MLP模块中的两个GEMM跨GPU拆分,且仅在正推计算(g运算符)和逆推计算(f运算符)时分别需要一次全局归约(all-reduce)运算。
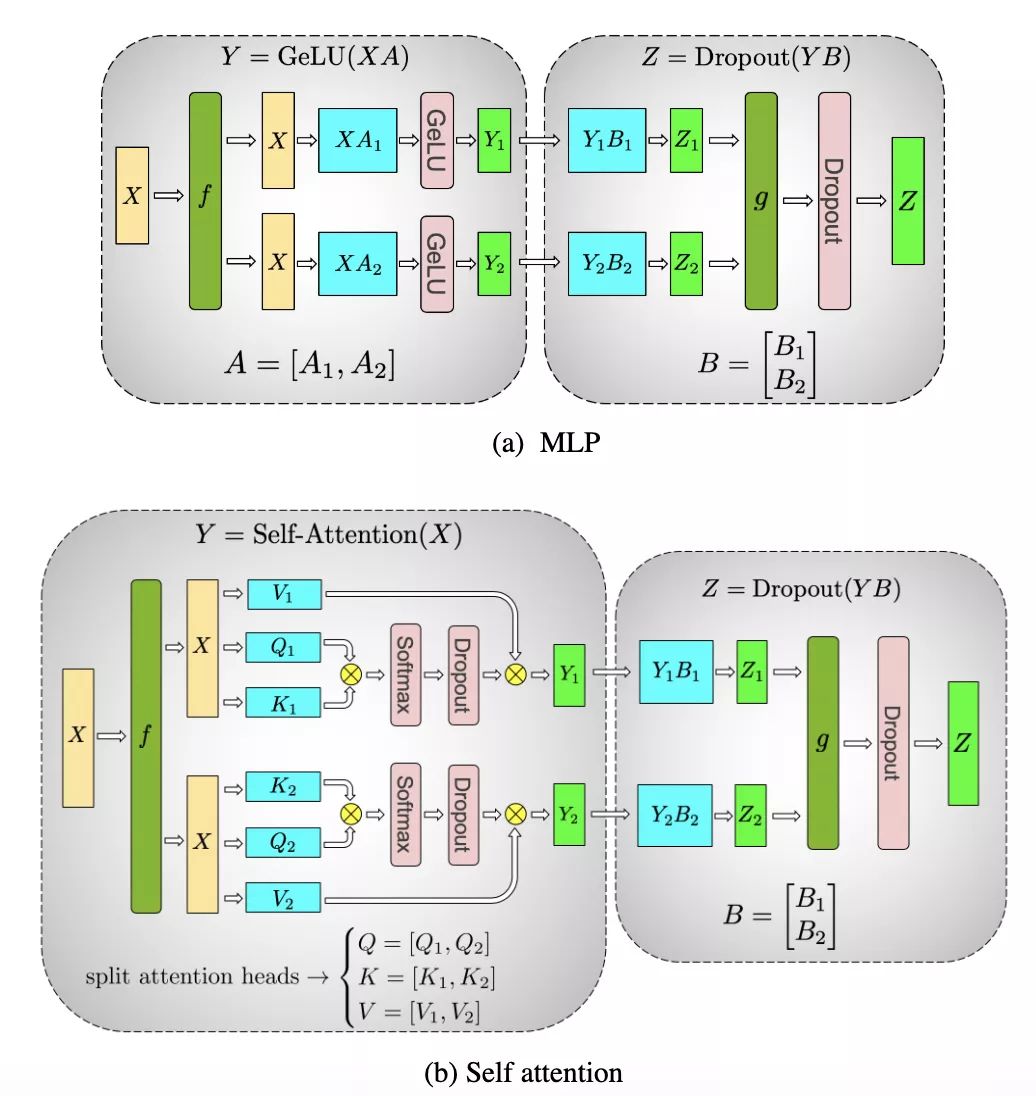
图2:(a):MLP和(b):Transformer自注意力模块。f和g是共轭的,f在正推计算中为恒等运算符,在逆推计算中为全局归约运算符,而g在正推计算中为全局归约运算符,在逆推计算中为恒等运算符。
如图2b所示,对于自注意力模块,我们利用了多头注意力运算(multihead attention operation)固有的并行性,将与密钥(K)、查询(Q)和值(V)相关的GEMM按列并行分区,使每个注意力头(attention head)相应的矩阵相乘能够基于一个GPU在本地完成。这使我们能够在GPU中按注意力头划分参数和工作负载,而无需通过即刻通信来完成自注意力。来自输出线性层的后续GEMM(自注意力后)沿横向并行,并直接接收并行注意力层的输出,而无需GPU之间的通信。对于MLP和自注意力层,这种方法都能融合两组GEMM,两者之间无需同步点,可实现更佳的扩展性能。这使我们只需在正推计算和逆推计算时进行两次全局归约(图3),就能在简单的Transformer层中执行所有的GEMM。最后,输出logit层也按照词汇表维度进行划分。为避免在词汇维度上出现大规模的聚类,我们将这一层与交叉熵损失相融合。
这一方法很容易实现,因其只需在正推计算和逆推计算中添加一些额外的全局归约运算。它无需编译器,且与诸如gPipe之类的方式中所推崇的管线模型并行呈正交关系。
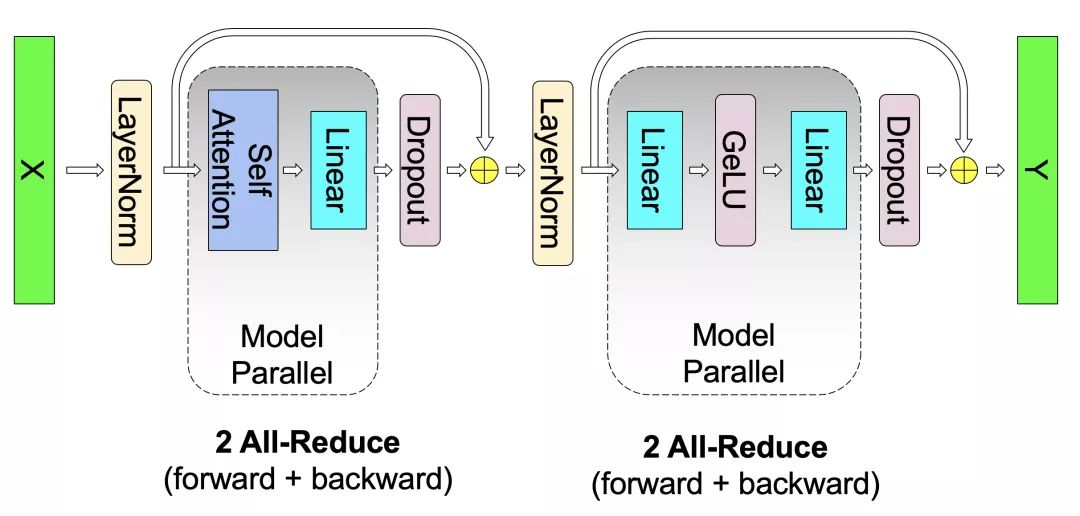
图3:GPT-2 transformer层的模型并行性。
性能
为了测试我们实现的计算性能,我们采用了GPT-2模型,表1中详细列出了四组参数。为确保自注意力层中的GEMM大小一致,每个注意力头的隐藏大小为恒定值96,而头和层的数量为变量,配置为10亿至80亿参数不等。10亿参数的配置适合于单个GPU,而80亿参数的模型需要8路模型并行(8个GPU)。原始词汇表大小为50,257,但为确保Logit层的高效GEMM,词汇表的大小以及模型并行GPU的数量都必须是128的倍数。鉴于我们研究到了多达8路模型并行,我们对词汇表进行了填充,使其可被128×8=1024整除。结果词汇量增加至51,200。我们研究了模型和模型+数据的并行扩展。对于模型并行扩展,所有配置使用固定的批尺寸——8。数据并行扩展对于许多最先进模型的训练都是必要的,这些模型通常使用更大的全局批尺寸。为此,对于模型+数据并行的情况,我们将所有实验的全局批尺寸固定为512,这相当于64路数据并行。
