
开发者实测:NVIDIA Jetson AGX Xavier开发套件使用初体验
2019-04-02 09:00
 分享到微信
分享到微信
 分享到微博
分享到微博
本文作者为西安电子科技大学朱虎明,现任西安电子科技大学副教授,其研究领域包含深度学习、模式识别、GPU计算。朱虎明分别于2001年、2004年和2010年获得西安电子科技大学电子工程本科学位及通信与信息系统研究生、博士学位。作者已授权NVIDIA发布本文章。
背景
如果把信息科技产业划分为三个时代:PC 时代、移动互联网时代和人工智能(AI)时代。目前,我们处于移动互联网时代的末期和下一个时代的早期,即以深度神经网络算法为核心的AI 时代。
深度神经网络模拟人类大脑的工作原理,是近年来机器学习领域最令人瞩目的方向。2006年深度学习泰斗Geoffrey Hinton提出了基于“逐层训练”和“精调”的两阶段策略,解决了深度神经网络中参数训练的难题后,学术界和工业界对深度神经网络的研究热情高涨,并逐渐在语音识别、图像识别、自然语言处理等领域取得突破性进展。2012年深度卷积神经网络在ImageNet图像分类竞赛中取得了世界第一,标志着端到端的方法取得了超越手工设计特征的传统方法。此后深度神经网络的发展进入了快车道。2016年基于深度学习的AlphaGo打败了围棋世界冠军李世石,同度举办的人工智能知名学术会议CVPR、NIPS、AAAI和ICLR上深度神经网络的主题占主导地位。2017年以深度神经网络为核心的DeepStack算法在德州扑克游戏中击败了人类职业玩家。2018年,人工智能的芯片已经应用于云计算和移动终端中。目前,深度神经网络的研究向着更深更广的方向前进,一方面深度神经网络的理论研究越来越深入,另外一方面如何开发基于深度神经网络的智能系统成为关键,特别是如何将人工智能技术与边缘计算结合起来。
云计算作为一种计算模式已经渗透进我们日常生活之中,但是有很多很多应用场合,由于网络不可用、网络带宽不足和网络延迟大等原因使得基于云计算的模式不能满足需求,这就是边缘计算覆盖的领域。中国边缘计算产业联盟(Edge Computing Consortium,ECC)定义的边缘计算是指在靠近物或数据源头的网络边缘侧,融合网络、计算、存储、应用核心能力的开放平台,就近提供边缘智能服务,满足业务在敏捷联接、实时业务、数据优化和应用智能等方面的关键需求。由此可见要想在边缘计算中部署人工智能应用,必须要有高性能低功耗的超级计算平台。NVIDIA最近发布的Jetson AGX Xavier就是在边缘计算场景中部署人工智能应用的一个利器。
