
NVIDIA超级公开课第12讲实录:医疗领域的深度学习
2018-09-11 12:18
 分享到微信
分享到微信
 分享到微博
分享到微博
以下是罗晟老师的主讲实录和提纲,共计13549字,预计14分钟读完。
大纲:
1.深度学习在医疗领域发展现状及常见应用场景
2.深度学习加速药物研发
3.深度学习加速基因研究
4.深度学习加速疾病诊断
5.医疗领域英伟达解决方案平台
主讲实录
罗晟:大家好,我叫罗晟,来自NVIDIA的深度学习解决方案架构师。今天很高兴能够在这里和大家分享医疗领域的深度学习应用,以及NVIDIA为医疗领域提供的解决方案平台,希望今天的分享能给大家带来帮助,也希望本次分享可以起到抛砖引玉的作用,让各位能够为整个行业带来新的创意,帮助大家用AI和GPU加速医疗行业的应用,为医疗领域提供新的方案。
在正式开讲之前,我想先给大家分享一个关于医疗领域创业的故事,为什么要用深度学习做医疗呢?大家知道现在深度学习很火,但是并不是火什么,我们就应该做什么,我们用深度学习来做医疗,肯定有其背景原因,有它带来的好处。在美国,有这样一个深度学习应用的案例,就是一个工程师,带着自己的父亲去看病,医生诊断出他父亲是癌症的第四期,也就是尾期,医生直接让他父亲进行化疗,之后大概经历了一到两个礼拜的化疗期,化疗之后,他父亲也掉了很多头发,人也觉得很辛苦。后来,他正好有一个朋友是医生,然后这个医生就为他爸爸做了第二次诊断,才发现上一个医生的诊断是错误的,其实他父亲只是在癌症的第一期。而癌症第一期不需要化疗,只通过药物就可以控制住。这位AI工程师就下定决心,要用AI技术来改善医疗领域,去解决由于医生的一些失误导致的医疗问题,这也是为什么我们要用AI做医疗的原因。

对NVIDIA不熟悉的朋友,可能对NVIDIA的印象还停留在GPU的计算卡和游戏卡上,但其实从2007年NVIDIA提出CUDA用于作为GPU计算的编程语言开始,我们已经在医疗行业耕耘了十年。可以应用的领域除了计算之外,还有可视化,而现在,我们还可以用来做深度学习。有宝宝的小伙伴应该知道,做婴儿三维超声波检查的时候,看到婴儿的那些图像,其实从2009年西门子的超声波机器已经用NVIDIA的GPU来做渲染方面的工作。
不仅如此,GE的CT扫描仪,也用到了GPU的技术,实现实时重建,直接把传感器的数据映射到图像上,这样带来的好处就是我们能直接去看到相关的图像,不仅如此,还能够对图像进行优化,我们可以使用更低剂量的x射线来实现相同质量的图像,从而减少诊断对健康带来的损害。
2012年,由于AlexNet的出现,深度学习证明了其在计算机视觉方面具有非常好的性能,也就是从这个时候开始医疗行业的各个领域也逐渐开始利用深度学习,也扩展了GPU的应用领域,比如在2013年,GPU驱动的深度学习的方法,在病理切片上检测并统计有丝分裂数,击败了其他所有的技术,这个统计数据是癌症的早期指标,换句话说,用GPU之后我们能够获得更好的准确性,同时也能降低漏诊的风险。
随着技术的发展,DL在医学影像领域获得过很多的成功,其实我们现在听到的大多数关于深度学习的应用都是在医疗领域。比如2014年,我们做的大脑肿瘤分析,2016年肺癌检测,这些都是在医疗领域的应用。而这些深度学习应用不仅是在商业应用、搜索里面取得的成功,而且在一些数据科学竞赛方面也取得了很好的成绩,并且两次打败其他队伍,成功完成了任务。
这两次成功,一次是基于心脏MI成像自动注射量的计算,可以用来衡量心脏的运行状态。另一次是关于CT扫描中肺癌的早期检测。这些都是DL在医学影像领域取得的成功。不仅如此,最让我兴奋的是在去年NVIDIA首次参加北美放射学会,吸引了大概五万名的与会者,大部分都是放射科医师,其中有四十八个初创公司都在用深度学习或者机器学习进行医学成像。而且其中百分之九十的公司都在使用GPU。在本次会议上,DL相关文章的数量,相比往年增加了十倍,NVIDIA在会议期间进行了为期5天的DLI(NVIDIA深度学习学院)培训,平均每天培训200人。
2018年NVIDIA发起了Project Clara,它的名称来源于红十字会的创立人,他的名字就是Clara 。我们希望通过Clara项目 ,帮助医疗行业利用NVIDIA GPU技术,改善人们的生活。
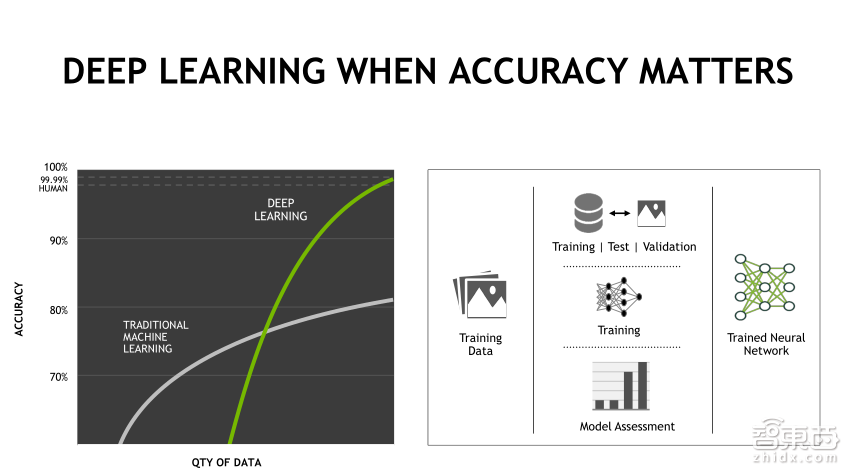
大家知道,2012年AlexNet网络出来之后,首先在ImageNet上取得了非常好的结果,战胜了传统记忆学习的方法,当时AlexNet性能有10%的提升。而在往年,每年都是1%的性能提升。这样飞跃的性能提升确实能够丰富我们的应用种类,比如人脸识别,自然语言处理。同时对于一些商业应用来说,能够获得更精准的推荐,比如大家平时使用的今日头条新闻推荐,系统会根据你自身的的喜好为你推荐相应的内容,这就是基于深度学习来做的。对于深度学习来说,这样的精确意味着什么呢?
对于其他的行业来说,准确度确实很重要,但也不是很关键,因为推荐错了,并不会对生命造成影响,但在医疗行业则不然,用更好的方法不仅仅只是提高准确度。比如在药物发现领域,可以缩短药物的整个研发周期,在医疗诊断领域,可以在最早期进行医疗诊断,减少病人的痛苦。而此时能够提高的准确度,不只是数字上的十个百分点,在医疗领域,可能会为每一个人带来更好的生活,为整个社会带来更好的未来。
整个深度学习的流程,就如右边这张图所示,通过训练数据和深度学习网络训练生成一个深度学习的模型,之后对模型进行评估,再用一些新的数据来确认,验证以及测试,从而得知模型是否准确,而且通过这样一个模型,可以解决医疗领域的很多问题,至于怎么解决、未来怎么做,我会在后面详细给大家介绍。