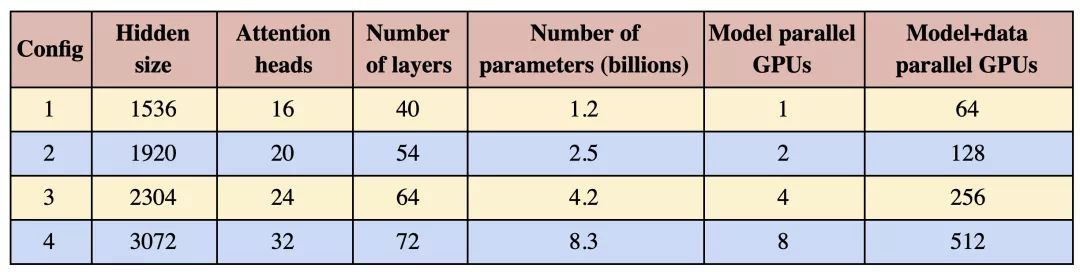
表1:用于扩展研究的参数
我们所有的实验都是在NVIDIA的DGX SuperPOD上进行的,我们使用了多达32台DGX-2H服务器(共512个Tesla V100 SXM3 32GB GPU)。该系统针对多节点深度学习应用进行了优化,服务器内部GPU间的带宽为300GB/秒,服务器间的互连带宽为100GB/秒。在这一部分,我们将展示模型并行和模型+数据并行情况下的模型参数弱扩展。弱扩展通常是通过扩展批尺寸来完成的,但这种方法无法解决不适用于单个GPU的大型模型训练问题,且对于较大的批尺寸,收敛性能也会下降。相反,这里我们使用弱扩展来对越来越大的模型进行训练,这是其他方式不可能做到的。所有扩展数字的基线是表1中基于单一GPU的第一个配置。
图4显示了模型和模型+数据并行性的扩展值。我们在这两种设置中都观察到了出色的扩展数字。例如,8路(8 GPU)模型并行、83亿参数的情况下,取得了77%的线性扩展。模型+数据并行需要在反向传播算法的步骤之后进一步进行梯度的通信,结果是扩展数略有下降。然而,即使对于基于512个GPU的最高配置(83亿参数),相较于本已很高的单GPU配置(12亿参数)基准,我们仍取得了74%的扩展。
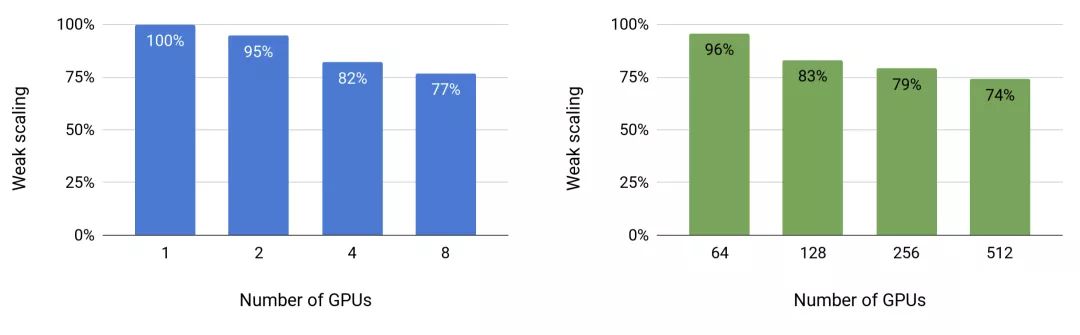
图4:模型(左)和模型+数据(右)并行随GPU数量的弱扩展。
最后,我们研究了注意力头对模型并行扩展的影响。为此,我们针对8路模型并行的83亿参数配置,将注意力头的数目设置为16到32个之间的变量。结果见表2。随着注意力头数量的增加,自注意力层内的一些GEMM变小,自注意力softmax中的元素数增加。这会导致扩展程度的轻度下降。在未来的研究中需要警惕这种超参数,以设计出能够在模型性能和模型效率间达到平衡的大规模Transformer模型。
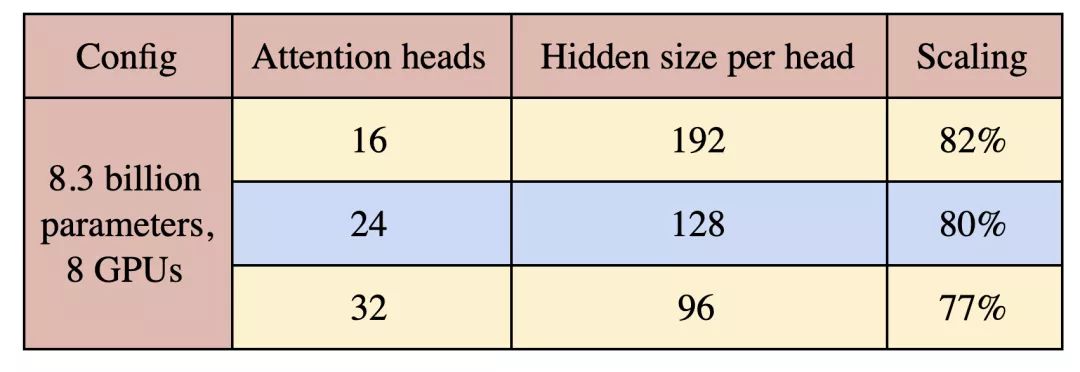
表2:注意力头数量对扩展的影响。
