快无止尽! FasterTransformer 2.0 让 Decoder 不再是你的性能瓶颈
2020-03-09 13:12
#深度学习 #FasterTransformer
 分享到微信
分享到微信
 分享到微博
分享到微博
结论
自从 “Attentionis All You Need” 在 2017 年提出以来至今,Transformer 已经成为 NLP 领域中一个非常热门的架构。而在2019年7月,我们团队开源了 FasterTransformer 1.0,针对 BERT 中的 Transformer Encoder 进行优化和加速,以满足在线业务的低延迟要求。
在解决了 Transformer Encoder 的性能问题之后,我们将重点放到了同样重要的 Transformer Decoder 推理上。在众多基于 Encoding-Decoding 的 NLP 应用推理,有百分之九十以上的时间是消耗在 Decoder 上面。因此,我们在 FasterTransformer1.0 版本的基础上,推出了2.0的版本,增加了针对 Decoder 的优化。其优越的性能将助力于翻译,对话机器人,文字补全修正等多种生成式的场景。
FasterTransformer2.0 的底层由 CUDA 和 cuBLAS 实现,支持 FP16 和 FP32 两种计算模式。其中 FP16 可以充分利用 Volta 和 Turing 架构 GPU 上的 Tensor Core 计算单元。为了兼顾灵活性与效率,我们提供两个不同大小和效果的模块。其中,较小的 Decoder 模块主要优化了 Transformer layer 的部分,能够提供2~4倍左右的加速;而较大的 Decoding 模块则包含了整个解码的流程,灵活性上较 Decoder 模块稍差,但最高能够达到10倍以上的加速。
和 BERT 这样的 Encoder 不同,Decoder 并没有一个非常标准的架构。虽然高阶架构上看都差不多,但需要根据细节去做一些调整,尤其是针对 beam search 部分。我们提供了两个不同大小的模块:Decoder 由单层的 Transformer layer 组成;而 Decoding 除了包含多层的 Transformer layer 之外,还包括了其他函数,例如 embedding_lookup,beam search, position encoding 等等。在小 batch size 的情况,例如 batch size = 1,Decoding 和Decoder 比较起来会有明显的优势;而在大 batch size 的情况,例如 batch size = 256 时,两者的加速效果接近。
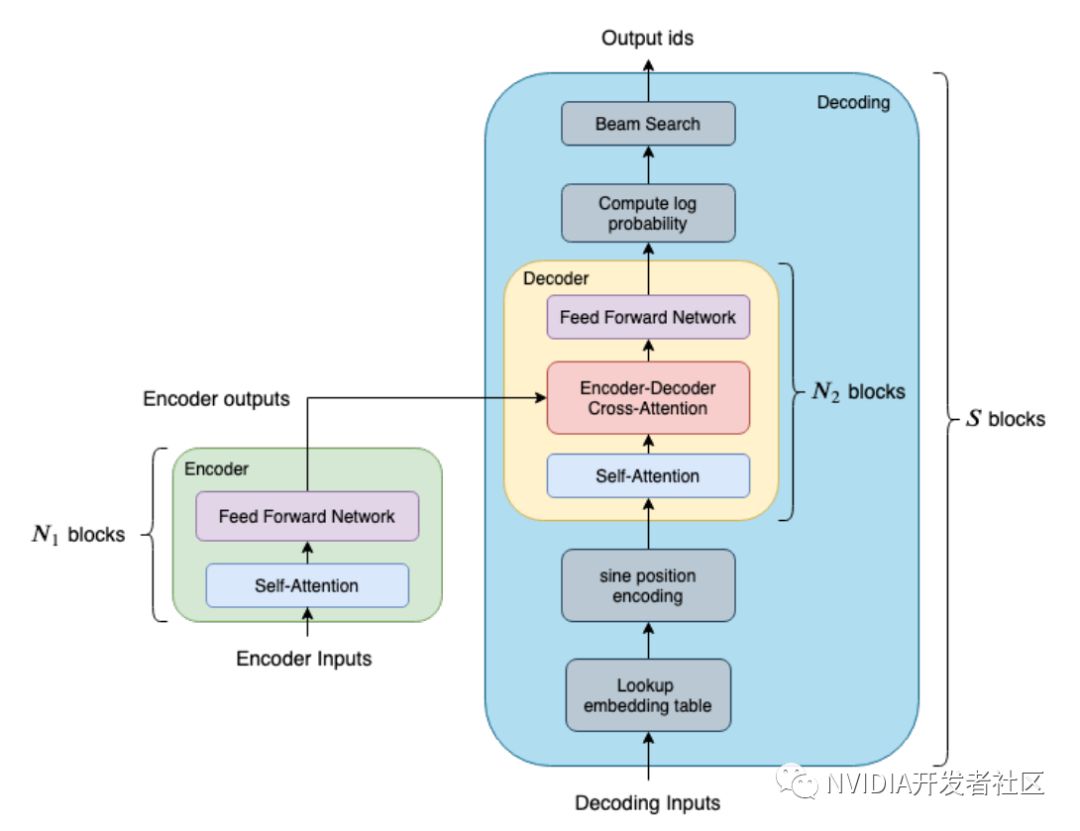
图1展示了 Decoder 和 Decoding 的差别。黄色区块是 Decoder,它包含两个 attention 和一个 feed forward network。而蓝色的大区块则是 Decoding,它包含了整个 Decoding 的流程,包括 embedding lookup,sine position encoding, beam search 等等。以句子长度为32的句子翻译场景为例,其 Decoder 是由6层的 Transformer Layer 组成的,总共需要调用 32x6=192 次的 Decoder;另一方面,如果是使用 Decoding 的话,则只需要调用一次的 Decoding。
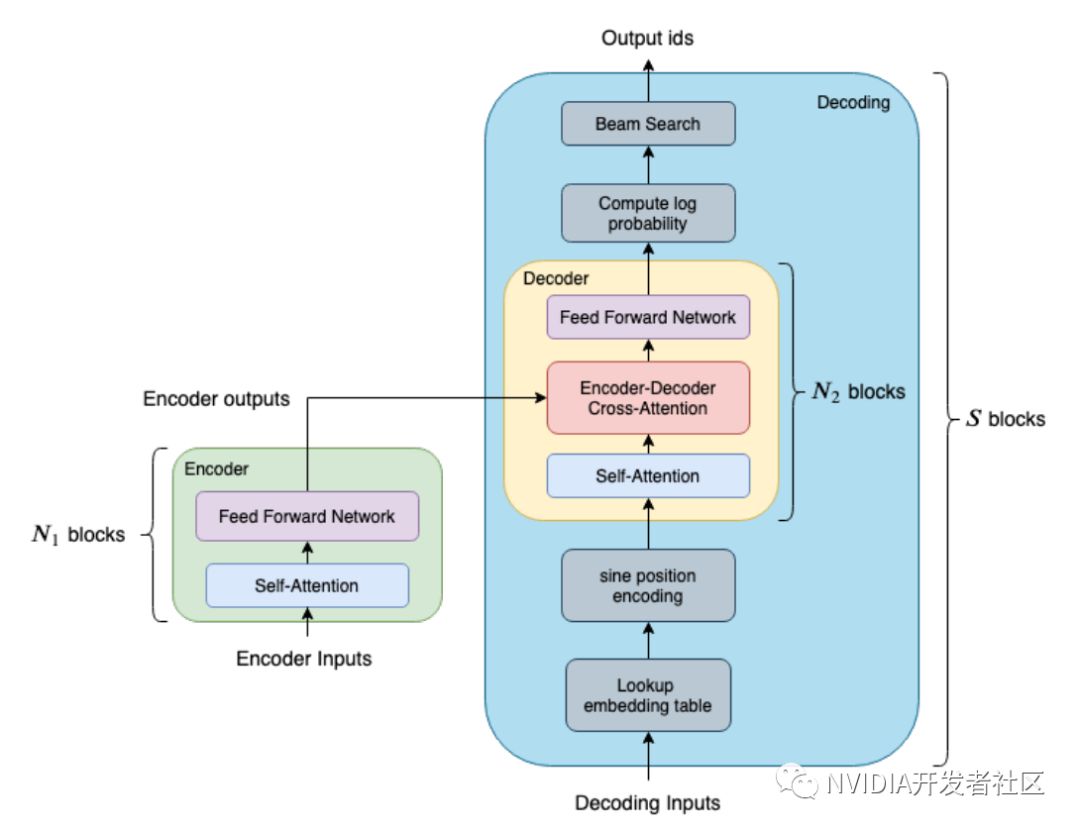
图1. FasterTransformer 中的 Decoder 和 Decoding 模块
总结来看,我们在 FasterTransformer2.0 中,做了以下的更新:
1. 加入了 Transformer Decoder 优化实现。可以支持 Encoder-Decoder 的业务场景。目前 Decoder 可以支持的超参数范围如下:
I. Headnumber: 8, 12
II. Sizeper head: 64
III. Sequencelength: 128 以内
IV. Batch size * beam width: 1024 以内
V. 字典大小: 64 到 30000
需要注意的是,超参数超出支持范围的情况,我们未验证其性能和正确性。
2. 修复 FasterTransformer 1.0 当中的 bug,并且支持 dynamic batch size。
3. 代码进行部分部分重构。
FasterTransformer 目前已经开源,可以访问https://github.com/NVIDIA/DeepLearningExamples/tree/master/FasterTransformer/v2
获取项目全部源代码,最新的性能数据以及支持的特性。欢迎大家前往使用、加星及反馈。
性能
在不同的应用场景下,Decoder 和 Decoding 模块会需要不同的超参数,而这也会导致Decoder 和 Decoding 会有不一样的效果。另外,经过测试, TensorFlow XLA 对 Decoder 和 Decoding 都没有明显的加速。因此下列的测试,都是基于原 TensorFlow 模型来比较的。
测试硬件参数:
CPU: Intel(R) Xeon(R) Gold 6132 CPU @ 2.60GHz
NVIDIA Tesla T4 (with mclk 5000MHz, pclk 1590MHz)
NVIDIATesla V100 (with mclk 877MHz, pclk 1380MHz)
测试软件环境:
CMake >= 3.8
CUDA 10.1
Python 2.7
TensorFlow 1.14 ( Nvidia优化过的TensorFlow:nvcr.io/nvidia/tensorflow :19.07-py2 )
性能对比超参数设定:
head_num = 8
size_per_head = 64
transformer layers = 6
vocabulary_size = 30000
我们比较了 Decoder 和 Decoding 在相同 batch size、不同句子长度的效果;以及相同句子长度下,不同 batch size 的效果。
FasterTransformer Decoder 模块在 NVIDIA Tesla T4 上的结果
我们比较纯粹的 TensorFlow 模型的推理速度,以及把 TensorFlow 模型中的 decoder 换成我们优化过后的 Decoder 之后的推理速度。为了减少 beam search 方面的影响,在这边我们把 beam_width 设为1。
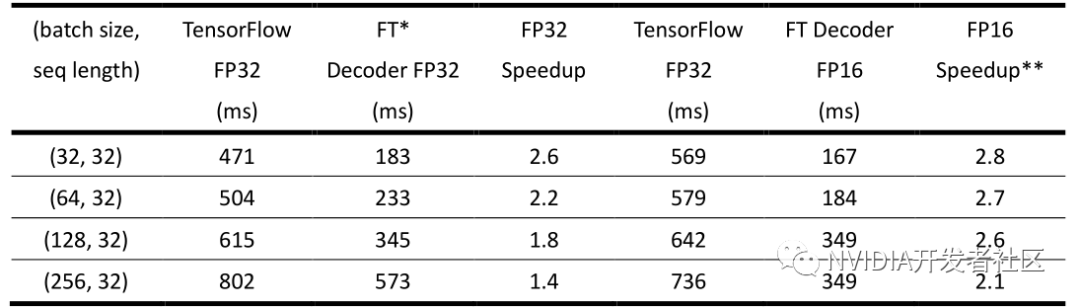
▶ 表1. FasterTransformer 中的 Decoder 在小 batch size 情况下的性能(NVIDIA Tesla T4)

* FT:FasterTransformer
** 与 TensorFlow FP16 的性能对比
表1为将 batch size 固定为1,不同 sequence length 的效果。可以看到即使仅仅替换了 Decoder,在 batch size =1 的情况下至少能带来2.5倍以上的加速。另外,值得注意的是,由于这种情况下的矩阵运算并不能充分利用 Tensor Core 的强大计算能力,因此使用半精度(Tensor Core的计算模式)并没有带来性能的进一步提升。同时因为使用半精度时,TensorFlow 中会引入额外开销,反而导致整体执行时间的增加。
▶ 表2. FasterTransformer 中的 Decoder 在固定 sequence length 的情况下的性能(NVIDIA Tesla T4)
* FT:FasterTransformer
** 与 TensorFlow FP32 或 FP16 中较快者的比较。
表2为固定句子长度在32下,不同 batch size 的效果。当 batch size 很小时,整个 decoder 计算过程并不是 computing bound。而当 batch size 增大时,矩阵运算的时间会跟着增大,因此其他的 overhead 相比起来就会相对比较小。因此,在较大 batch size 的情况下,TensorFlow 的原生实现也可以较好利用 GPU 的计算能力,FasterTransformer 的加速比不明显。即使如此,在单精度的情况下,FasterTransformer 的 Decoder 最少能提供1.4倍的加速,最大能达到2.5倍的加速。
而在半精度的情况下,基于同样的原因(较大 batch size 才能提供足够的计算密度),原生TensorFlow 需要在 batch size 为256时才会有较单精度的加速。因此 FasterTransformer 提供的 FP16 加速比是与 TensorFlow 比较快的情况( FP32 或 FP16 )进行比较的。换句话说,在 batch size 32, 64, 128 时,是和 TensorFlow 单精度的结果比较;在 batch size 256 时,是和 TensorFlow 半精度的结果比较。在这种情况下,使用 FasterTransformer 的 Decoder 能够提供2~2.8倍的加速。
FasterTransformer Decoding 模块在 NVIDIA Tesla T4 上的结果
由于 Decoding 包含了整个翻译的流程,不需要有 TensorFlow 的参与,因此我们比较 TensorFlow 整个翻译的推理时间和 FasterTransformer 的 Decoding 的推理时间。
▶ 表3. FasterTransformer 中 Decoding 模块在小 batch size,beam width 固定为4的情况下的性能(NVIDIA Tesla T4)
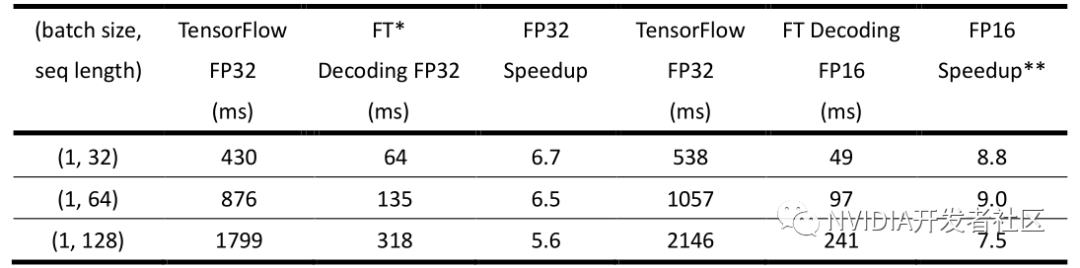
* FT:FasterTransformer
** 与 TensorFlow FP32 或 FP16 中较快者的比较。
表3 是固定 batch size 为1,beam width 为4,不同句子长度的结果。在单精度的情况下,能提供 5.6~6.7 倍的加速。而在半精度的情况下,FasterTransformer 带来额外的 1.2 倍左右的加速(相较 FasterTransformer 单精度性能)。需要注意的是,由于 TensorFlow 的半精度相较于单精度并没有加速,因此这里比较 FasterTransformerDecoding 半精度的时间和 TensorFlow 单精度的时间,加速比在 7~9 倍之间。