嵌入式超级计算机Jetson AGX Xavier可以用于自主物流车、机器人、无人机和其他智能机器,从而加速制造、物流、零售、服务、农业、医疗等产业的智能化发展,为智能城市的发展做出贡献。
02
Xavier的硬件架构特性
Xavier是最新一代NVIDIA业界领先的嵌入式Linux高性能计算机,主要包括一个8核NVIDIA Carmel ARMv8.2 64位CPU,由8个流多处理器组成的512核Volta架构的GPU,支持并行计算语言CUDA 10,支持多精度计算,FP16计算能力为11 TFLOPS(每秒浮点运算次数),INT8为22 TOPS。64个Tensor核心, 16GB 256位LPDDR4x,双深度学习加速器 (DLA)引擎,NVIDIA视觉加速器引擎,高清视频编解码器,Xavier集成的Volta GPU,具体参数如表1所示,GPU架构如图1所示。
用户可根据应用需要配置Xavier工作在10W、15W和30W的模式,凭借多种工作模式,Jetson AGX Xavier的能效比其前身Jetson TX2高出10倍以上,性能超过20倍。
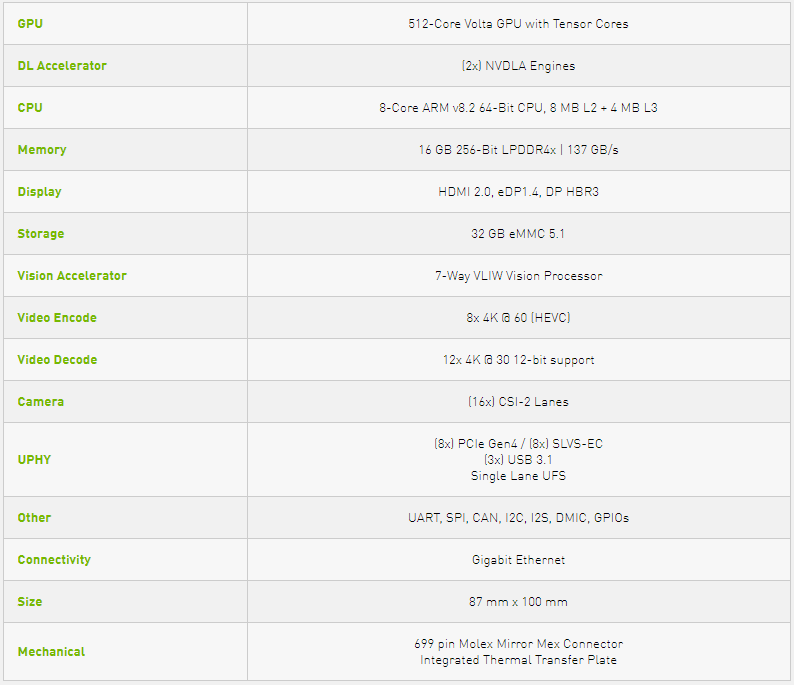
表1 Xavier主要参数
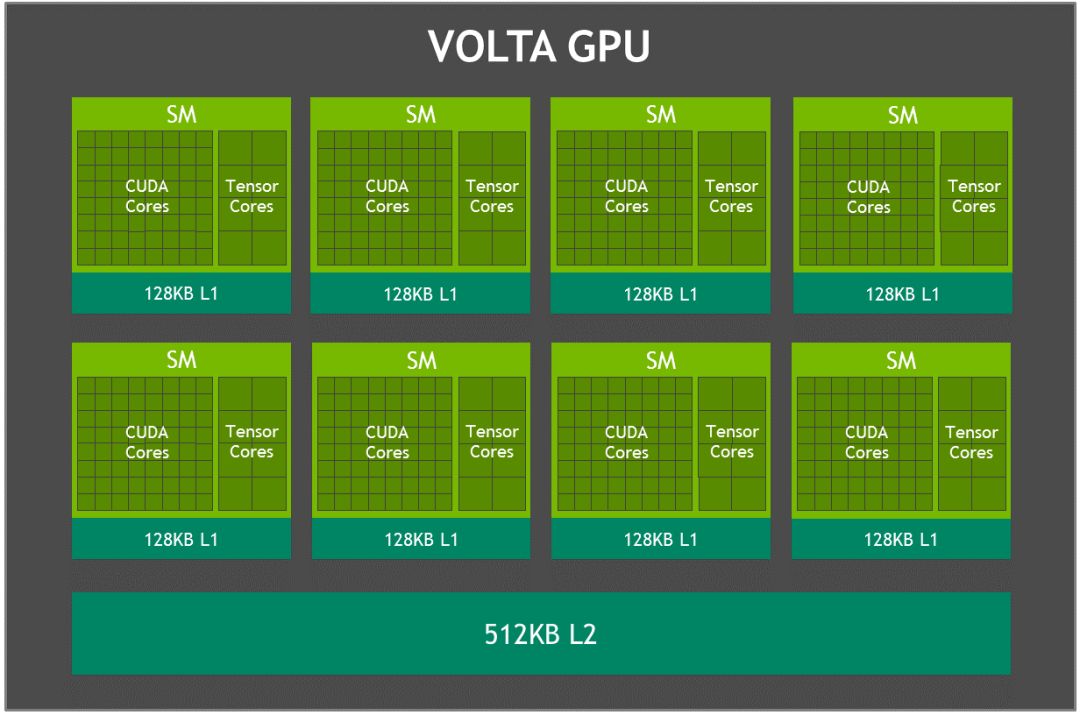
图1 Xavier Volta GPU架构
Xavier内置的 Tensor Core支持混合精度计算。可以完成以下的融合乘法加法:执行两个4*4 FP16矩阵相乘,将结果添加到4*4 FP16或FP32矩阵中,最终输出新的4*4 FP16或FP32矩阵。深度神经网络最耗时的卷积操作在训练和推理时都可以转成上述的矩阵乘法,Tensor Core极大的提高了计算效率。
Xavier具有两个NVIDIA 深度学习加速器(DLA)引擎,可以进行高性能的深度神经网络推理计算,其结构如图2所示。这每个DLA具有高达5 TOPS INT8或2.5 TFLOPS FP16计算性能,功耗仅为0.5-1.5W。DLA支持加速CNN层,例如卷积、反卷积、激活函数、最小/最大/平均池化、局部响应归一化和全连接层。
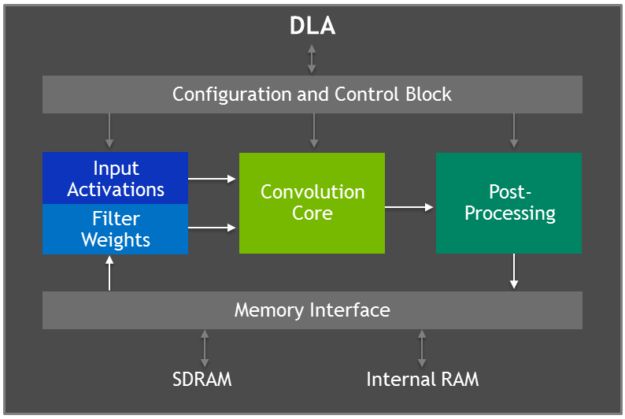
图2 深度学习加速器(DLA)架构
03
Xavier的软件平台
Xavier主要用于边缘计算的深度神经网络推理,其支持Caffe、Tensorflow、PyTorch等多种深度学习框架导出的模型。为进一步提高计算效率,还可以使用TensorRT对训练好的模型利用计算图优化、算子融合、量化等方法精简进行优化。Xavier通过TensorRT使开发者能充分的利用GPU中的Tensor core和DLA单元等计算模块。