GPT-2训练
为了训练我们的GPT-2模型,我们创建了一个37GB的网络文本数据集(_WebText_ dataset),该数据集是从Reddit下载而来的,类似于原GPT-2相关论文中的网络文本数据集。为获得这一数据集,我们利用了公开可用的OpenWebText代码库。我们利用其预先下载的网址,执行额外的过滤以删除有误、短小或重复的网址。为清洗下载内容,我们使用了ftfy库,然后使用langdetect库删除了非英语内容。我们通过杰卡德(Jaccard)指数为0.9的局部敏感哈希(LSH)过滤,删除维基百科内容和重复内容,从而进一步对数据集进行了清洗。该数据集最终包含有810万个URL。为进行训练,我们将网络文本数据集按95:5的比例随机拆分,分别获得训练集和验证集。我们采用了四种模型大小:3.45亿、7.75亿、25亿和83亿。3.45亿和7.75亿参数模型与GPT-2所用的相似,使用了16个注意力头。25亿和830亿参数模型详见表1,除83亿参数的情况外,我们均使用了24个注意力头。
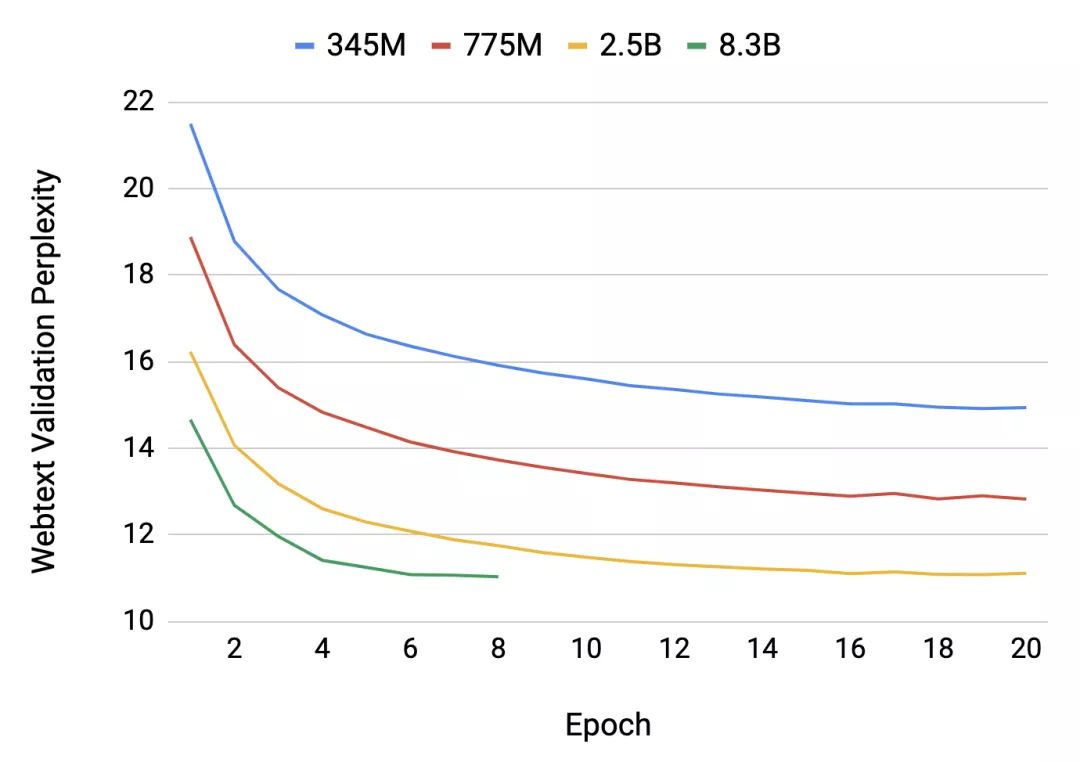
图5:训练子集的验证困惑度。83亿参数模型在我们的37GB数据集上过度拟合后,被提前中止。
图5显示了不同模型大小的验证困惑度随迭代次数变化的函数。在验证时,我们发现,较大规模的模型可实现较低的验证困惑度(perplexity)(图5)。我们最大的83亿参数语言模型的迭代次数设置为15,200——即在整个37GB语料库上进行训练所需的迭代次数,但我们发现其经过约6次训练迭代后开始出现过度拟合。我们认为,可通过使用更大规模的数据集来缓解这一情况,这些数据集与最近发表的论文中使用的数据集类似,如XLNet和RoBERTa。
GPT-2评估
为对大型语言模型的训练性能进行分析,我们基于wikitext-103数据集计算了困惑度,基于Lambada数据集计算完形填空式预测的准确度。正如预期,随模型大小的增长,维基文本困惑度降低,而Lambada准确度会提升(表3)。我们的25亿模型和83亿模型的维基文本困惑度分别为17.7和17.4,都超越了早前Transformer-xl模型创下的18.3的困惑度。我们的评估方法见下文,更多详情在我们的GitHub存储库中有提供。
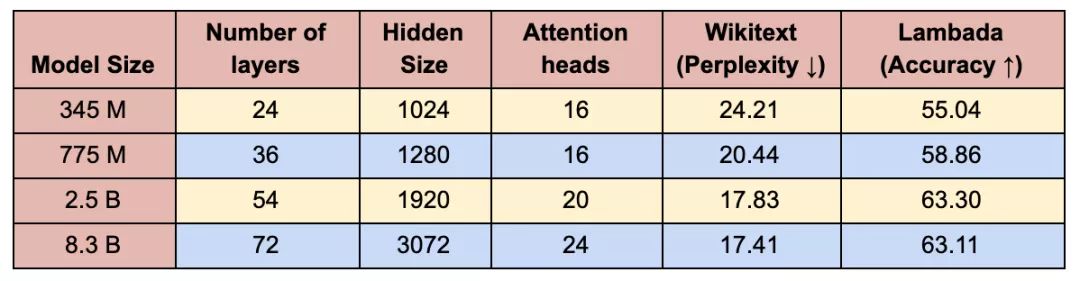
