PAI自动混合精度训练—Tensor核心在阿里PAI平台落地应用实践
2019-05-16 09:00
 分享到微信
分享到微信
 分享到微博
分享到微博
本文转载自知乎。
作者:阿里巴巴PAI团队孙敏敏、王梦娣、杨军
本案例中,阿里巴巴PAI团队为了使PAI用户无需经过繁琐的模型改写即可实现混合精度训练、充分利用Tesla V100 GPU Tensor核心的强大计算力缩短模型训练时间、提升模型迭代速度,阿里巴巴团队在PAI平台上开发了自动混合精度训练Feature,Feature已在PAI平台上线开放对内使用,显著节省了用户使用Tensor核心硬件加速单元的负担,并且以通用性的方式获得了显著的作业训练性能加速,比较充分地释放出底层Tesla V100的计算潜力,且不影响模型的收敛性。
PAI(Platform Artificial Intelligence) 作为阿里巴巴集团的机器学习平台,一直致力于底层引擎技术、编译优化及在离线预测优化的技术创新,同时通过PAI Studio、PAI DSW 、EAS、算法市场等相关生态产品,打造完整、丰富的生态体系,将AI技术更好的赋能于集团内外各类用户。
PAI平台管控了阿里巴巴集团内外大量的CPU、GPU、RDMA网卡等硬件资源,在确保单个作业执行性能的同时,如何确保这些硬件资源的整体使用效率,是平台侧重点关注的问题。因为确保通过平台层面的技术创新,让阿里 “用更少的资源,跑得更快,支持更多业务同时迭代” 是中台技术赋能业务创新的典型体现。
NVIDIA Tesla V100 GPU是NVIDIA于2017年推出的新一代GPU,采用Volta架构,引入了针对混合精度计算的Tensor核心,硬件层面显著提升了峰值计算能力,相较于深度学习常用的浮点32位的计算,理论最高加速比可以达到8X。
NVIDIA Tesla V100 GPU推出之后,阿里巴巴集团率先采用了Tesla V100。然而,一款新硬件的推出对上层软件栈也提出了新的挑战和要求,想要充分发挥新的底层硬件的性能效率,就需要软件层进行大量的适配工作(包括训练性能以及模型训练方式的适配,以确保获得理想的time-to-accuracy的加速效果)。
为了使PAI用户无需经过繁琐的模型改写即可实现混合精度训练、充分利用NVIDIA V100 GPU Tensor核心的强大计算力缩短模型训练时间、提升模型迭代速度,阿里团队在PAI平台上开发了自动混合精度训练Feature。
该Feature已在PAI平台上线开放对内使用,显著节省了用户使用Tensor核心硬件加速单元的负担,并且以通用性的方式获得了显著的作业训练性能加速,比较充分地释放出底层新硬件的计算潜力,同时在近期向社区提交了相关的Pull Request因为有效发挥混合精度加速新硬件的效率确实存在不少陷阱和问题。
作为基础设施平台方,阿里巴巴PAI团队希望能够从平台层面将这些问题尽可能以透明、通用的方式进行解决,从而解决上层用户的使用负担,让用户透明地享受到Telsa V100新GPU的加速红利。
已经正常使用PAI自动混合精度训练的用户,均能够在无需改动一行代码的前提下获得显著的训练加速,且不影响模型的收敛性。
1. 混合精度训练简介
混合精度训练是指在训练过程中在不同的计算中使用不同的数值精度,从而充分挖掘GPU硬件上每一个晶体管的极致性能,目前在PAI上支持的混合精度训练主要是指FP16和FP32两个数值精度。在标准Tensorflow训练任务中,variable及tensor的表示精度目前均默认为FP32的,那么为什么要引入FP16的数值精度呢?