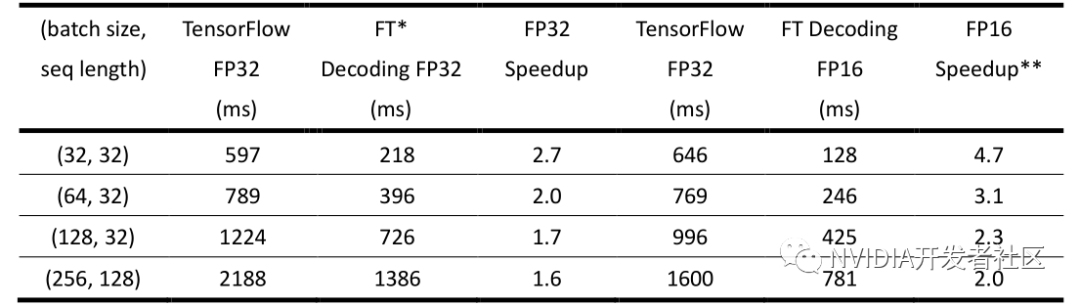
▶ 表4.FasterTransformer中Decoding 模块在固定 beam width = 4,sequence length = 32 的情况下的性能(NVIDIA Tesla T4)
* FT:FasterTransformer
** 与 TensorFlow FP32 或 FP16 中较快者的比较。
表4 为固定 sequence length = 32,beam width = 4 的情况下,不同 batch size 的结果。和 Decoder 的情况相似,在 batch size 比较大的情况下,FasterTransformer 相比原生 TensorFlow 加速比会相应下降。但整体加速比,单精度的情况下能达到 1.5~2.7 倍。半精度的情况能达到 2.0~4.6 倍的加速。
另外,表 2 和表 4 由于 beam width 不一样,因此矩阵计算的 m 维 (矩阵计算维度为m×n×k ) 相差四倍,因此 TensorFlow 在表格 4 当中的推理时间会比表格 2 中同样 batch size 和 sequence length 下慢一些。也因为 m 维比较大,因此加速比也会比较低一些。
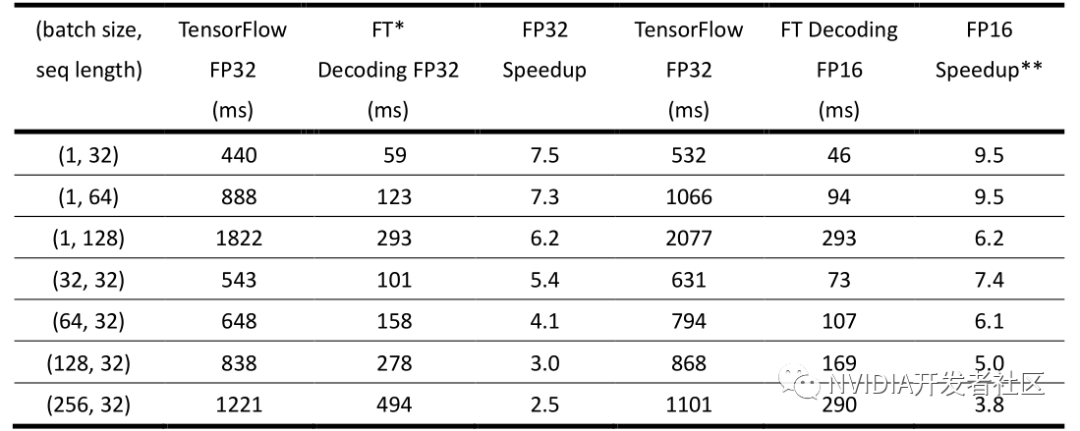
▶ 表5. FasterTransformer 中 Decoding 模块在固定 beam width = 4,不同 batch size和 sequence length 情况下的性能(NVIDIA Tesla V100)
* FT:FasterTransformer
** 与 TensorFlow FP32 或 FP16 中较快者的比较。
表5是 Decoding 在 NVIDIA Tesla V100 上面测试的结果。此处不再赘述。
使用说明
针对 Decoder 和 Decoding,FasterTransformer 分别提供了 C++ 和 TensorFlow OP 这两种接口。同时,我们也提供了示例供用户参考。
TensorFlow 中使用 Decoder 和 Decoding 说明
和 FasterTransformer 1.0 类似,调用 TensorFlow 的接口只需要先导入 .so 文件,然后在代码段中添加 Decoder 或 DecodingOP 的调用即可。
动态链接库的导入方法如下:
decoder_op_module=tf.load_op_library(os.path.join('./lib/libtf_decoder.so'))
调用 OP 的方式如下:

Decoder 需要以下的输入:
1. 从 embedding table 当中抽出来的特征向量或者上一层 Decoder 的输出。
2. Encoder 的结果。
3. 欲翻译的句子的长度,需要根据 beam width 进行过扩充。
4. 存放 maskedmulti-head attention K, V 结果的空间。注意该空间的大小会随着每一步而增加。
5. 存放 cross attention K, V 结果的空间。
6. 所有参数的权重。
7. 一个虚拟的输入 (pseudo input)。这个输入是为了避免 TensorFlow 的 decoder 和 FasterTransformerDecoder 发生并行,因为我们发现并行执行时,Decoder 中的 memory 可能会被污染。实际应用的时候可以将这个输入拿掉。
Decoder 会提供以下的输出:
1. Masked multi-head attention 新的结果
2. Cross attention 新的结果
3. Decoder feature 的输出。
Decoding 的调用也是类似的

需要注意的是,由于 Decoding 需要多层 Decoder 的参数当做输入,因此要事先将这些参数整理好再放入 Decoding op 当中。例如透过以下的方式:

Decoding 的输入:
1. Encoder 的结果。
2. 欲翻译的原句子的长度,需要根据 beam width 进行过扩充。
3. Embedding lookup 时使用的表格。
4. 字典的 start id 和 end id。
5. 所有参数的权重。多层的情况下,需要事先把各层的参数收集起来。
Decoding 会提供以下的输出:
1. 结果的 ids,对应到字典中不同的字
2. Parentsids,对应每一步里头使用的 beam id。
3. 每个句子的长度
C++ 接口
考虑到封装成 TensorFlowOP 会引入一些额外的开销,我们更建议用户直接使用 C++ API。我们测试的结果显示,使用 TensorFlow OP 大概会比直接调用 C++ 慢 30% 左右。目前C++ 接口不支持直接解析训练好的模型。需要用户手动从训练好的模型中将 Transformer 层的 weights 导出。调用方式相对简单,将导出的 weights 赋值给参数结构体,创建相应的对象,调用 initialize 函数初始化对象。运行时,每次调用 forward 即可。具体代码如下所示。