深度学习在医疗领域的应用不仅为个人带来了新的变化,同时也为社会和人类未来的发展带来了新的动力。对整个行业和研究社区来说也有一些新的变化。我们也可以看到一些趋势,也是我们所谓的深度学习动量,上图左边展示的是SPIE、ISBI、MICCAI这三个顶级会议医学影像图片领域使用深度学习文章数量这几年的比例变化,从2014年不到5%,到2017年,尤其是在ISBI上面,其比例已经超过20%,从而证明了深度学习确实能够为研究社区带来新的帮助,也确实成为了一个有用的工具。
研究机构利用AI带来了新的应用和思路,解决了之前在医疗方面遇到的问题,现在有一百零六个初创公司,他们也在推动整个医疗行业去使用AI。他们可能在各个领域,比如药物发现、医学图像以及相关的自然语言处理等,丰富了整个生态环境,也希望今天的分享能够给大家带来一些新的思路,去打造在中国医疗行业的人工智能生态环境,帮助改善在未来医疗服务。

说起医疗行业的深度学习,不得不考虑对医生和病人来说,他们在哪些方面可以用到深度学习。比如在看病的时候,医生怎么为病人制定治疗方案。一方面,可以了解病人的基因,因为很多疾病其实是基因的变异引起的,如果知道有基因变异的情况,就可以在最开始做一些人为干预和早期的治疗。在看病时,医生会去看病人以前的健康记录,了解病人以前的健康状况,从而帮助医生诊断病情。
对患者来说,要去了解病人之间的差异,以及为什么会患病。比如有些人会患一种疾病,另外一些人不会患这种病,这样就可以用深度学习做一些基础的研究,加速药物的发现过程,因为这些疾病只出现在了一些病人身上,通过筛选,以达到更好的治疗效果。
其实医生在工作期间不仅仅是为病人看病,也要去了解一些文献和法规、写论文,因为他们也需要去了解医疗行业最新的出版物,才能知道一些新的治疗方式。今年关于癌症的出版物有93393篇,到目前为止已经有350万篇论文,此时我们可以用深度学习从论文里挖掘出跟我们相关的信息,帮助医生更好的了解到一些最新的研究动态,尤其是在临床方面,可以了解到最新的论文和研究状态,以及一些最新的治疗方法,从而提出新的治疗方案,来研究能不能通过新的方法,或者一些验证过的方法去帮助病人获得更好的治疗效果。
医生和病人之间是应该有互动的,医生每天会看非常多的病人,他们看病的时候,其实也是一个经验学习的过程,医生可能从A病人的治疗过程得到这样一个经验,从B病人的治疗过程中得到另一个经验。对于医生来说,他们看到了这么多东西,并不是每一个都会记住,因为人都会慢慢忘记以前的一些事情,因此我们可以用深度学习去记录以前所有的经验,并通过以前医生在看病时候的情况,去收集这些病人的信息,从而辅助医生在下一次判断中做出最优的决定,帮助医生更好把以前所看过病的经验利用起来,而不是会因为太过忙碌忘记了以前的经验去翻医疗记录。
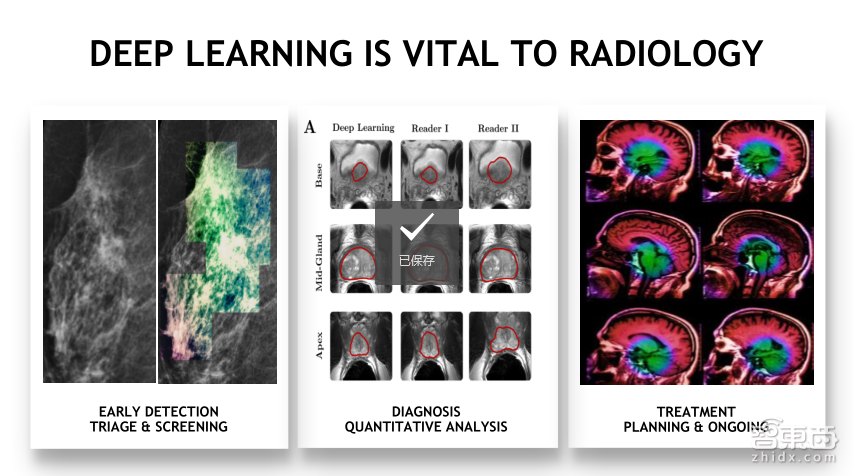
现在来看下深度学习在医疗领域的应用有哪些。首先在放射科领域,我们希望通过早期的筛选和检测,减轻病人因为放疗承受的痛苦。在国外,大家每年都会做体检,希望在早期了解自己的身体状况,把疾病治疗提到早期阶段,降低整个社会的负担,同时也减轻个人痛苦。Zebra就在做这样的工作,通过深度学习提高筛选的准确率,降低检测整体的误报率,获得更好的早期判断结果。早期诊断只是告诉我们有和无的问题,下一步要解决的问题就是有多少,如上图中间照片所展示,当诊断出肿瘤之后需要去判断肿瘤所在的部位、大小等情况,即是定量的分析,这种方式,也可以用深度学习来获得更准确的结果,并且可以降低病人治疗时的痛苦。
另外一个让人非常兴奋的领域是精准医学,上图右边展示的是脑部扫描图片。在面对某些脑癌的时候,医生有能力去判断需要什么药物,问题是医生不可能在大脑上打个洞,然后去切片,再去分析,现在通过脑部的MI扫描方式,用深度学习神经网络去判断和预测患者肿瘤突变的概率,目前准确度也超过了90%,使得医生可以用精准的药物去帮助病人做治疗,减轻他们的痛苦。

第二个领域是深度学习在诊所里的应用,三星和通用的扫描仪已经在使用深度学习来优化整个工作流,提高准确性。比如婴儿三维超声波检测时,可以冻结一些图像进行测量。第二个ARTERYS公司,也是首批通过FDA认证的公司。通过与GE合作,把他们的工具带到了心脏病专家那边,进行所有相关的一些检测,能够进一步提高护理质量。最后一个是PATHAI与飞利浦合作,也是第一个由FDA批准的扫描仪诊断,通过将病理图片与热力图结合,帮助病理学家分析肿瘤的情况,进一步降低病理学家诊断错误率,大约降低50%,使得病理学家在看图的时候能够更加方便。