对于神经网络训练过程而言,影响速度的两个关键因素是,计算和访存(这实际上也是由冯诺依曼体系结构的本质决定的):
-
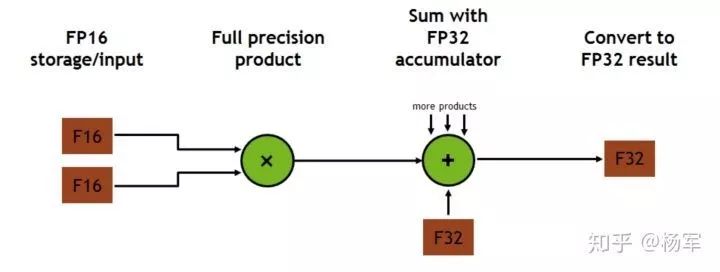
从计算而言,NVIDIA在2017年推出了Volta架构,其中重要的模块即为Tensor核心(如下图),在Tensor核心的加速下,V100在混合精度下的吞吐量比在FP32下有8X的加速。Tensor核心主要对matrix-multiply-and-accumulate类计算进行了加速。基于Tensor核心阿里巴巴PAI团队可以对 MatMul、 Convolution等计算原语进行加速,而二者恰好是神经网络中计算量较大的op。
-
从访存而言,若Tensor的数值精度由FP32变为FP16,那么也可以得到理论上2X的访存加速。 因此阿里巴巴PAI团队引入了混合精度对神经网络的训练进行加速。
Volta V100 Tensor核心计算
2. Motivation
易用性是PAI平台在追求高性能、高效率的同时同样重视的另一个关键目标,因为其用户,即AI Developer,希望专注于模型和算法本身,不希望被各种复杂的性能优化问题分散精力,这要求其性能优化能够作为turn-key solution,尽可能对用户透明,避免对用户模型代码的入侵。混合精度训练加速优化同样如此。
目前一般的混合精度训练方法需要用户自己将模型代码修改为混合精度版本,因此会对模型代码产生较深的入侵,特别是复杂模型,增加了用户负担。这个过程包含多个步骤:
1) 将计算部分转换为FP16;
2) 将不支持FP16和不应使用FP16计算的算子再逐一转换回FP32;
3) Variable使用FP32存储,这可以通过将Variable定义为FP32,在计算时再cast乘FP16,即tf.cast(tf.get_variable(..., dtype=tf.float32), tf.float16)来做到。
但是这种做法存在很多局限。首先,很多variable的定义被封装在TF API中,如LSTMCell的weights和bias,模型代码层面不可见,这种情况则需要通过custom_getter实现;此外,有些情况下混合精度的训练过程还需要加入Loss Scaling策略才能确保收敛。整个过程易出错,一旦出现收敛性问题就比较难调试,而且难以区分转换出错还是模型本身不适合混合精度训练。
此外,阿里团队还发现手工混合精度转换存在一些性能问题,比如:实测大部分模型手工简单转换为混合精度模型之后的加速远低于预期,甚至出现大幅性能下降(如果是对混合精度训练细节非常了解的优化专家来进行手工精细调优,确实会取得更好的性能,但要求所有的算法工程师都具备相应的能力其实是一个不合理的要求)。
分析下来,发现根源问题在于模型代码层面的转换是粗粒度的。部分算子其实天然不适合使用FP16,例如 Embedding Lookup,还有部分算子的FP16版本性能较差,例如 BiasAddGrad。模型代码层面的粗粒度转换很难对转换过程进行精细控制从而将这些FP16性能很差的算子排除在外。
当然,模型代码层面也可以做到细粒度的转换,但是这样做一方面增加模型代码的入侵深度,使得人工工作量随着模型复杂度急剧上升;另外这么做也需要一定的性能调优经验,且避免不了多次迭代尝试,这会给AI Developer带来很大的额外负担;最后还有一个克服不了的问题,那就是在模型代码层面无法触及反向计算图,所以像前面提到的BiasAddGrad算子在模型代码层面就控制不了。