Decoder的C++接口调用方式:

Decoding 除了原本的 decoder 参数之外,需要另外设定好 decoding 的参数。

优化原理
decoder 和 encoder 相比,最大的不同在于,decoder 需要循环多次(句子长度的次数),并且每一次的矩阵计算量比 encoder 小很多。尤其在小 batch size 的情况下,通常不能充分利用 GPU 的计算资源,因此透过将很多细碎的小操作融合成一个较大的核函数来避免 kernel launch overhead 的效果会比 encoder 更加明显。

图2. TensorFlow Decoder 中 Transformer 层的时间线(使用 Nsight System)
图2是 TensorFlow decoder 中单个 Transformer layer 的时间线。可以看到图2中有非常多零碎的小 kernel,另外,有很多地方 GPU 都是处于空闲的状态。因此,在小 batch 的情况,TensorFlow 的表现会比较差。经过统计,TensorFlow 需要使用70个左右的核函数来计算一层 Transformer。

图3. TensorFlowLayerNorm 层计算的时间线(使用 Nsight System)
为什么 TensorFlow 会需要那么多的核函数呢? 因为 TensorFlow 为了照顾灵活性,会将一些复杂的操作拆解成基础的操作。例如图3显示,TensorFlow 计算 layernorm 时,会将单个 layernorm 操作拆成八个核函数,例如 add, sub,sqrt 等等。
虽然 TensorFlow XLA 理论上会针对基本的核函数进行融合优化,但在 Decoder 和 Decoding 的测试中,我们并没有观察到明显加速。
为了提高在小 batch 情况下的 GPU 利用率,我们将里头许多细碎的小计算融合成一个比较大的核函数。图4是 FasterTransformer Decoder 中一层 Transformerlayer 的时间线。我们可以看到每一个 kernel 都相对比较大,并且 GPU 也没有什么处于空闲状态的情况。在经过优化之后,原本 TensorFlow 使用70个核函数才完成的计算,FasterTransformer Decoder 只需要15个核函数就能够完成。

图4. FasterTransformerDecoder中Transformer 层的时间线(使用 NsightSystem)
经过优化之后,FasterTransformer 的 Decoder 中的单层 Transformer 计算流程如图5所示。主要可以分成7个大模块,其中,橘色外框的 mask multi-head attention 可以在拆成5个核函数,cross multi-head attention 可以在拆成3个核函数,FFN也可以再拆成3个核函数。
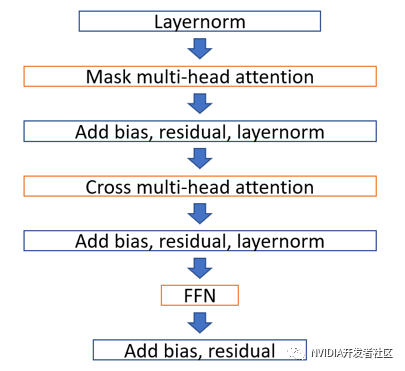
图5. FasterTransformer 中 Decoder 的单层 Transformer 计算流程图
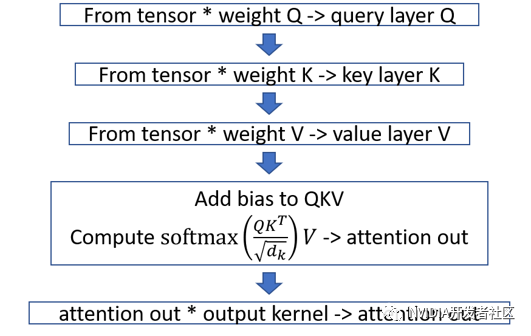
图6. FasterTransformer Decoder 中 mask multi-head attention 模块的计算流程图

图7. FasterTransformerDecoder中cross multi-headattention模块的计算流程图
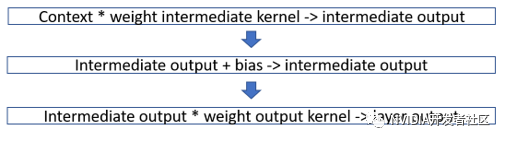
图8. FasterTransformer Decoder 中 FFN 模块的计算流程图
图6、图7、图8分别为 mask multi-head attention, cross multi-headattention 和 FFN 内部的计算流程。值得注意的是,由于 cross multi-head attention 在计算 K 和 V 的时候是使用 encoder 的结果,因此只要计算一次,把结果存下来即可。所以,cross multi-head attention 可以视为只有三个核函数。
除此之外,我们也提供了半精度的接口。由于目前主要的瓶颈在于 Decoder Transformer layer 中的矩阵计算,而非我们自定义的核函数。因此目前只有将矩阵计算的部分转换为半精度来加速。
除上述优化之外,Faster Transformer 还优化了前向计算中耗时较高 Layer Normalization 以及 SoftMax 等操作。比如利用 warp shuffle 实现高效的矩阵按行求和操作, 将 1/sqrtf 计算替换为 rsqrtf 函数,以及 power (x, 3.0) 替换为 x * x * x 等。总之,我们针对 Transformer 进行了各种优化以保证它的高效执行。
结论
FasterTransformer 是一个开源的高效 Transformer 实现。我们在1.0的基础上,加上了Transformer Decoder 的优化。我们提供了两种不同大小、不同效率的模块提供用户使用,使用者可以根据自己的应用场景选择。和 TensorFlow 的实现相比,我们优化过后的 Decoder 和 Decoding 提供 1.4~10倍的加速。FasterTransformer 提供了C++和TensorFlow OP 的接口。对于每一种接口,我们也提供了完整的示例,方便用户集成。