第三个是深度学习在药物发现方面的应用,第一个是deep genomics公司。他的成立要追溯到2002年,当时Brendan Frey的妻子怀孕了,在做检查的时候发现孩子有遗传缺陷,虽然只是可能,但是他们不得不终止妊娠。Brendan Frey是计算机工程的教授,所以他开始尝试把深度学习和医疗结合到一起,要解决的痛点是人群中的DNA的变异数,突变概率大于1的SNP(单核苷酸多态性)有三百万个左右,要完全的挨个调查SNP和疾病的关联非常困难,因此要建立一个数学模型导入全部的健康基因组序列和SNP序列,对模型进行训练,让模型能够学习到健康的RNA(核糖核酸)的裁剪模式,然后用分子生物学的方法验证模型,并加以校验,同时用病理数据,判断模型输出的准确性,从而理解有害基因和基因突变病理之间关系,再做一些初步筛选,把有害基因和基因突变病理关系建立起来。
第二个是做分子系统的研究,在做新药研究时遇到很多挑战,HCS是指在保持细胞结构和功能完整性的前提下,同时检测被筛样品对细胞形态、生长、分化、迁移、凋亡、代谢途径及信号转导各个环节的影响, 在单一实验中获取大量与基因、蛋白及其他细胞成分相关的信息, 确定其生物活性和潜在毒性的过程,就是PHENOMIC AI要解决的。
第三个也是PathAI做的,通过热力图以及药理的图片,去帮助医生更好的观测现象。最后一个是CLOUD MEDX,他们拿到了很多医疗记录,通过这些医疗的记录,实时分析病人的信息,同时通过真实的病例数据和实验数据,做健康诊断的推荐,从而帮助医生更好的做诊断,并合理进行药物的配发。
在各个方面的应用讲完之后,我想深入的讲一下,目前这几个领域,用到了什么样的技术或者方法,可以帮助医生改善诊断效果。最近有一部很火的电影叫《我不是药神》,谈到了医药公司的问题现状,在最开始的专利期,他们的药会价格非常高以收回投资成本。
因为在医药研发的领域,需要非常大的投资,需要非常多的人才,做非常多的实验,这些都是非常昂贵的成本。为了弥补企业成本并且达到盈利,只能在最开始的专利期收取高价,这也是为了让药物研发公司有动力继续投入研发。如果可以用深度学习的方式,或者用GPU加速整个药物的研发过程。将能够在一定程度降低药物的价格,从而去帮助整个医疗行业进入更加良性的发展阶段。
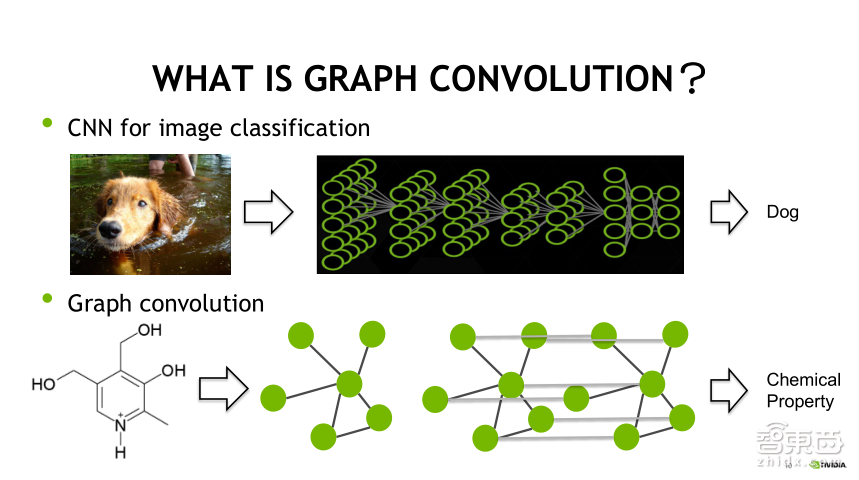
既然可以用GPU和深度学习来加速,到底该怎么具体操作呢?如果有做视觉的同学,可能知道是从CNN开始,能够取得一个好的效果,其实就是从图片的分类开始。结果很简单,就是用卷积核在图片上面做卷积,然后经过各种隐藏层的计算之后,可以判断图片内容。图片是一个很简单、很规整的RGB数据 ,但是对于药物发现来说,药物的结构并不是一个规整的矩阵,该怎么来做呢?
这个时候就有了所谓的Graph convolution,即图卷积。通过图卷积的方式,可以把药物的结构映射成卷积结构,映射成一个矩阵。然后就可以用CNN来做一些检测判断或者药物的发现。那么图上的卷积网络从卷积方式来说,可以分为两种,图卷积和空间域卷积,在此只对空间域卷积进行简单的介绍。图卷积是将卷积网络的滤波器和图信号,同时搬到傅立叶域之后再处理,而空间域卷积是用图中的节点在空间域进行相连达到层积的结构,从而进行卷积,获得一个好的效果,具体怎么来操作呢?

跟传统方法相比,图卷积有更低的计算开销和更少的计算时间,但是也有一个难点,就是很难保证准确性。常见的图卷积算法包括NFP、Weave、GGNN以及SGCN。这些方法都已经应用到了医疗领域,并进行了一些基本的研究。
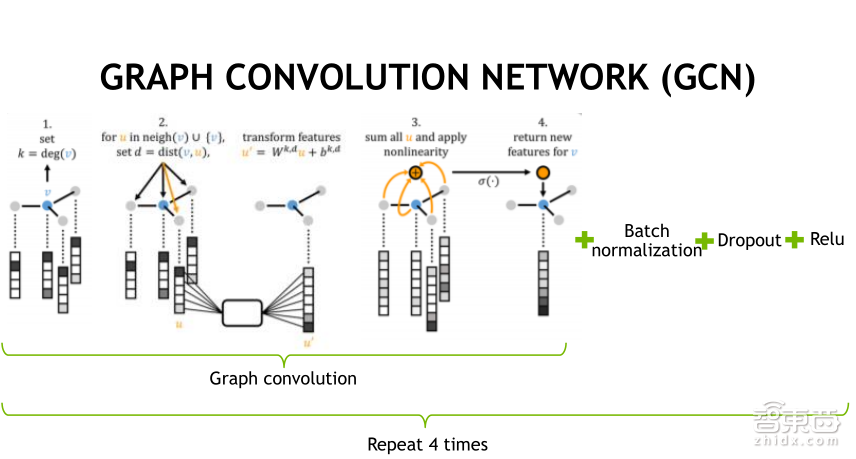
空间域的卷积相对来说比较简单。以药物分子为例,其实每一个分子,都可以看成一个节点,对每个结点去寻找最开始旁边的域,一个分子会有非常多的节点,到底哪个节点,对这个分子比较重要,那肯定是连接数越多的越重要,通过这样的方式筛选出很多节点,找到每个节点邻近的几个分子;第二步,把临近的分子拼成一个感知域,之后用卷积神经网络,在感知域上做卷积操作,从而获得该卷积域的特征。
做卷积时,会执行一些非线性的操作,生成一些新的特征,然后应用到节点上,图卷积的过程之后加上Batch normalization、Dropout和Relu,重复四次,就是整个图卷积的结构。通过这样的结构,就能把分子的状态应用到CNN领域。不像以前,由于分子的结构是非矩阵型的,不能够进行应用,而和应用相比能不能带来加速呢,下面我就会给大家讲一下。
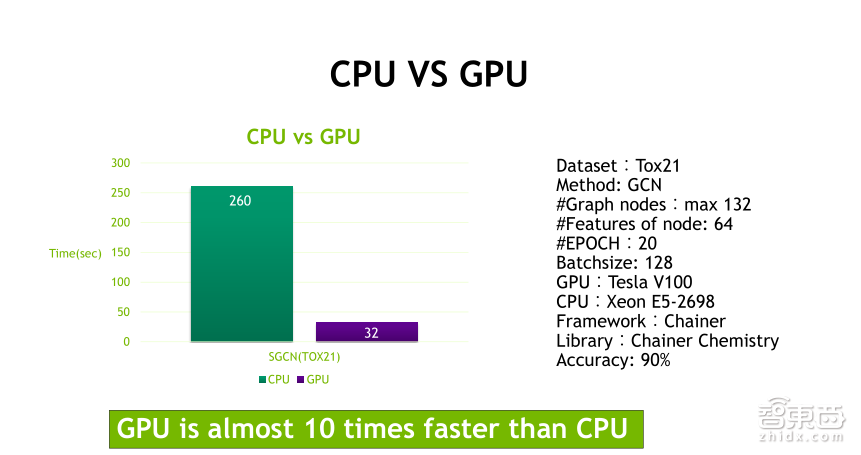
这个是CPU和GPU在Tox21上使用GCN方法的性能比较,可以看到图上最多有132个节点,每个节点有六十四个feature(特征),跑了二十个Epoch,Batchsize是一百二十八,使用Tesla V100 GPU或Xeon E5-2698CPU,在准确率达到90%的情况下,用CPU训练的时间是260秒,而GPU只用了32秒,也就意味着GPU是10倍快于CPU,因此我们能够更好地利用GPU来加速药物的研究,从而降低药物研发成本和社会负担,让所有的患者用良心的价格获得更好的药物,其实还有很多方式可以把AI应用到药物发现领域。AI除了在药物发现方面的应用,也可以应用于基因领域。
很多疾病是由于基因突变或者基因缺陷引起的。人类曾经有一个非常大的工程叫做基因测序,把人类的两对染色体进行基因测序。具体怎么做基因测试的,不知道大家有没有了解。那么我给大家介绍一下,首先将待测序的DNA进行扩增,复制出很多DNA,之后进行加热变性,由于基因是双螺旋结构,把双链DNA分开之后,在里面加入引物,从而让聚合酶发挥作用,这样就可以复制这一段基因的信息。
把DNA聚合酶加入到反应容器,每个反应容器里面放的都是前面所提取出来的单链DNA,利用ATGC基本的碱基酶原料,就可以复制整个基因序列,同时放一个特殊的碱基A进去,能够停止复制。此时就可以开始进行整个DNA的反应。