基于以上两点原因,阿里团队在计算图优化环节实现了自动的、精细的混合精度转换,对用户完全透明,用户跟正常训练FP32模型一样,无需修改模型代码;在计算图优化环节,通过相应的性能优化避免混合精度转换过程中伴生的性能不利因素,其实现的Loss Scaling策略对用户更友好、适用面更广泛。
3. 自动混合精度化的实现
阿里巴巴PAI团队的自动混合精度转换在PAI平台深度定制的Tensorflow框架PAI-TensorFlow的计算图优化引擎中实现。虽然相比于模型代码层面的转换,计算图层面的转换能够做到自动化、对用户透明,但是计算图层面的转换也有其缺点、有着相应的制约和性能开销,本节主要介绍阿里巴巴PAI团队在计算图混合精度转换的同时如何克服这些约束、降低性能开销。
3.1 White-list
为了避免将不支持FP16、不适合使用FP16、FP16性能较差的算子转换为FP16导致运行错误或者性能大幅下降,阿里巴巴PAI团队维护了一个white-list,只有在这个white-list中的算子才有可能被转换为FP16。这个white-list的更新,一方面,会基于一些heuristic的规则来进行指定,此外,阿里巴巴PAI团队也会引入一个在线反馈tuning的机制,来对算子的FP16-friendliness数据进行自动采集,以期尽可能减少人力负担。
3.2 Cost Model
但不是white-list中的所有算子都应该转换为FP16,计算图中每个节点需不需要转换,除了和这个计算节点本身的算子类型有关,还和这个节点周围其他节点等因素紧密相关,所以需要一个Cost Model来预测每个节点转换为FP16之后对整体性能的影响,从而作出转换与否的判断。
举个例子,前面提到的embedding_lookup算子,虽然也支持FP16,但是通过阿里巴巴PAI团队的cost model可以轻易地自动将计算图中的 embedding_lookup节点排除在外。如下图所示,上侧是原始计算图中的 embedding_lookup节点,其访存开销是 2*N*D*4Bytes,其中系数2表示一次读和一次写,4Bytes是因为读写都是FP32数据;下侧则是将 embedding_lookup节点转换为FP16之后的示意图,转换后的访存开销则变为2*N*D*2+V*D*4+V*D*2Bytes,其中第一项表示embedding_lookup本身的读写量减半,而增加的后两项则是因为在embedding_lookup之前需要将embedding variable转换为FP16. 通常情况下词表大小V远远大于batch size N, 因此转换后的总的访存开销远远大于转换前,通过cost model就能够判断出这个转换不应该发生。
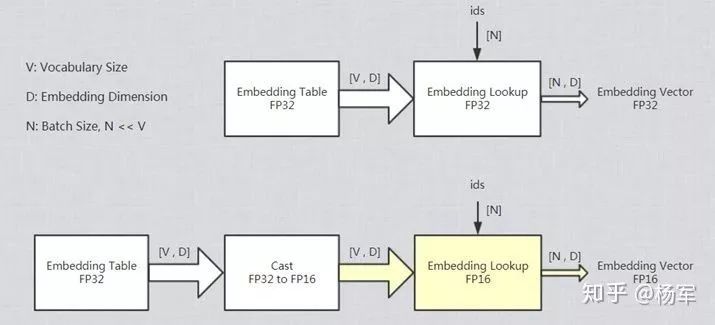
3.3 FP16 Propagation
在计算图层面看模型的视角和在TF代码层面看模型的视角不太一样,在计算图层面看到的只是一个个计算节点和他们之间的连接关系,缺失了更宏观的结构信息,比如哪些是前向计算、哪些是后向计算、以及哪些是Optimizer的计算(虽然在某种程度上可以通过节点的名字来判断,但这依赖于计算图构造过程中的命名规则,更多是为了debug目的,不足以作为本质的判断依据,一方面因为用户有自定义命名的自由度;另一方面某些计算图优化Pass在添加计算节点时则不受计算图构造的命名规则的约束)。