FasterTransformer 2.0 目前已经开源,可以访问
https://github.com/NVIDIA/DeepLearningExamples/tree/master/FasterTransformer/v2
获取项目全部源代码,最新的性能数据以及支持的特性。欢迎大家前往使用、加星及反馈。
自从 “Attentionis All You Need” 在 2017 年提出以来至今,Transformer 已经成为 NLP 领域中一个非常热门的架构。而在2019年7月,我们团队开源了 FasterTransformer 1.0,针对 BERT 中的 Transformer Encoder 进行优化和加速,以满足在线业务的低延迟要求。
在解决了 Transformer Encoder 的性能问题之后,我们将重点放到了同样重要的 Transformer Decoder 推理上。在众多基于 Encoding-Decoding 的 NLP 应用推理,有百分之九十以上的时间是消耗在 Decoder 上面。因此,我们在 FasterTransformer1.0 版本的基础上,推出了2.0的版本,增加了针对 Decoder 的优化。其优越的性能将助力于翻译,对话机器人,文字补全修正等多种生成式的场景。
FasterTransformer2.0 的底层由 CUDA 和 cuBLAS 实现,支持 FP16 和 FP32 两种计算模式。其中 FP16 可以充分利用 Volta 和 Turing 架构 GPU 上的 Tensor Core 计算单元。为了兼顾灵活性与效率,我们提供两个不同大小和效果的模块。其中,较小的 Decoder 模块主要优化了 Transformer layer 的部分,能够提供2~4倍左右的加速;而较大的 Decoding 模块则包含了整个解码的流程,灵活性上较 Decoder 模块稍差,但最高能够达到10倍以上的加速。
和 BERT 这样的 Encoder 不同,Decoder 并没有一个非常标准的架构。虽然高阶架构上看都差不多,但需要根据细节去做一些调整,尤其是针对 beam search 部分。我们提供了两个不同大小的模块:Decoder 由单层的 Transformer layer 组成;而 Decoding 除了包含多层的 Transformer layer 之外,还包括了其他函数,例如 embedding_lookup,beam search, position encoding 等等。在小 batch size 的情况,例如 batch size = 1,Decoding 和Decoder 比较起来会有明显的优势;而在大 batch size 的情况,例如 batch size = 256 时,两者的加速效果接近。
图1展示了 Decoder 和 Decoding 的差别。黄色区块是 Decoder,它包含两个 attention 和一个 feed forward network。而蓝色的大区块则是 Decoding,它包含了整个 Decoding 的流程,包括 embedding lookup,sine position encoding, beam search 等等。以句子长度为32的句子翻译场景为例,其 Decoder 是由6层的 Transformer Layer 组成的,总共需要调用 32x6=192 次的 Decoder;另一方面,如果是使用 Decoding 的话,则只需要调用一次的 Decoding。
图1. FasterTransformer 中的 Decoder 和 Decoding 模块
总结来看,我们在 FasterTransformer2.0 中,做了以下的更新:
1. 加入了 Transformer Decoder 优化实现。可以支持 Encoder-Decoder 的业务场景。目前 Decoder 可以支持的超参数范围如下:
I. Headnumber: 8, 12
II. Sizeper head: 64
III. Sequencelength: 128 以内
IV. Batch size * beam width: 1024 以内
V. 字典大小: 64 到 30000
需要注意的是,超参数超出支持范围的情况,我们未验证其性能和正确性。
2. 修复 FasterTransformer 1.0 当中的 bug,并且支持 dynamic batch size。
3. 代码进行部分部分重构。
FasterTransformer 目前已经开源,可以访问https://github.com/NVIDIA/DeepLearningExamples/tree/master/FasterTransformer/v2
获取项目全部源代码,最新的性能数据以及支持的特性。欢迎大家前往使用、加星及反馈。
性能
在不同的应用场景下,Decoder 和 Decoding 模块会需要不同的超参数,而这也会导致Decoder 和 Decoding 会有不一样的效果。另外,经过测试, TensorFlow XLA 对 Decoder 和 Decoding 都没有明显的加速。因此下列的测试,都是基于原 TensorFlow 模型来比较的。
测试硬件参数:
CPU: Intel(R) Xeon(R) Gold 6132 CPU @ 2.60GHz
NVIDIA Tesla T4 (with mclk 5000MHz, pclk 1590MHz)
NVIDIATesla V100 (with mclk 877MHz, pclk 1380MHz)
测试软件环境:
CMake >= 3.8
CUDA 10.1
Python 2.7
TensorFlow 1.14 ( Nvidia优化过的TensorFlow:nvcr.io/nvidia/tensorflow :19.07-py2 )
性能对比超参数设定:
head_num = 8
size_per_head = 64
transformer layers = 6
vocabulary_size = 30000
我们比较了 Decoder 和 Decoding 在相同 batch size、不同句子长度的效果;以及相同句子长度下,不同 batch size 的效果。
FasterTransformer Decoder 模块在 NVIDIA Tesla T4 上的结果
我们比较纯粹的 TensorFlow 模型的推理速度,以及把 TensorFlow 模型中的 decoder 换成我们优化过后的 Decoder 之后的推理速度。为了减少 beam search 方面的影响,在这边我们把 beam_width 设为1。
▶ 表1. FasterTransformer 中的 Decoder 在小 batch size 情况下的性能(NVIDIA Tesla T4)
* FT:FasterTransformer
** 与 TensorFlow FP16 的性能对比
表1为将 batch size 固定为1,不同 sequence length 的效果。可以看到即使仅仅替换了 Decoder,在 batch size =1 的情况下至少能带来2.5倍以上的加速。另外,值得注意的是,由于这种情况下的矩阵运算并不能充分利用 Tensor Core 的强大计算能力,因此使用半精度(Tensor Core的计算模式)并没有带来性能的进一步提升。同时因为使用半精度时,TensorFlow 中会引入额外开销,反而导致整体执行时间的增加。
▶ 表2. FasterTransformer 中的 Decoder 在固定 sequence length 的情况下的性能(NVIDIA Tesla T4)
* FT:FasterTransformer
** 与 TensorFlow FP32 或 FP16 中较快者的比较。
表2为固定句子长度在32下,不同 batch size 的效果。当 batch size 很小时,整个 decoder 计算过程并不是 computing bound。而当 batch size 增大时,矩阵运算的时间会跟着增大,因此其他的 overhead 相比起来就会相对比较小。因此,在较大 batch size 的情况下,TensorFlow 的原生实现也可以较好利用 GPU 的计算能力,FasterTransformer 的加速比不明显。即使如此,在单精度的情况下,FasterTransformer 的 Decoder 最少能提供1.4倍的加速,最大能达到2.5倍的加速。
而在半精度的情况下,基于同样的原因(较大 batch size 才能提供足够的计算密度),原生TensorFlow 需要在 batch size 为256时才会有较单精度的加速。因此 FasterTransformer 提供的 FP16 加速比是与 TensorFlow 比较快的情况( FP32 或 FP16 )进行比较的。换句话说,在 batch size 32, 64, 128 时,是和 TensorFlow 单精度的结果比较;在 batch size 256 时,是和 TensorFlow 半精度的结果比较。在这种情况下,使用 FasterTransformer 的 Decoder 能够提供2~2.8倍的加速。
FasterTransformer Decoding 模块在 NVIDIA Tesla T4 上的结果
由于 Decoding 包含了整个翻译的流程,不需要有 TensorFlow 的参与,因此我们比较 TensorFlow 整个翻译的推理时间和 FasterTransformer 的 Decoding 的推理时间。
▶ 表3. FasterTransformer 中 Decoding 模块在小 batch size,beam width 固定为4的情况下的性能(NVIDIA Tesla T4)
* FT:FasterTransformer
** 与 TensorFlow FP32 或 FP16 中较快者的比较。
表3 是固定 batch size 为1,beam width 为4,不同句子长度的结果。在单精度的情况下,能提供 5.6~6.7 倍的加速。而在半精度的情况下,FasterTransformer 带来额外的 1.2 倍左右的加速(相较 FasterTransformer 单精度性能)。需要注意的是,由于 TensorFlow 的半精度相较于单精度并没有加速,因此这里比较 FasterTransformerDecoding 半精度的时间和 TensorFlow 单精度的时间,加速比在 7~9 倍之间。