表3:维基文本困惑度(越低越好)和Lambada完形填空准确度(越高越好)的评估结果。维基文本的困惑度超越了此前Transformer-xl创下的最优结果(18.3)。
结论
在我们的研究中,我们基于现有深度学习硬件、软件和模型,构建了全球最大规模的Transformer语言模型,同时通过对现有PyTorch Transformer的实施进行少量针对性修改,实现了简单而高效的模型并行方法,成功突破了传统单个GPU训练的限制。我们采用8路模型并行,基于512个NVIDIA V100 GPU,高效地训练了一个83亿参数的语言模型(规模比BERT大24倍,比GPT-2大5.6倍),并在整个应用程序中实现了高达15.1 PetaFLOPS的持续性能。针对弱扩展,我们发现在相似训练时间内能够训练出规模越来越大的Transformer模型,且性能相较于规模较小的Transformer模型显然有所提升。然而,正如我们的研究所显示的,为了在不出现过度拟合的情况下正确训练大规模语言模型,NLP仍需要合适的数据集、问题和技术。我们将研究成果开源,以便社区能够复制我们的研究,并基于此进一步扩展。
在此项工作中,我们通过对现有 PyTorch Transformer的实施进行一些针对性修改,实现了一种简单而有效的模型并行方式。在这一方法中,我们的代码是使用原生Python编写的,采用混合精度训练,并利用NCCL库在GPU之间进行通信。为了展示这一方法,我们基于512个GPU,采用8路模型并行和64路数据并行,训练出了一个具有83亿参数的Transformer语言模型,这也使其成为了有史以来最大规模的Transformer语言模型,该模型的规模是BERT的24倍,GPT-2的5.6倍。我们已在Github存储库中发布了该方法的实施代码。
我们的实验是基于NVIDIA的DGX SuperPOD进行的。如果不采用模型并行,我们可在单个V100 32GB GPU上训练一个具有12亿参数的基线模型,并在整个训练过程中维持39 TeraFLOPS的性能(该性能水平是DGX-2H服务器中单个GPU性能理论峰值的30%)。随后,我们将模型扩展至83亿参数,使用512个GPU,通过8路模型并行,结果在整体应用中实现了高达15.1 PetaFLOPS的持续性能,与单个GPU相比,其扩展效率达到76%。图1显示了详细的扩展结果。
图1:模型(蓝色)和模型+数据(绿色)并行的性能随GPU数量变化的函数。模型并行(蓝色):高达8路模型并行弱扩展,每GPU约10亿参数(例如,2个GPU有20亿参数,4个GPU有40亿参数)。模型+数据并行(绿色):配置类似于模型并行,其中有64路数据并行。
多GPU并行
训练模型的典型范例是使用弱扩展(weak scaling)方法和分布式数据并行,借助多GPU实现训练批尺寸的扩展。这种方法能够让模型在规模更大的数据集上进行训练,但有一项限制,即所有参数必须运行于单个GPU之上。而模型并行训练可通过将模型划分至多个GPU来攻克这一限制。近期出现了几种通用型模型并行框架,如GPipe和Mesh-TensorFlow。GPipe能够在不同处理器上划分层组,而Mesh-TensorFlow可进行层内模型并行。我们的方法在概念上类似于Mesh-TensorFlow,我们关注层内并行并融合GEMM以减少同步。但我们只对现有Pytorch Transformer的实施进行了一些针对性修改,进而使用模型并行来训练大规模的Transformer。我们的方法很简单,模型并行无需任何新的编译器也无需重写代码,仅需插入几句简单的原语(图2中的f和g 运算符)就能完全实现。
我们利用Transformer网络的结构,通过添加几句同步原语来创建一个简单的模型并行实施。Transformer层包括一个自注意力模块(self attention block)和一个两层的多层感知器(MLP)。我们分别为这两个模块中引入模型并行性。我们首先详细介绍MLP模块,如图2a所示,其由两个GEMM组成,中间是GeLU非线性,然后是Dropout层。我们以列并行的方式划分第一个GEMM,让GeLU非线性能够独立地应用于GEMM每个分块的输出。模块中的第二个GEMM沿横向并行,无需任何通信就能直接获取GeLU层的输出。第二个GEMM的输出传递至dropout层之前,在GPU上被减少。这种方法能够将MLP模块中的两个GEMM跨GPU拆分,且仅在正推计算(g运算符)和逆推计算(f运算符)时分别需要一次全局归约(all-reduce)运算。
图2:(a):MLP和(b):Transformer自注意力模块。f和g是共轭的,f在正推计算中为恒等运算符,在逆推计算中为全局归约运算符,而g在正推计算中为全局归约运算符,在逆推计算中为恒等运算符。