这个局限性给计算图层面的自动混合精度转换造成了一定的障碍,因为PAI团队并不希望Optimizer本身的计算也被转换为FP16,原因是因为部分模型需要loss scaling才能防止gradients underflow ,Loss Scaling包含Scaling与Unscaling两个步骤,降低在两个动作之间的梯度值转换为FP16后Underflow的风险,而Optimizer本身的计算位于Unscaling之后,如果Optimizer本身的计算也被转换为FP16,那么就存在很大的underflow风险。正如前面所说,在计算图层面并不能完全确认哪些计算是optimizer本身的。
为了解决这个问题,阿里巴巴PAI团队提出并实现了FP16 Propagation方案。基本思想是,计算图中节点的FP16转换顺序并不是随意的,而是从MatMul/Conv2D节点开始向下游传播,那么只要在gradient unscaling的位置(使团队自己添加的Mul节点)做一个特殊标记,FP16的传播遇到这个标记便停止,从而保证gradient unscaling之后的节点都不会被转换为FP16。
3.4 Cast Elimination & Cast Fusion
计算图层面的自动细粒度还存在一个不可避免的问题是会产生大量的Cast转换节点,因为将每个节点转换为FP16必然会在输入端插入FP32转FP16的Cast, 输出端插入FP16转FP32的Cast,这些Cast会带来很大的额外开销,因此阿里巴巴PAI团队通过Cast Elimination 和 Cast Fusion两个方法来降低所引入的这部分开销。
Cast Elimination就是将两个连续的相反的Cast节点互相抵消,如下图所示。这种情况在FP16转换后大量存在,如果没有Cast Elimination,这些Cast节点带来的额外开销大部分情况下足以抵消混合精度训练所带来的性能收益。
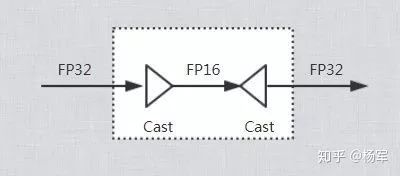
虽然Cast Elimination已经能够消除大部分Cast节点,但并不能完全消除,对于剩余的Cast节点可以进一步通过Cast Fusion使其和前后的节点融合,从而避免带来额外的访存开销和Kernel Launch开销。
4. 自动Loss Scaling的实现
4.1 loss scaling介绍

SSD训练过程中的gradients分布
由于数值精度的下降,模型的训练过程可能会有一定的精度下降或者不收敛情况。由于FP16的表示范围有限,数值较小的gradients可能会出现underflow,导致数值直接被截断为0,如上图,图中所示为一个经典的SSD图像检测模型在训练过程中的gradients分布图,图中红线以左都会因为underflow的问题在FP16下变为0,而同时观察到FP16有很大一部分表征能力并没有用到,因此可以将gradients放大一定的倍数进行表达。对于此问题可以通过loss scaling策略进行解决,即在loss上乘以一个scaling factor,在gradients进行apply之前进行unscale即可。
下图所示即为loss scaling的计算流程示意图,在loss位置,将loss乘以scaling factor,进行后向计算,在得到FP32 gradients进行unscaling操作,保证gradients数值的准确性。其中对于scaling factor,阿里巴巴PAI团队实际是引入了额外的超参数,若其值较大,则在后向计算中,gradients可能出现overflow的情况,若其值较小,则依然不能很好的解决FP16下underflow的问题。对于它的控制,NVIDIA提出了auto scaling策略,其主要想法是,在不溢出的情况下,可以使用一个尽量大的scaling factor。
