
富士通借助 Tesla V100 Tensor核心GPU创下ImageNet新纪录
2019-04-27 09:00
 分享到微信
分享到微信
 分享到微博
分享到微博
近期,来自富士通(Fujitsu)的研究员们宣布他们打破了ImageNet的训练速度记录——在74.7秒内达到75%的准确率。这比去年11月由索尼(Sony)创下的前纪录快了47秒。
团队取得这样的纪录,得益于日本东京大学(University of Tokyo)的 AI Bridging Cloud Infrastructure(ABCI)系统上的2,048块NVIDIA Tesla V100 GPU,以及MXNet深度学习架构。
ABCI系统是日本最快的超级计算机,在世界超级计算机榜单中也名列前10。该系统由超过4,300块NVLink互联的NVIDIA V100 GPU提供算力。Sony此前保持的纪录也是借助此系统实现的。
富士通(Fujitsu)在一篇文章中介绍:“基于此技术,富士通实验室(Fujitsu Laboratories)深耕HPC发展,公司现已开发出了新的技术,能够在保证训练准确率的同时拓展每块GPU的计算量。”
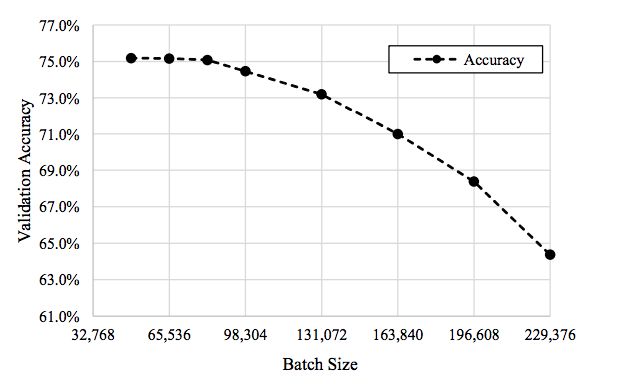
为了对使用大批量mini-batch训练深度神经网络(DNN)时发生的验证准确性进行补偿,团队“使用了相关技术,在不影响准确率的同时,增大了小批量的体量。”
研究人员介绍说:“众所周知,具有数据并行性的分布式深度学习是加速集群训练的有效方法。通过这种方法,在集群上运行的所有步骤都具有相同的DNN模型和权重。”
研究人员们同时也借助了Tensor核心的混合精度。

该DNN架构经过优化,基于ImageNet在74.7秒的时间内完成 ResNet-50训练,而且验证准确率高达75.08%。
团队还能够使用高达81,920个的大批量mini-batch,同时保持75.08%的准确率(如上表中第3个数据点所示)。
为实现这一里程碑式的成果,大量的NVIDIA技术被应用其中,其中就包括层级对应的适应率缩放(Layer-wise Adaptive Rate Scaling)。
该项工作目前已在ArXiv 和富士通博客上发表。