在完成了DNA的反应之后,因为有一个特殊的碱基A可以停止DNA的复制,在四个不同的样本里,他们有很大的概率是在不同的时间停止,可以根据不同的停止情况,对其通电,较轻的DNA会在通电之后进行移动,通过荧光标记的方式就可以在胶片上留下记号,从而得到整个DNA的顺序。对于DNA测序有两个难点需要解决,首先,染色体三十亿对碱基,怎么去测序?其次是用什么办法进行加速。
对于人来说,两对染色体包含30亿个碱基对,包括了鸟嘌呤、胞嘧啶、腺嘌呤、胸腺嘧啶,组成二十三对染色体。但是我们这些仪器能够产生十一个短序列,我们称之为Read,每个read仅代表了三十亿个碱基中的一百个,每个碱基的错误概率在0.1%-10% 之间,把单一的、小的基因序列完整而准确的拼起来是很困难的。这个时候Google cloud platform提出了开源的方案叫做DeepVariant,通过以编码HTS仪器数据的方式,生成了数千万个训练样本,然后用这个训练样本,基于TensorFlow做图像分类,以便从仪器生成的实验数据中识别出真实的基因组序列。通过这样的方式,可以很简单的判断哪个基因组序列是正确的。在右边的图上,有四种基因组序列:正常的染色体、有一个碱基出现问题的染色体、两个染色体对都被删除,还有一种情况就是由于一些其他因素,比如在最开始做生成的时候复制出错等相关问题,就会出现最后一种图像,通过这样的方式,就能加速基因测试的过程。
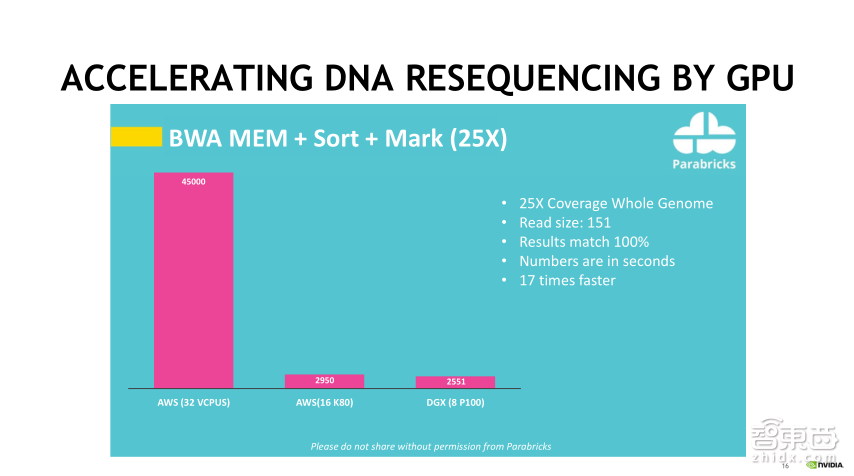
加速完基因测试之后,把每一个read的结果拼到一起,中间会有一个比对过程,把每一个小的单元都跟其对应的序列作比对,从而判断是否准确,此时就有了新的Parabricks,他们在做加速DNA测序的工作,比如说用BWA MEM (比对的工具库),支持较长的Read,然后做一些剪切性的比对。通过这样的方式,用GPU来加速,可以看到跟32个CPU相比,其性能达到了25倍的提升,结果的准确率达到100%。
接下来跟大家分析下AI在医疗记录分析方面的应用,医疗记录分两个部分:医疗文本记录和医疗图片记录,这两个领域分别有怎样的研究,他们具体是怎么操作的呢?

第一个是依靠Icahn School提供的解决方案,他们通过12年的积累,总计700万的医疗记录,训练了一个深度学习模型,可以实现多疾病的预测,以前传统的方法是收集医疗记录做预测模型,但是只能预测一种疾病,现在可以预测七十八种疾病,并且能够做到预防疾病的发生,可以很大程度上降低病人的痛苦。

第二个应用是CLOUD MEDX做的,他们做的内容跟之前几家公司不一样。前面几家公司是基于已有的医疗记录,生成预测模型,去预测病人患病的可能性。CLOUD MEDX则是拿到了一些电子健康记录,比如病史、药物测试报告等数据,里面有两部分数据,一部分是来自医生记录的,跟国内一样,大家都知道我们看自己的病例是看不懂的,当拿到这些非结构化数据之后,做数据结构化的分析,然后直接结合NLP自然语言处理技术;另一部分是实验室的数据,或者生命统计的数据,通过这两部分的数据,开发了一个新的AI平台。
利用该平台分析患者的整个病史、关联的症状以及人口统计的数据和诊断,就可以看到该症状以及对应其他临床上的情况,从数据判断患某种疾病的可能性,帮助医生做一些推荐测试、药物治疗的方案以及辅助医生修改治疗方案等。
第二个领域就是医疗图片,大多是指图片分割和检测判断,这里大概有五个例子,我会详细给大家介绍一下他们是怎么做的。