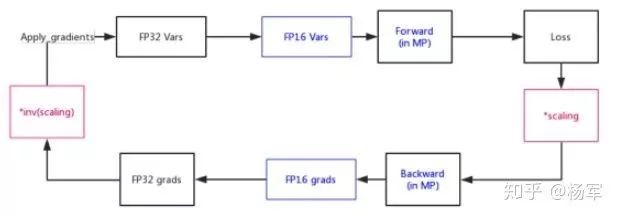
Loss scaling实现流程框架图
4.2 Loss scaling的自动实现
对于loss scaling策略,用户可以用类似
grads = [grad / scale for grad in tf.gradients(loss * scale, params)]
的方式进行手动实现,但手动实现存在以下两方面的劣势:
-
用户的code可能有多种方式实现梯度的计算,例如可能直接调用tf.gradients() ,也可能调用optimizer.compute_gradients(),甚至也可能是调用optimizer.minimize()进行计算。在不同的策略下,用户需要找到gradients的实际计算位置,并对其进行loss scaling计算操作;
-
若使用constant loss scaling,则用户需要根据经验指定scaling factor, 则有可能引入了额外的调参过程;而用户若希望使用auto loss scaling的策略,则用户需要理解auto loss scaling的完整策略,并手动实现,这个过程使得用户需要对code进行一个不小的改动量,带来的overhead是比较大的,且存在一定的出错概率。
目前社区tensorflow和NVIDIA所给的示例中给出了另外一种实现方式,即对用户的optimizer进行一层混合精度的wrapper封装,并重新实现了compute_gradients()/apply_gradients()/minimize()等函数。但这种实现方式存在以下问题:
-
用户code对于gradients的计算,不一定是通过调用optimizer.compute_gradients()实现的,也可能是直接调用tf.gradients(),在这种情况下用户就需要改动自己的code以适用于混合精度的loss scaling训练策略,这对用户的overhead是比较大的;
-
wrapper封装方式无法解耦与其他optimizer wrapper的耦合依赖;例如,在分布式训练时,用户一般会用分布式optimizer对于标准optimizer进行一层封装,例如opt = tf.train.SyncReplicasOptimizer(opt),此时用户可能存在不知道封装哪一个optimizer的困惑,并且目前社区的code是没有对于分布式训练wrapper与混合精度训练wrapper进行解耦的,社区目前的版本与tf.train.SyncReplicasOptimizer耦合使用时会出现死锁情况;
-
更细节地,wrapper方式不能实现对于colocate_gradients_with_ops等一些device placement控制功能的支持。
因此,为了解放用户,阿里巴巴PAI团队采取了另外一种实现方式,即对tf.gradients()进行了decorator,在这种方式下,可以支持optimizer.compute_gradients()/optimizer.minimize()/tf.gradients()任一方式下的梯度计算,同时是对梯度反向计算的原子操作tf.gradients()进行了decorator,因此它与其他的optimizer wrapper不存在耦合情况。细节地,用户在使用混合精度时,若希望启动loss scaling只需要将optimizer相关的部分都放在with gradients.mixed_precision_scope下即可,例如如下所示。

