阿里云GPU云服务器现已支持NVIDIA RAPIDS加速库
2019-05-25 09:00
 分享到微信
分享到微信
 分享到微博
分享到微博
阿里云GPU云服务器现已支持NVIDIA RAPIDS加速库,是国内第一家提供RAPIDS加速库服务的公有云厂商。
RAPIDS介绍
RAPIDS,全称Real-time Acceleration Platform for Integrated Data Science,是NVIDIA针对数据科学和机器学习推出的一套开源GPU加速库,基于CUDA-X AI打造,可加速数据准备、模型训练和图分析。
使用RAPIDS加速库可以实现从数据准备、模型训练到预测整个端到端流程得到GPU的加速支持,大大提升任务的执行效率,在模型精度方面实现突破的同时降低基础架构TCO。
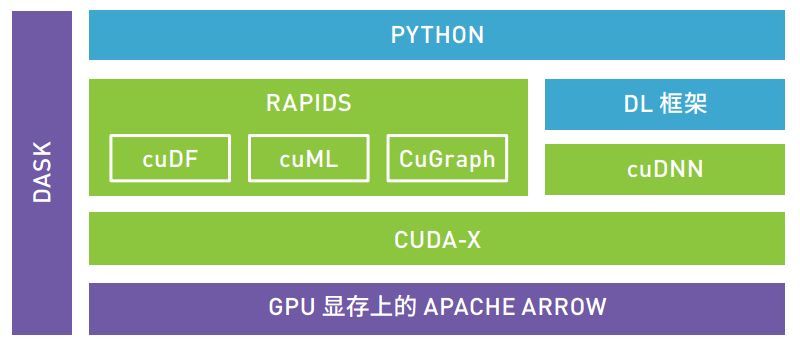
CUDNN已经成为GPU加速深度学习框架的标准加速库。RAPIDS(如下图)提供的cuDF、cuML和CuGraph则提供了对数据准备、机器学习算法以及图分析的GPU加速库。
RAPIDS支持轻量级大数据框架DASK,使得任务可以获得多GPU、多节点的GPU加速支持。
RAPIDS以数据准备为起点,引入新型 GPU 数据框架 (cuDF),进而能实现并行化数据加载和数据操作,充分利用 NVIDIA GPU 上的大型高带宽显存。 cuDF 为数据科学家提供了简单易用且基于 Python 的工具集,可以替换其已十分熟悉的pandas 工具集。数据科学家无需从头学习 NVIDIA CUDA 技术,只需要对现有代码做出极少量更改,便能够大幅提速数据准备,使其不再受限于 CPU 或 CPU 与内存之间的输入输出。
RAPIDS 还引入了不断发展壮大的全新 GPU 加速 ML 算法(cuML) 库,当中包括 XGBoost 等时下热门算法,以及 Kalman、K-means、 KNN、 DBScan、 PCA、 TSVD、 OLS 线性回归、Kalman Filtering 等算法。 ML 算法可产生大量数据传输,至今仍难以实现并行化。随着 GPU 加速的 ML 和 NVIDIA NVLink™ 以及NVSwitch 架构陆续应用于服务器系统,模型训练现可轻松分布于多个 GPU 和多个节点(系统)之间,几乎不会产生延迟,且能避过 CPU 与内存之间的输入输出瓶颈。
支持实例
阿里云目前支持RAPIDS的实例规格有GN6i(Tesla T4)、GN6v(Tesla V100)、GN5(Tesla P100)和GN5i(Tesla P4)。
如何在GPU实例上使用RAPIDS加速库
关于如何在阿里云GPU实例上基于NGC环境使用RAPIDS加速库,请参考文档:《在GPU实例上使用RAPIDS加速机器学习任务》(点击“阅读原文”,阅读文档)。
按照上述文档,可以运行一个单机的GPU加速的数据预处理+训练的XGBoost Demo,并对比GPU与CPU的训练时间。
用户也可以通过选择更多的数据量和GPU个数来验证多GPU的支持。
后续阿里云还会继续提供更多的RAPIDS加速的最佳实践。
性能
按照上述文档示例,在GN6i实例(Tesla T4)上,使用GPU加速的XGBoost训练任务,可以获得20倍以上的加速:












