
微软训练出全球最大Transformer语言模型——Turing-NLG
2020-02-19 16:18
 分享到微信
分享到微信
 分享到微博
分享到微博
微软于近日宣布其在会话式AI方面取得了突破性成果——借助于NVIDIA DGX-2系统,微软训练了最大的基于Transformer的语言生成模型,该模型参数达到170亿。而且,微软还开源了DeepSpeed深度学习库,该数据库可以在延迟和推理方面为开发者提供帮助。
微软此次训练的模型名为Turing Natural Language Generation(T-NLG),是目前最大的Transformer模型,其可以在一系列自然语言处理任务上获得最先进的结果。
为了训练该模型,研究团队采用了微软的DeepSpeed分布式优化器和NVIDIA的Megatron并行语言模型,并使用16台NVIDIA DGX-2系统训练T-NLG,每台DGX-2系统由16个NVIDIA V100 Tensor Cores GPU组成,通过Mellanox的InfiniBand技术互连。
该模型旨在帮助自然语言处理(NLP)系统处理问答、会话代理和文档理解任务。
“更加先进的自然语言生成对于各种应用场景来说都是一种变革,例如其可以帮助作者编写内容、通过将一段长文本进行简短总结来帮助人们节省时间,或通过数字助手来改善客户体验。”
“像T-NLG这样的生成模型对于NLP任务非常重要,因为我们的目标是在任何情况下都能使其像人类一样直接、准确、流畅地做出反应,”微软的研究人员在一篇关于T-NLG中的博客中介绍到。
“以前,问答和总结系统都依赖于从文档中提取现有的内容,虽然这些文档可以作为回答或摘要的表单,但它们常常显得不自然或不连贯。使用T-NLG,我们可以自然地对个人文档或电子邮件进行总结,或回答其中的相关问题。”
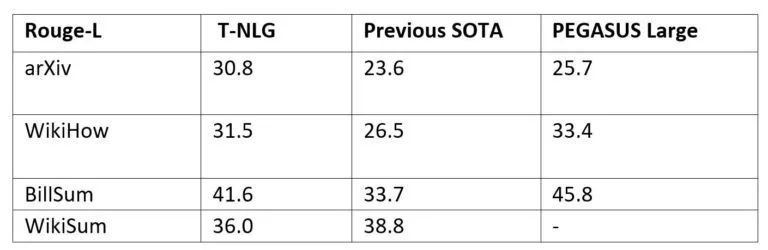
T-NLG与此前最先进模型的对比数据。来源:微软
微软此次训练的模型名为Turing Natural Language Generation(T-NLG),是目前最大的Transformer模型,其可以在一系列自然语言处理任务上获得最先进的结果。
为了训练该模型,研究团队采用了微软的DeepSpeed分布式优化器和NVIDIA的Megatron并行语言模型,并使用16台NVIDIA DGX-2系统训练T-NLG,每台DGX-2系统由16个NVIDIA V100 Tensor Cores GPU组成,通过Mellanox的InfiniBand技术互连。
该模型旨在帮助自然语言处理(NLP)系统处理问答、会话代理和文档理解任务。
“更加先进的自然语言生成对于各种应用场景来说都是一种变革,例如其可以帮助作者编写内容、通过将一段长文本进行简短总结来帮助人们节省时间,或通过数字助手来改善客户体验。”
“像T-NLG这样的生成模型对于NLP任务非常重要,因为我们的目标是在任何情况下都能使其像人类一样直接、准确、流畅地做出反应,”微软的研究人员在一篇关于T-NLG中的博客中介绍到。
“以前,问答和总结系统都依赖于从文档中提取现有的内容,虽然这些文档可以作为回答或摘要的表单,但它们常常显得不自然或不连贯。使用T-NLG,我们可以自然地对个人文档或电子邮件进行总结,或回答其中的相关问题。”
T-NLG与此前最先进模型的对比数据。来源:微软