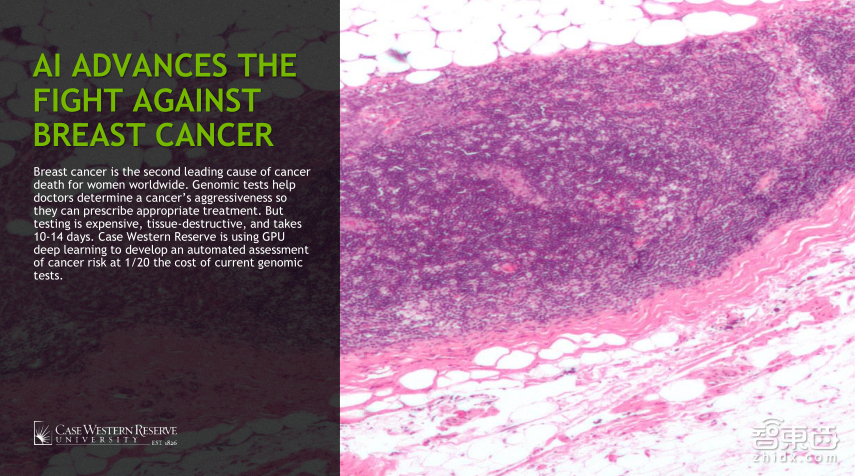
第一张图是PathAI做的,把拿到的病例图片以及识别出的结果做热点图,帮助医生更好的判断;第二个是由凯斯西储大学做的,致力于常见的乳腺癌的研究,正常来说,女性发现乳腺癌之后,最开始医生都会建议做化疗,另一种方式是做病理切片,拿到切片的细胞信息之后才能判断,该测试需要花费四千美金,对于大多数非发达国家的人来说,他们是付不起的,那这个时候怎么做,他们又提出可以用MRI的一些照片,依据现在的病理学照片做风险评估。
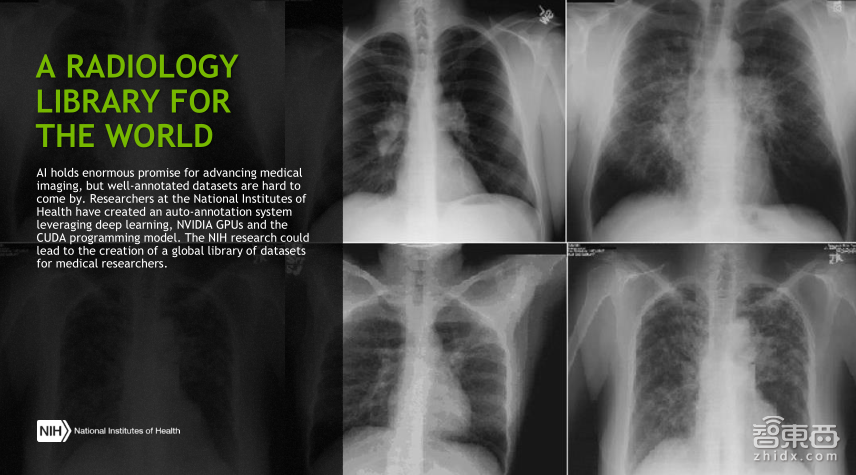
这张图展示的是一个library,即医学图像数据库,医学图像由于其敏感性和工作量,正规的注册数据集很难得到,但在诊断和治疗中非常关键, 是美国的国立研究院提出的一个注册系统,其实这就是一个获得数据集的方法。

上图展示的是用SocialEyes,基于我们的NVIDIA SHIELD 平板电脑上,可以利用里面的GPU,运行深度学习的模型,去判断眼部疾病,因为在一些偏远地区看眼科是非常难的,通过这样一些模型,就能够解决这些问题。
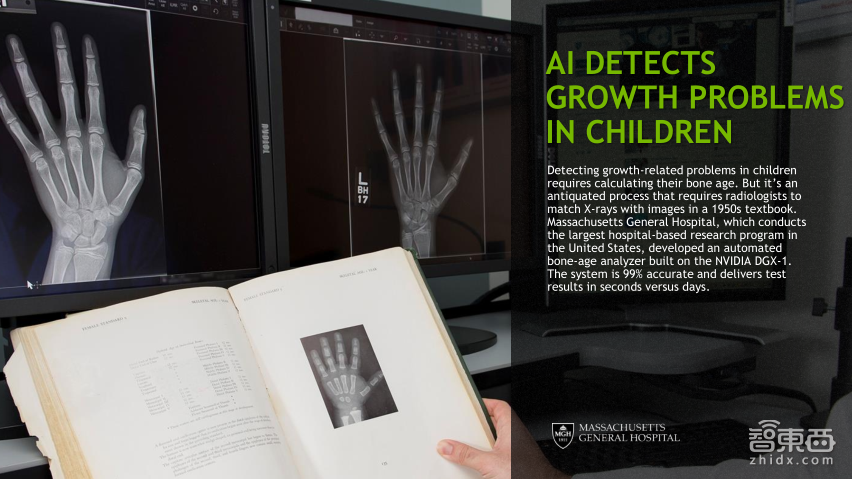
另外可以用深度学习做骨龄测试,传统做法是用X射线图片,和传统的书里面的照片或者以前的图像进行比对,从而判断骨龄。现在可以用深度学习的方式,使用了大概七千四百个X光射线的记录训练了一个深度学习的模型,能够很快地进行训练,通过这样的方式,能够很快的取得很好的结果,其实骨龄测量对小孩来说非常重要。尤其是在国内,很多时候小孩的发展跟他的骨龄完全是不一样的,怎么选择更快的获得结果并进行干预是很重要的。
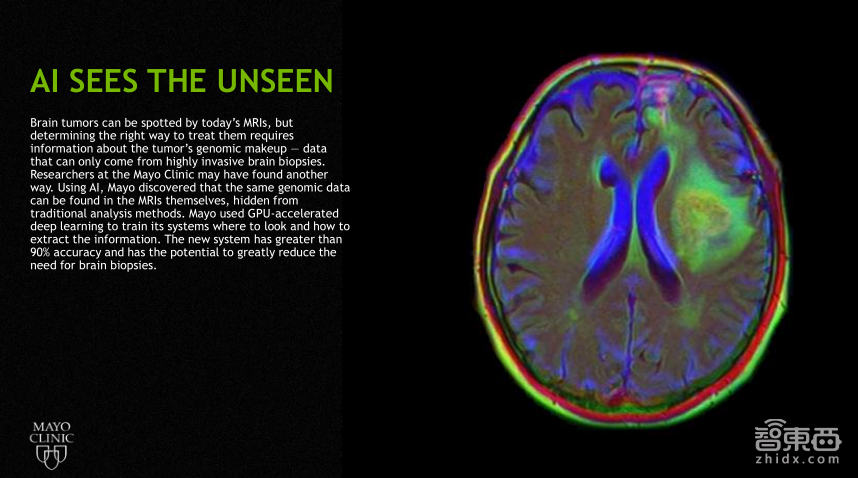
最后一个是用ML发现脑肿瘤,以前的做法可能需要直接打开头颅,然后打个孔,去看拿到的切片,看看里面是不是有肿瘤,及肿瘤状况。现在MAYO CLINIC使用GPU加速,可以用MRI的信息,以前用非深度学习方法发现不了的数据信息,去做一些比对,进而判断到底里面是不是有肿瘤,准确率也超过了90%,所以通过这样的方式,不仅可以把以前的结果做得更好,同时也可以做以前不能做的,而对于medical image(医学图像)我们需要怎样的一个平台呢?
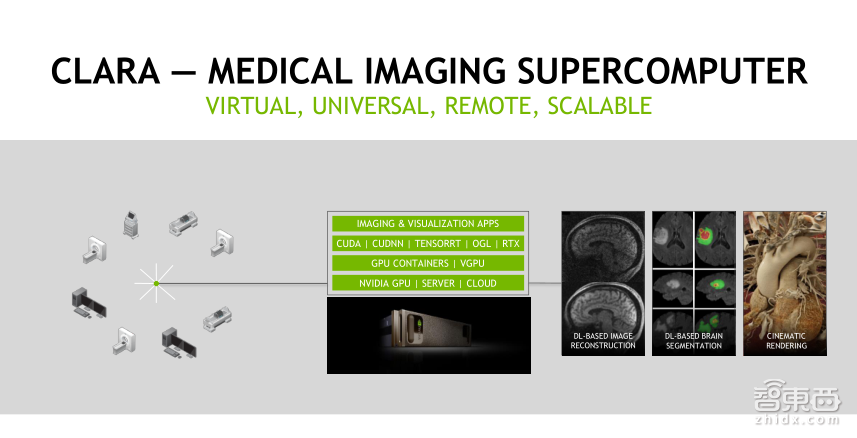
NVIDIA在2018年提出了CLARA平台,我们叫做虚拟、通用、远程、可扩展的平台,所有的合作伙伴都可以加入进来,利用NVIDIA GPU计算资源和加速库,为医院和合作伙伴提供新的算法和方案,CLARA平台可以做基于DL-BASED的Image重建、深度学习的图像分割、图像渲染等操作,该平台最底层用的是DGX以及NVIDIA的GPU,也会提供非常多的软件库,包括CUDA、cuDNN、TensorRT加速库以及Image和各种虚拟化的APP,帮助大家利用这个平台,开发出各种各样的应用。