▶ 表4.FasterTransformer中Decoding 模块在固定 beam width = 4,sequence length = 32 的情况下的性能(NVIDIA Tesla T4)
* FT:FasterTransformer
** 与 TensorFlow FP32 或 FP16 中较快者的比较。
表4 为固定 sequence length = 32,beam width = 4 的情况下,不同 batch size 的结果。和 Decoder 的情况相似,在 batch size 比较大的情况下,FasterTransformer 相比原生 TensorFlow 加速比会相应下降。但整体加速比,单精度的情况下能达到 1.5~2.7 倍。半精度的情况能达到 2.0~4.6 倍的加速。
另外,表 2 和表 4 由于 beam width 不一样,因此矩阵计算的 m 维 (矩阵计算维度为m×n×k ) 相差四倍,因此 TensorFlow 在表格 4 当中的推理时间会比表格 2 中同样 batch size 和 sequence length 下慢一些。也因为 m 维比较大,因此加速比也会比较低一些。
▶ 表5. FasterTransformer 中 Decoding 模块在固定 beam width = 4,不同 batch size和 sequence length 情况下的性能(NVIDIA Tesla V100)
* FT:FasterTransformer
** 与 TensorFlow FP32 或 FP16 中较快者的比较。
表5是 Decoding 在 NVIDIA Tesla V100 上面测试的结果。此处不再赘述。
使用说明
针对 Decoder 和 Decoding,FasterTransformer 分别提供了 C++ 和 TensorFlow OP 这两种接口。同时,我们也提供了示例供用户参考。
TensorFlow 中使用 Decoder 和 Decoding 说明
和 FasterTransformer 1.0 类似,调用 TensorFlow 的接口只需要先导入 .so 文件,然后在代码段中添加 Decoder 或 DecodingOP 的调用即可。
动态链接库的导入方法如下:
decoder_op_module=tf.load_op_library(os.path.join('./lib/libtf_decoder.so'))
调用 OP 的方式如下:
Decoder 需要以下的输入:
1. 从 embedding table 当中抽出来的特征向量或者上一层 Decoder 的输出。
2. Encoder 的结果。
3. 欲翻译的句子的长度,需要根据 beam width 进行过扩充。
4. 存放 maskedmulti-head attention K, V 结果的空间。注意该空间的大小会随着每一步而增加。
5. 存放 cross attention K, V 结果的空间。
6. 所有参数的权重。
7. 一个虚拟的输入 (pseudo input)。这个输入是为了避免 TensorFlow 的 decoder 和 FasterTransformerDecoder 发生并行,因为我们发现并行执行时,Decoder 中的 memory 可能会被污染。实际应用的时候可以将这个输入拿掉。
Decoder 会提供以下的输出:
1. Masked multi-head attention 新的结果
2. Cross attention 新的结果
3. Decoder feature 的输出。
Decoding 的调用也是类似的
需要注意的是,由于 Decoding 需要多层 Decoder 的参数当做输入,因此要事先将这些参数整理好再放入 Decoding op 当中。例如透过以下的方式:
Decoding 的输入:
1. Encoder 的结果。
2. 欲翻译的原句子的长度,需要根据 beam width 进行过扩充。
3. Embedding lookup 时使用的表格。
4. 字典的 start id 和 end id。
5. 所有参数的权重。多层的情况下,需要事先把各层的参数收集起来。
Decoding 会提供以下的输出:
1. 结果的 ids,对应到字典中不同的字
2. Parentsids,对应每一步里头使用的 beam id。
3. 每个句子的长度
C++ 接口
考虑到封装成 TensorFlowOP 会引入一些额外的开销,我们更建议用户直接使用 C++ API。我们测试的结果显示,使用 TensorFlow OP 大概会比直接调用 C++ 慢 30% 左右。目前C++ 接口不支持直接解析训练好的模型。需要用户手动从训练好的模型中将 Transformer 层的 weights 导出。调用方式相对简单,将导出的 weights 赋值给参数结构体,创建相应的对象,调用 initialize 函数初始化对象。运行时,每次调用 forward 即可。具体代码如下所示。
Decoder的C++接口调用方式:
Decoding 除了原本的 decoder 参数之外,需要另外设定好 decoding 的参数。
优化原理