如图2b所示,对于自注意力模块,我们利用了多头注意力运算(multihead attention operation)固有的并行性,将与密钥(K)、查询(Q)和值(V)相关的GEMM按列并行分区,使每个注意力头(attention head)相应的矩阵相乘能够基于一个GPU在本地完成。这使我们能够在GPU中按注意力头划分参数和工作负载,而无需通过即刻通信来完成自注意力。来自输出线性层的后续GEMM(自注意力后)沿横向并行,并直接接收并行注意力层的输出,而无需GPU之间的通信。对于MLP和自注意力层,这种方法都能融合两组GEMM,两者之间无需同步点,可实现更佳的扩展性能。这使我们只需在正推计算和逆推计算时进行两次全局归约(图3),就能在简单的Transformer层中执行所有的GEMM。最后,输出logit层也按照词汇表维度进行划分。为避免在词汇维度上出现大规模的聚类,我们将这一层与交叉熵损失相融合。
这一方法很容易实现,因其只需在正推计算和逆推计算中添加一些额外的全局归约运算。它无需编译器,且与诸如gPipe之类的方式中所推崇的管线模型并行呈正交关系。
图3:GPT-2 transformer层的模型并行性。
性能
为了测试我们实现的计算性能,我们采用了GPT-2模型,表1中详细列出了四组参数。为确保自注意力层中的GEMM大小一致,每个注意力头的隐藏大小为恒定值96,而头和层的数量为变量,配置为10亿至80亿参数不等。10亿参数的配置适合于单个GPU,而80亿参数的模型需要8路模型并行(8个GPU)。原始词汇表大小为50,257,但为确保Logit层的高效GEMM,词汇表的大小以及模型并行GPU的数量都必须是128的倍数。鉴于我们研究到了多达8路模型并行,我们对词汇表进行了填充,使其可被128×8=1024整除。结果词汇量增加至51,200。我们研究了模型和模型+数据的并行扩展。对于模型并行扩展,所有配置使用固定的批尺寸——8。数据并行扩展对于许多最先进模型的训练都是必要的,这些模型通常使用更大的全局批尺寸。为此,对于模型+数据并行的情况,我们将所有实验的全局批尺寸固定为512,这相当于64路数据并行。
表1:用于扩展研究的参数