首先从硬件开始,平台底层需要做计算,我们使用了世界上第一台GPU超级计算机DGX-1,里面配置了八块32G Tesla V100 GPU以及NVLink Mesh。整个系统具有1 PetaFLOPS的计算性能,在做深度学习训练的同时,提供300 Gb/s的NVLink通信带宽。从而保证在训练时能够最快的取得效果。当然这只是硬件方面,除了硬件之外,NVIDIA也提供了一整套的软件支持。

硬件没有软件的支撑,是运行不了的,虽然硬件达到了加速,软件该如何操作呢?NVIDIA提供了一整套软件栈,底层有我们的操作系统,上面有英伟达的GPU驱动以及容器的Runtime,以保证在底层能够调用GPU计算资源。
在GPU之上,NVIDIA还提供各种GPU Docker容器,比如Caffe,Caffe2,TensorFlow,PyTorch,Chainer等,这些容器和驱动以及Docker,包括精简过的OS,驱动都是专门为DGX配置的,而且上面的容器都基于GPU的特性做过优化,从而保证大家能够用到最好的计算性能,训练出自己的GPU模型,为客户提供应用。

在DGX之上,我们有NGC(NVIDIA GPU Cloud),可以提供各种各样容器镜像,DGX也接入到了NGC,这样用户不需要再去配置硬件环境,通过NGC把容器镜像拉下来,就可以开展深度学习的训练和Inference(推理)。

目前NGC提供的容器镜像有35个,分别在不同的领域,包括深度学习、HPC、HPC的视觉、Kubernetes以及我们的合作伙伴提供的各种容器镜像。
NGC提供的深度学习容器镜像包括caffe、caffe2、CNTK,CUDA等,CUDA是NVIDIA提供 的一个基础镜像,包括DIGITS,对深度学习不熟悉的朋友,可以尝试使用DIGITS,它是一个Web UL的界面,底层调用TensorFlow或者Caffe,在里面可以直接开始深度学习的训练,inference server是我们提供的一个Inference的API,它是一个推理的web框架范例。因为我们要做的就是把训练好的模型交付给客户去使用,比如帮助医生去做一些检测。那么如何部署训练好的模型呢?就是使用inference server,它的作用就是把模型放进去,相当于一个web框架,此时会对外暴露出一个API以供调用,从而简化模型开发的过程。
另外一个重要的容器镜像叫做TensorRT,是NVIDIA提供的一个容器加速库,里面已经完成了相应的配置,可以直接使用,能够为深度学习模型带来几倍的加速,下面我会详细介绍。
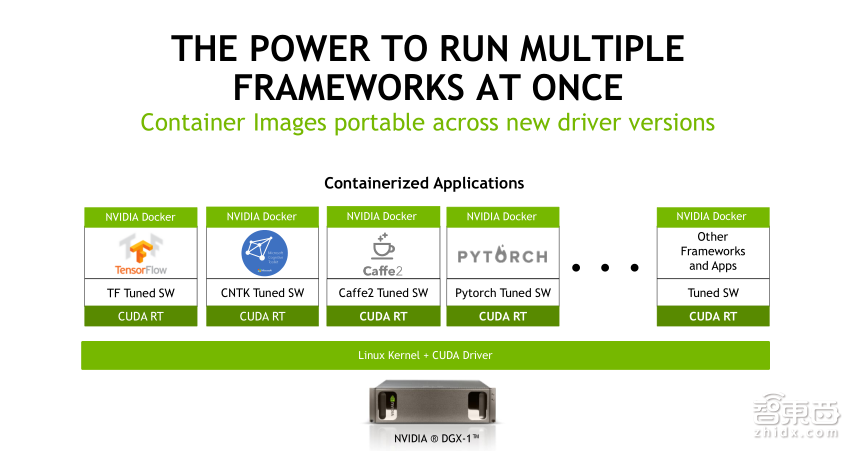
所以基于DGX的硬件,我们提供了专用的OS以及Linux Kernel和CUDA驱动,在上面做各种各样的容器化应用,包括优化好的TensorFlow、CNTK、caffe2、PyTorch等模型,以及各种各样的软件,包括之前提到的inference_ server,这样一整套的软件可以帮助大家更好的去开展深度学习训练,去应用深度学习算法,或者开展一些算法的研究,同时大家也可以利用这些容器镜像进行自己的算法部署。