decoder 和 encoder 相比,最大的不同在于,decoder 需要循环多次(句子长度的次数),并且每一次的矩阵计算量比 encoder 小很多。尤其在小 batch size 的情况下,通常不能充分利用 GPU 的计算资源,因此透过将很多细碎的小操作融合成一个较大的核函数来避免 kernel launch overhead 的效果会比 encoder 更加明显。
图2. TensorFlow Decoder 中 Transformer 层的时间线(使用 Nsight System)
图2是 TensorFlow decoder 中单个 Transformer layer 的时间线。可以看到图2中有非常多零碎的小 kernel,另外,有很多地方 GPU 都是处于空闲的状态。因此,在小 batch 的情况,TensorFlow 的表现会比较差。经过统计,TensorFlow 需要使用70个左右的核函数来计算一层 Transformer。
图3. TensorFlowLayerNorm 层计算的时间线(使用 Nsight System)
为什么 TensorFlow 会需要那么多的核函数呢? 因为 TensorFlow 为了照顾灵活性,会将一些复杂的操作拆解成基础的操作。例如图3显示,TensorFlow 计算 layernorm 时,会将单个 layernorm 操作拆成八个核函数,例如 add, sub,sqrt 等等。
虽然 TensorFlow XLA 理论上会针对基本的核函数进行融合优化,但在 Decoder 和 Decoding 的测试中,我们并没有观察到明显加速。
为了提高在小 batch 情况下的 GPU 利用率,我们将里头许多细碎的小计算融合成一个比较大的核函数。图4是 FasterTransformer Decoder 中一层 Transformerlayer 的时间线。我们可以看到每一个 kernel 都相对比较大,并且 GPU 也没有什么处于空闲状态的情况。在经过优化之后,原本 TensorFlow 使用70个核函数才完成的计算,FasterTransformer Decoder 只需要15个核函数就能够完成。
图4. FasterTransformerDecoder中Transformer 层的时间线(使用 NsightSystem)
经过优化之后,FasterTransformer 的 Decoder 中的单层 Transformer 计算流程如图5所示。主要可以分成7个大模块,其中,橘色外框的 mask multi-head attention 可以在拆成5个核函数,cross multi-head attention 可以在拆成3个核函数,FFN也可以再拆成3个核函数。
图5. FasterTransformer 中 Decoder 的单层 Transformer 计算流程图
图6. FasterTransformer Decoder 中 mask multi-head attention 模块的计算流程图
图7. FasterTransformerDecoder中cross multi-headattention模块的计算流程图
图8. FasterTransformer Decoder 中 FFN 模块的计算流程图
图6、图7、图8分别为 mask multi-head attention, cross multi-headattention 和 FFN 内部的计算流程。值得注意的是,由于 cross multi-head attention 在计算 K 和 V 的时候是使用 encoder 的结果,因此只要计算一次,把结果存下来即可。所以,cross multi-head attention 可以视为只有三个核函数。
除此之外,我们也提供了半精度的接口。由于目前主要的瓶颈在于 Decoder Transformer layer 中的矩阵计算,而非我们自定义的核函数。因此目前只有将矩阵计算的部分转换为半精度来加速。
除上述优化之外,Faster Transformer 还优化了前向计算中耗时较高 Layer Normalization 以及 SoftMax 等操作。比如利用 warp shuffle 实现高效的矩阵按行求和操作, 将 1/sqrtf 计算替换为 rsqrtf 函数,以及 power (x, 3.0) 替换为 x * x * x 等。总之,我们针对 Transformer 进行了各种优化以保证它的高效执行。
结论
FasterTransformer 是一个开源的高效 Transformer 实现。我们在1.0的基础上,加上了Transformer Decoder 的优化。我们提供了两种不同大小、不同效率的模块提供用户使用,使用者可以根据自己的应用场景选择。和 TensorFlow 的实现相比,我们优化过后的 Decoder 和 Decoding 提供 1.4~10倍的加速。FasterTransformer 提供了C++和TensorFlow OP 的接口。对于每一种接口,我们也提供了完整的示例,方便用户集成。
FasterTransformer 2.0 目前已经开源,可以访问
https://github.com/NVIDIA/DeepLearningExamples/tree/master/FasterTransformer/v2
获取项目全部源代码,最新的性能数据以及支持的特性。欢迎大家前往使用、加星及反馈。