4.3 模型收敛性验证
对于混合精度训练,阿里巴巴PAI团队基于不同类型的model进行了收敛性验证。实验结果可以验证部分model在混合精度训练下也可保持与FP32训练结果相当的模型精度,部分model出现了精度下降或训练不收敛的情况,但均可通过loss scaling的策略恢复模型精度,保证其与FP32下一致的模型精度。
4.3.1 Classification CNNs
对于分类CNN网络,阿里巴巴PAI团队基于ResNet50在ImageNet上进行了收敛性分析,下图所示为训练过程的test accuracy曲线,对比实验包括:
-
FP32 baseline;
-
混合精度训练(MP)+no loss scaling;
-
混合精度训练(MP)+constant scaling (scaling factor=64);
-
混合精度训练(MP)+auto scaling。 由对比可见,即使不加loss scaling策略,混合精度训练的精度与FP32下基本无差别。
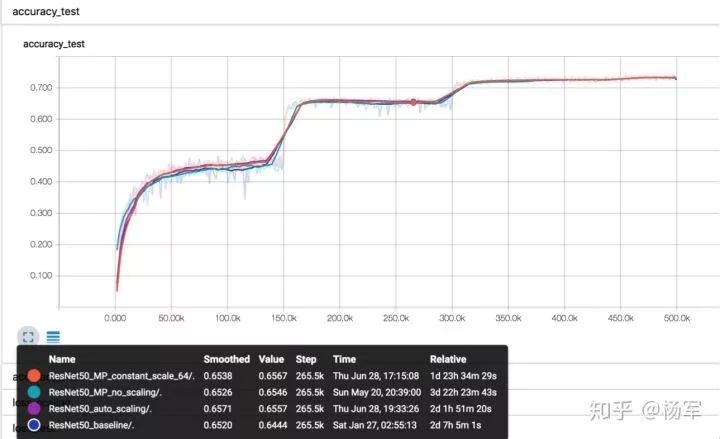
ResNet50训练曲线对比
4.3.2 Detection CNNs
对于detection CNNs,阿里巴巴PAI团队在Faster RCNN和SSD上进行了收敛性验证:
-
Faster RCNN on PASCAL VOC2007
对于此model,在混合精度训练下,不加loss scaling的情况下,mAP有1.65的drop,但在constant scaling及auto scaling的策略下,此精度均可recover,且精度略高于FP32情况下的模型精度

-
SSD on PASCAL VOC2007+2012
SSD模型在混合精度训练情况下,不加loss scaling时出现了不收敛的情况,但在constant scaling及auto scaling情况下,其收敛精度均可与FP32 baseline相当。

4.3.3 NMT
对于NMT任务,阿里巴巴PAI团队使用了small NMT模型在WMT German-English任务上进行了混合精度训练,在auto scaling策略下,其所得BLEU值与FP32情况下训练结果相当。
4.3.4 GAN
对于GAN的收敛性验证,阿里巴巴PAI团队在基于公开model Prograssive GAN (PGAN)和阿里巴巴PAI内部推进的一个AI字体生成业务model进行了验证。
下图所示从左至右分别为两个模型在FP32、FP16(no loss scaling)以及FP16(auto scaling)情况下的生成图片,其主观结果无明显差异。


4.3.5 Wide & Deep Learning
对于搜索、推荐、广告领域常用的WDL模型,阿里巴巴PAI团队基于Tensor flow官方案例 进行了收敛性验证,实验结果如下。即使在不加loss scaling的情况下,团队观察到混合精度的训练结果与FP32也是相当的。

5. 线下性能评测
5.1 Language Model
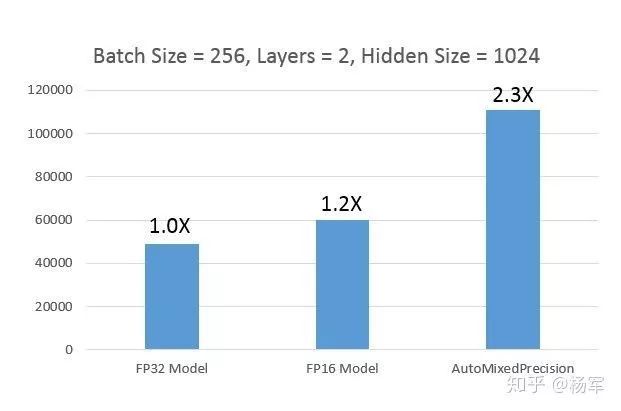
首先选取了Tensorflow官方的Language Model进行评测:
评测模型提供了FP16训练的Option --use_fp16,这属于前面提到的模型代码层面的手工转换,正好可以和PAI自动混合精度训练做一些性能对比。
收敛性:无需Loss Scaling, AutoMixedPrecision收敛性与FP32训练无差异。