当然除了DGX和NGC之外,还要考虑怎么使用GPU为深度学习加速?这里NVIDIA提供了DIGITS、深度学习框架以及深度学习的SDK。
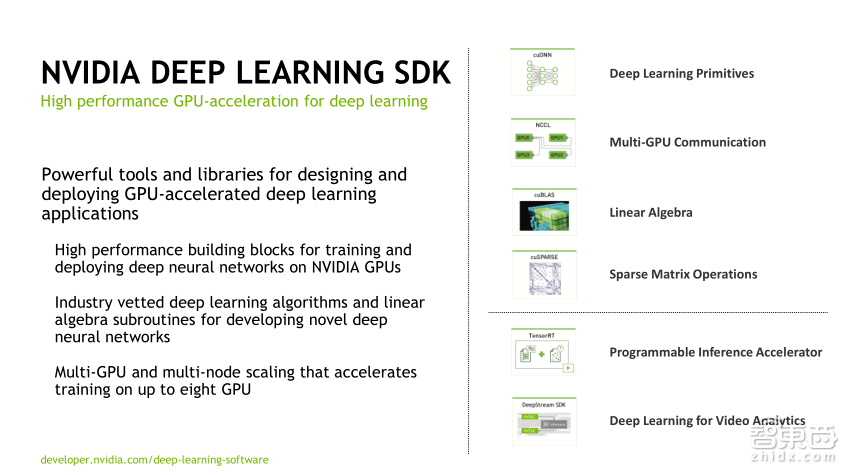
深度学习的SDK主要包括cuDNN、NCCL、cuBLAS、cuSPARSE、TensorRT以及DeepStream6个部分。cuDNN是用CUDA写的DNN加速器。NCCL用于做多GPU的通信,一般来说,训练的时候会有参数服务器,因为GPU之间的数据是要通信的。怎么去加速GPU的通信呢?我们做了算法的实现,做了底层的优化,比如说使用NVLink,多节点之间用了RDMA等,通过这样的方式加速了通信。cuBLAS做一些线性代数的计算;cuSPARSE用于做稀疏矩阵的计算,TensorRT是做inference的加速引擎,可以做到inference的加速,最后一个是DeepStream,提供视频分析的一些方案,提供整套的pipeline,底层调用GPU里面硬件核心、解码器以及CUDA核,从而完成一整套的计算过程。
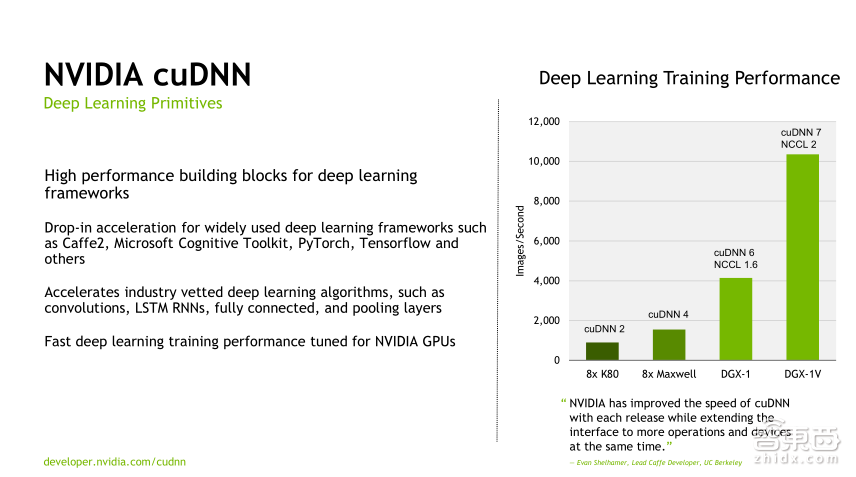
cuDNN是一个高性能深度学习神经网络加速库,被利用到所有的深度学习框架中,包括Caffe、Caffe2、CNTK、TensorFlow、PyTorch等,都在用cuDNN做加速。当然如果需要写自己的软件,也可以用cuDNN来加速,从上图可以看到从最开始的8个K80,到8个Maxwell,再到DGX-1和DGX-1V,在不同的cuDNN版本和不同的硬件上,其性能差距是非常大的。在深度学习的训练方面,从最开始的1000张不到,现在可以训练的图片大概超过10000张,能够进一步加速训练,带来10倍的加速提升,而这样的加速对于开发成熟的产品是非常重要的。

NCCL用于多GPU之间的通信,使用通信算法,底层采用NVLink,PCIe和 InfiniBand,同时能够去检测到整个系统的拓扑结构。从上图可以看到最开始的Maxwell,以及两个P100的比较,然后到1024个P100,可以看到用NCCL在GPU通讯方面能够达到线性的加速,也意味着通信的开销不会导致训练的延时,这个是非常难做的。有HPC (高性能计算) 背景的朋友都知道,能达到线性的加速是非常难的一个任务,而NCCL在通信方面取得了这样的效果。
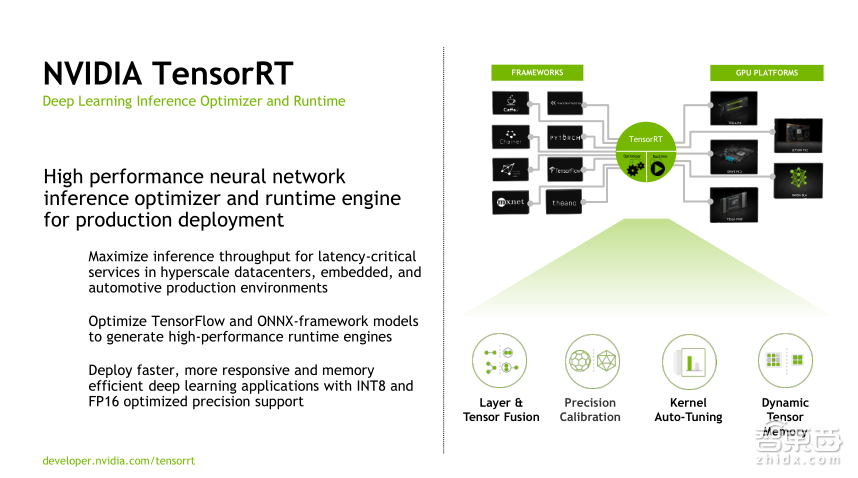
最后一个我想讲的是TensorRT,训练好一个模型,最重要的是模型的准确性和怎么把模型交付给客户使用?推理和训练其实是不一样的,训练时可能用的是FP32的精度,但在推理的时候,可以用更低的精度。训练时,各层之间的关系是固定的,而且需要把中间参数保存下来,从而进行反向迭代。但推理时,只有正向的迭代,此时可以通过使用TensorRT达到免费加速的效果。TensorRT可以做一些Layer fusion,同时也可以做些精度校准,对于不同的GPU卡,可以实现模型的自动调整,动态分配内存,不管是在内存、计算、网络结构以及参数精度方面,都可以用TensorRT达到更好的效果,取得一更好的性能。以P4为例,如果使用FP32精度的参数算力可以达到5.5T,如果使用Int 8精度的参数算力可以达到22T,所以说硬件的性能提升也需要通过软件的优化才能够完成。