我们所有的实验都是在NVIDIA的DGX SuperPOD上进行的,我们使用了多达32台DGX-2H服务器(共512个Tesla V100 SXM3 32GB GPU)。该系统针对多节点深度学习应用进行了优化,服务器内部GPU间的带宽为300GB/秒,服务器间的互连带宽为100GB/秒。在这一部分,我们将展示模型并行和模型+数据并行情况下的模型参数弱扩展。弱扩展通常是通过扩展批尺寸来完成的,但这种方法无法解决不适用于单个GPU的大型模型训练问题,且对于较大的批尺寸,收敛性能也会下降。相反,这里我们使用弱扩展来对越来越大的模型进行训练,这是其他方式不可能做到的。所有扩展数字的基线是表1中基于单一GPU的第一个配置。
图4显示了模型和模型+数据并行性的扩展值。我们在这两种设置中都观察到了出色的扩展数字。例如,8路(8 GPU)模型并行、83亿参数的情况下,取得了77%的线性扩展。模型+数据并行需要在反向传播算法的步骤之后进一步进行梯度的通信,结果是扩展数略有下降。然而,即使对于基于512个GPU的最高配置(83亿参数),相较于本已很高的单GPU配置(12亿参数)基准,我们仍取得了74%的扩展。
图4:模型(左)和模型+数据(右)并行随GPU数量的弱扩展。
最后,我们研究了注意力头对模型并行扩展的影响。为此,我们针对8路模型并行的83亿参数配置,将注意力头的数目设置为16到32个之间的变量。结果见表2。随着注意力头数量的增加,自注意力层内的一些GEMM变小,自注意力softmax中的元素数增加。这会导致扩展程度的轻度下降。在未来的研究中需要警惕这种超参数,以设计出能够在模型性能和模型效率间达到平衡的大规模Transformer模型。
表2:注意力头数量对扩展的影响。
GPT-2训练
为了训练我们的GPT-2模型,我们创建了一个37GB的网络文本数据集(_WebText_ dataset),该数据集是从Reddit下载而来的,类似于原GPT-2相关论文中的网络文本数据集。为获得这一数据集,我们利用了公开可用的OpenWebText代码库。我们利用其预先下载的网址,执行额外的过滤以删除有误、短小或重复的网址。为清洗下载内容,我们使用了ftfy库,然后使用langdetect库删除了非英语内容。我们通过杰卡德(Jaccard)指数为0.9的局部敏感哈希(LSH)过滤,删除维基百科内容和重复内容,从而进一步对数据集进行了清洗。该数据集最终包含有810万个URL。为进行训练,我们将网络文本数据集按95:5的比例随机拆分,分别获得训练集和验证集。我们采用了四种模型大小:3.45亿、7.75亿、25亿和83亿。3.45亿和7.75亿参数模型与GPT-2所用的相似,使用了16个注意力头。25亿和830亿参数模型详见表1,除83亿参数的情况外,我们均使用了24个注意力头。