04
Xavier推理性能评测
4.1 测试平台参数
为了测试Xavier的推理性能,我们使用目标检测算法分别在GeForce 840M、Jetson TX2和Xavier三个计算平台上进行测试。Jetson TX2工作在默认的MAXP_CORE_ARM模式,Xavier工作在默认的MODE_15W模式。三个计算平台的关键技术参数如表2所述,测试实验场景如图3所示。

表2 三个测试平台参数
图3 测试环境实景
(作者朱虎明实景拍摄,授权NVIDIA发布)
4.2 Faster R-CNN目标检测算法介绍
我们利用Faster R-CNN目标检测算法测试Xavier的推理性能。Faster R-CNN是Fast R-CNN和RPN(区域候选网络)的融合。RPN使用全卷积网络(FCN,fully-convolutional network)可以针对生成检测候选框的任务端到端地训练,能够同时预测出目标的边界和分数。这里使用基于VGG16的Faster R-CNN网络,其算法主要流程如4所示。Faster R-CNN卷积网络的结构主要包括:①13个conv层:kernel_size=3,pad=1,stride=1;②13个relu层:激活函数,不改变图片大小;③4个pooling层:kernel_size=2,stride=2;pooling层会让输出图片是输入图片的1/2;
4.3 测试结果介绍
测试时在TensorRT给出的示例代码sampleFasterR-CNN.cpp上找到推理函数,在其前后添加时间函数gettimeofday(),计算其推理时间。在不同的硬件平台上重复实验五次取时间平均值,结果如表3所示。
从实验结果表可以看出来,Xavier在使用TensorRT进行推理时,性能相比Jetson TX2提升了不少。需要注意的是Xavier使用的TensorRT版本相比TX2版本在软件架构上有很大的变化,特别是结构性更好。另外,由于时间的原因,我们没有测试DLA加速的效果。

表3 不同平台目标检测计算性能对比
05
总结
Xavier平台配备了完整的 AI 开发软件包NVIDIA JetPack SDK,包括最新版本的 CUDA、cuDNN 和 TensorRT等软件。这些开发软件使用起来非常方便,再加上Xavier 平台强大的推理计算能力,Xavier必将在制造、物流、零售、服务等边缘计算人工智能应用场景大放异彩。