性能:如下图所示(单位words/sec),PAI自动混合进度训练的性能明显超过手工转换的FP16模型的性能,相对于V100 FP32性能基准,加速达到2.3X。
5.2 NMT Transformer
同时阿里巴巴PAI团队针对阿里达摩院机器翻译团队的In-house Production Model也进行了混合精度的加速效果验证。
收敛性:加上Loss Scaling, AutoMixedPrecision收敛性与FP32训练无差异
性能:如下图所示(单位step/sec), 这个模型有两种配置,hidden size = 512的配置相对于V100 FP32加速比为1.6X, hidden size = 1024的配置加速比为2.1X。

6. 线上性能对比
首先要说明的一点是,虽然已经有多个业务的多个模型在线上使用PAI混合精度训练,但并不是每个模型的每个配置阿里巴巴PAI团队都能拿到和非混合精度训练的性能对比,因为用户在顺利使用PAI混合精度训练后并没有再使用非混合精度训练的需求,有时候用户跑非混合精度训练纯粹是为了帮阿里巴巴PAI团队做性能对比,团队也不愿意过多地浪费用户宝贵的时间和集群计算资源来做性能对比。所以下面会比较细节地列举两个项目各自其中一个模型的性能对比,再给出一些代表性的模型性能对比。
6.1 高德某导航类相关项目
该项目是PAI自动混合精度训练的第一个用户,该项目自研的模型,既包括多个卷积层也包括多个全连接层。
该项目最新开发的模型使用PAI混合精度训练,模型收敛性没有收到影响。
使用PAI混合精度训练和V100非混合精度训练的性能对比,如下表所示(单位sec/step)
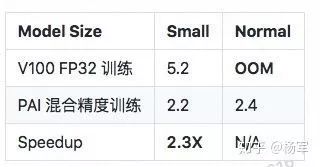
对于小尺寸模型,在相同的V100 GPU上,PAI混合精度训练相比于非混合精度训练加速2.3X。
对于正常尺寸的模型,如果不用混合精度训练,在V100 GPU上则因为OOM根本无法训练,这也体现了PAI混合精度训练除了性能上的加速,也能降低显存的消耗。
6.2 速卖通 (AliExpess)某商品数据挖掘项目
AliExpess商品数据挖掘项目是PAI自动混合精度训练的第二个用户,使用PAI混合精度训练,同样对模型收敛性没有任何影响。
和前面的高德导航类项目新开发的模型直接在V100集群使用PAI混合精度训练不同的是,该项目的模型在使用PAI混合精度训练之前已经在使用P100集群训练,切换到PAI混合精度训练后获得了非常显著的加速,一方面是V100 GPU相对于P100 GPU的性能提升,另一方面是在V100 GPU上PAI混合精度训练带来的性能提升。训练时间对比如下图所示
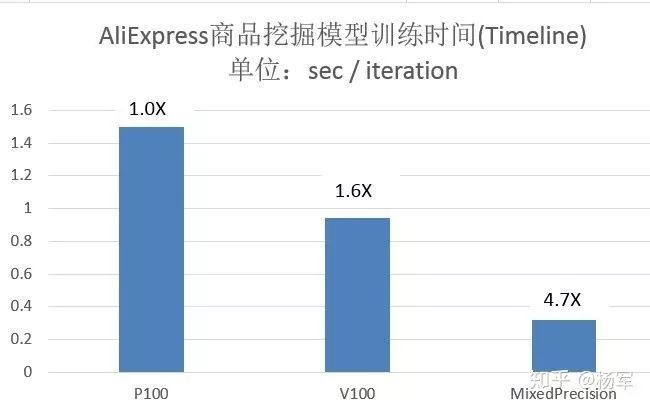
对于小尺寸模型,在相同的V100 GPU上,PAI混合精度训练相比于非混合精度训练加速2.3X。
对于正常尺寸的模型,如果不用混合精度训练,在V100 GPU上则因为OOM根本无法训练,这也体现了PAI混合精度训练除了性能上的加速,也能降低显存的消耗。
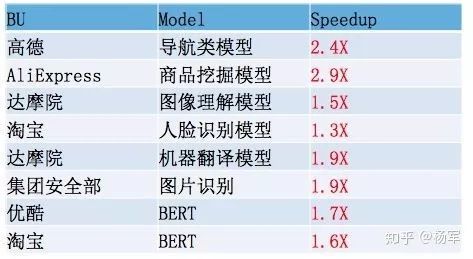
6.3 PAI自动混合精度代表性模型加速示例
因为自动混合精度功能在设计上就充分考虑到了通用性及透明性,所以业务多样性支持得比较出色,下面展示的部分数据包括PAI平台对内业务CNN、Transformer、BERT以及FCN占模型结构主体的不同模型,业务场景横跨了NLP、图像、电商数据挖掘、高德交通导航等。
*本文图片来自于原作者