最后我想讲的是deep learning的菜单,在医疗领域最重要的就是数据,当然也需要强大的计算力。在此基础上,我们可以用监督学习,或者增强学习,训练各种模型。关于数据来源,我们有各种合作伙伴和研究机构,他们会为我们提供各种数据集。我们也在跟很多医院展开合作,能够提供这样的数据。我们为大家提供最快的计算平台,以保证拿到这些数据之后,能够最快的取得结果。而在算法方面,现在深度学习社区,每年大概有几万甚至十几万篇论文发出来,他们提供了各种各样的思路,比如做图像分割,最开始从一个很简单的网络开始,后来用FCN来实现,现在可能用GAN来做。
通过不同的算法,完成各种各样的应用,解决医疗上各种各样的难题。不管是对个人来讲,还是对社会来讲,都能带来很大的帮助。
以上就是我今天关于AI在医疗领域应用的一些分享,谢谢大家!
Q&A环节
问题一
郭家豪-上海应用技术大学-研究助理
针对传统的在校医学生,毕业后希望转型到医疗领域的深度学习中,在这一转型中,优势有哪些?劣势有哪些?针对深度学习的技术,最关键的核心技术是哪一块儿?
罗晟:你现在是在医疗行业,如果你想要转型到深度学习,我们是非常欢迎的,同时我们也非常希望有专业的医疗行业的人才加入到深度学习的队伍当中,因为对于深度学习来说,它只是一个工具,怎么用这个工具,在哪个方向能够用这个工具才是最关键的。你的优势在于知道怎样应用深度学习技术,用在什么方向,你只要去加强深度学习方面的技术,甚至可以让专业的技术人员帮你做加速。我相信未来也会有相应的工具,能够让人很快的使用,所以方向才是最重要的。
其实,在深度学习领域,想要知道怎么应用,确定好要用的医疗技术及方向之后,就可以用GPU技术来实现,NVIDIA提供了所有框架的优化,你可以使用这些框架来做数据整理,确认好方向之后,有各种各样的research community提供的网络,都可以去尝试,从而在确定的方向取得一定的成果,我相信在确定了方向之后,一切的技术,都不会成为你的阻碍,而且这样的技术肯定会随着未来的发展也变得越来越普及,越来越有用。
问题二
高蓉彬-甘肃畜牧工程职业技术学院-教师
深度学习对药物药理学研究能起到什么作用?
罗晟:我前面的内容已经涉及到了怎么用深度学习做药理学的研究以及在分子方面的研究。比如做药物发现时使用GCN网络,通过该方法,可以去把药物分子结构做映射,从而知道不同的药物之间互相的联系,同时也可以判断药物之后的结果是什么样的,这些都可以用深度学习来完成。
问题三
罗力川-大唐电信-芯片设计工程师
该平台是否用到了英伟达的 DLA加速器了吗?如果用到了,可否详细介绍下?
罗晟:很高兴听你提到NVIDIA的DLA,DLA是一个深度学习加速器,目前实现是在Jetson Xavier上面,Xavier现在是在申请试用中。当然不管是DLA也好, Xavier也好,Tesla GPU也好,还是Tensor Core也好,各种软件在NVIDIA平台都是统一的。任何软件都可以运行在NVIDIA任何版本的GPU上,并且都可以取得很好的效果。
同时这部分的加速都是用TensorRT来实现,TensorRT可以去感知不同硬件的区别,比如P4有Int8的支持,而在P40和v100上有FP16的支持,这样TensorRT就可以屏蔽底层任何硬件的信息来使用。但另一个方面,因为Xavier现在是刚开发出来。相信在未来,比如我有一个平板电脑,就跟我前面案例提及的平板电脑,提供这样的解决方案,帮助贫困地区的人们使用到GPU加速,在医疗行业为边远地区的人民带来新的希望。
问题四
秦智勇-北京微电子所-工程师
医疗领域信息比较私密,训练怎样解决数据源的问题?
罗晟:这个问题问的非常好,医疗行业数据是比较私密的,怎么解决数据源的问题呢?其实我是这么理解的,首先在最开始训练的时候,会有各种各样的开放的数据集,可以去使用。另一方面,也可以尝试跟一些重要的医疗机构进行合作,我相信随着深度学习的发展,他们未来会需要用到深度学习的技术,而通过合作,他们可以提供各种各样的数据,就像我前面的提到一个案例,美国的一个研究所,就在展开这样的一个合作项目,去收集各样各种各样的数据,并开放给大家,帮助大家把深度学习的技术更好的的应用在医疗方面。
问题五
张承龙-中科院计算所-程序员
医疗领域主要采用哪种深度学习模型,为什么这种模型效果要好,怎么进行小样本学习?
罗晟:深度学习模型有很多种,主要还是取决于应用的领域。比如药物发现领域,可能会用图卷积的网络,两种图卷积的模型都可以使用。如果是一些文本的记录,肯定会用到NLP以及相关的模型;而对于医疗图片,目前来说比较前沿的都会用GAN(生成时对抗网络)来做,训练一个图像分割器,以及一个生成器,来训练一个更好的模型。
当然对于medical image来说,现在是比较容易做的。但是因为GAN有一个很大的问题,就是训练比较难。对于图像分割,用FCN可以取得一个好的效果。小样本的学习,可以通过数据增强的方式,把数据集扩大,同时训练时不要选择太过复杂的网络,以避免一些问题,同时也可以进行一些数据的收集,以便在未来获得一个通用性更强的模型。
问题六
潘宇-北航-微电子专业学生
目前要实现深度学习在医疗领域更好的应用还有哪些问题需要解决
罗晟:我觉得有非常多的问题需要解决,比如拿到了数据如何解释。很多年前我在跟清华的一个教授合作的时候,使用一些医疗的信息,比如用深度学习去挖掘诊脉的信息,怎么让诊脉的结果出来之后可以做判断?之前去拍MI和CT照片的时候,为什么医生可以说这样是有问题的,那样是没问题的呢?
我相信在当时也是通过数据统计的方法,因为有些病人MI和CT的照片里面有这样的情况,所以我们就理解这个地方有这样的问题。对深度学习或者在医疗行业做medical image来说,解决这个问题很简单,我们能够对最后的结果给出一定的解释。不管是经验也好,还是怎样,我们能够把它还原成类似MRI的照片从而告诉医生这个地方是有问题的,通过这样的方式,把可解释性解决。从另一个方面就是我们的技术还有更多方面需要挖掘,在药物发现里面怎么去做进一步的加速,在诊断系统里面,怎样更好的提高系统的准确性等,这些都是未来技术需要去解决的,也需要我们去为之努力。
问题七
乔冠超-电子科技大学-微电子专业学生
深度学习在医疗领域的应用在技术方面和其他领域有什么区别?主要是算法的创新还是硬件平台的创新?
罗晟:从技术根本来说,很多领域,比如图片与图像领域是一样的,没有太多的区别,在深度学习领域,我们谈论的是通用型的模型,虽然不是通用人工智能。像前面的例子,一个模型可以预测七十八种疾病,而之前只能识别一种,这样一个通用的模型最重要一点就是数据,能提供这样的数据,就需要一些数据的创新,也需要算法的创新和更强的算力。
因为更多的数据,意味着需要更强的算力来支撑计算,有更好的模型能够提供更好的精确性,但是在一定程度上模型的复杂度肯定是在增加的,也是需要更大的算力来支持的。所以更强的算力能够保证可以去做一些迭代和测试,从而推动模型的发展,收集更多的数据,其实三者是相辅相成的。
问题八
刘汝洲-北京精真估-NLP技术部负责人
NLP在疾病诊断方面有哪些落地的应用
罗晟:前面已经讲过关于NLP相关内容,可以用NLP对一些病例的信息分析,对于病例的分析主要有两个方面,首先我们可以拿到一些疾病的信息,去做预测,当我们拿到一个最新的病人信息,把它放到模型里面,可以通过病历记录训练出一个模型,从而去判断是否有潜在的疾病风险;另一方面,拿到这些信息之后,跟真实的信息进行比对,可以去做些推荐,获得更好的推荐结果,这两方面也已经落地应用了。
当然还有很多,现在有各种各样的机器人在医院里面提供服务,比如问诊机器人,去医院就诊时,可以去问一下机器人,它会根据你的描述给出相应的诊断反馈,这些都是未来需要提供的,也有一些项目已经落地,我觉得是非常好的。现在的三甲医院是非常拥挤的,有了最开始的定位,才能更准确的选择相应的科室,或者根据这些基本信息推荐解决方案等。