图5:训练子集的验证困惑度。83亿参数模型在我们的37GB数据集上过度拟合后,被提前中止。
图5显示了不同模型大小的验证困惑度随迭代次数变化的函数。在验证时,我们发现,较大规模的模型可实现较低的验证困惑度(perplexity)(图5)。我们最大的83亿参数语言模型的迭代次数设置为15,200——即在整个37GB语料库上进行训练所需的迭代次数,但我们发现其经过约6次训练迭代后开始出现过度拟合。我们认为,可通过使用更大规模的数据集来缓解这一情况,这些数据集与最近发表的论文中使用的数据集类似,如XLNet和RoBERTa。
GPT-2评估
为对大型语言模型的训练性能进行分析,我们基于wikitext-103数据集计算了困惑度,基于Lambada数据集计算完形填空式预测的准确度。正如预期,随模型大小的增长,维基文本困惑度降低,而Lambada准确度会提升(表3)。我们的25亿模型和83亿模型的维基文本困惑度分别为17.7和17.4,都超越了早前Transformer-xl模型创下的18.3的困惑度。我们的评估方法见下文,更多详情在我们的GitHub存储库中有提供。
表3:维基文本困惑度(越低越好)和Lambada完形填空准确度(越高越好)的评估结果。维基文本的困惑度超越了此前Transformer-xl创下的最优结果(18.3)。
结论
在我们的研究中,我们基于现有深度学习硬件、软件和模型,构建了全球最大规模的Transformer语言模型,同时通过对现有PyTorch Transformer的实施进行少量针对性修改,实现了简单而高效的模型并行方法,成功突破了传统单个GPU训练的限制。我们采用8路模型并行,基于512个NVIDIA V100 GPU,高效地训练了一个83亿参数的语言模型(规模比BERT大24倍,比GPT-2大5.6倍),并在整个应用程序中实现了高达15.1 PetaFLOPS的持续性能。针对弱扩展,我们发现在相似训练时间内能够训练出规模越来越大的Transformer模型,且性能相较于规模较小的Transformer模型显然有所提升。然而,正如我们的研究所显示的,为了在不出现过度拟合的情况下正确训练大规模语言模型,NLP仍需要合适的数据集、问题和技术。我们将研究成果开源,以便社区能够复制我们的研究,并基于此进一步扩展。











