
RAPIDS 0.10现已推出!数据科学数十载的成果,人见人爱
2019-10-31 19:24
 分享到微信
分享到微信
 分享到微博
分享到微博
随着新版本的推出,RAPIDS 迎来了其推出一周年纪念日。回顾所经历的一年,RAPIDS团队就社区对该项目的关心和支持表示衷心的感谢。此前,RAPIDS获得了其首个BOSSIE奖。非常感谢各位的支持!RAPIDS团队将继续推动端对端数据科学加快发展,达到新高度。
RAPIDS团队在讨论0.10版本时思考了之前Wes Mckinney所写的一篇博客《Apache Arrow和“我最讨厌Pandas的10个问题”》。
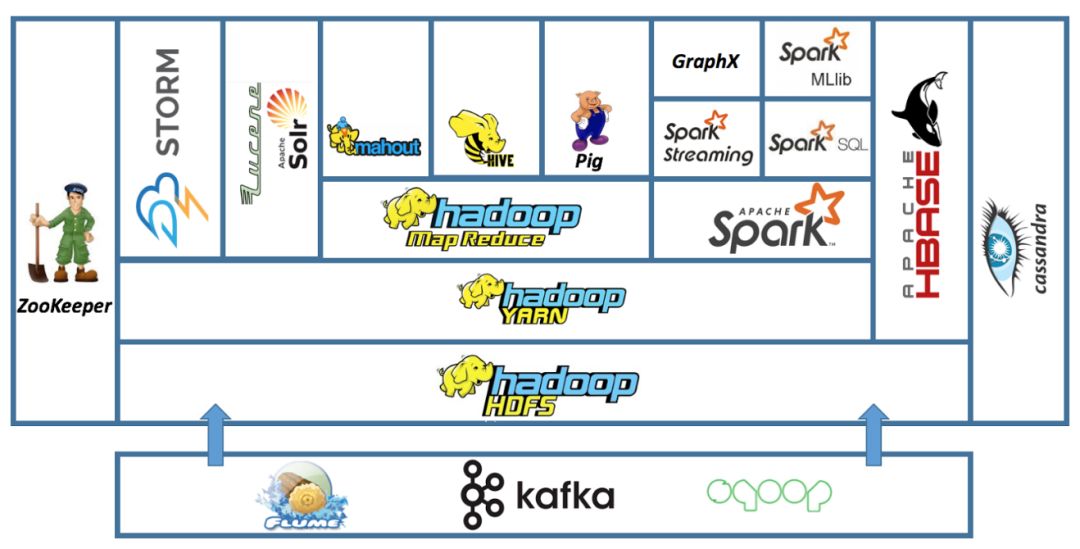
简单回顾一下数据科学的历史。十年前,组成今天大数据的许多要素相继出现 。在数据世界的一角,Hadoop生态诞生, Hadoop、Hive、Cassandra、Mahout等都在快速发展。

另一方面,数据科学家口中的PyData堆栈正在兴起。NetworkX(2005)、Numpy(2006)、Scikit-Learn(2007)和Pandas(2008)掀起了一波可用性浪潮;Hadoop、Hive、Cassandra、Flume、Pig和Spark将数据科学扩展到前所未有的水平。它们都在数据科学生态中加入了大量新的库、供应商以及几乎无数种构建数据管道方法,以解决数据科学的问题。
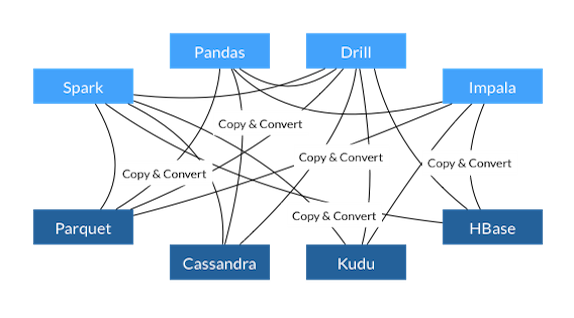
虽然新工具和工作流程的出现激动人心,但很少有人反过来思考在Apache Arrow之前,这些库和框架如何进行有效协作。因此,大多数数据科学家/工程师将大部分时间用于库之间的序列化和反序列化数据(大量副本和转换)。
RAPIDS结合了人们喜爱的众多库.、社区和框架的诸多优点,以及人们在大规模使用这些工具时经历过的困苦和烦恼。这些正面情绪与负面情绪引导RAPIDS生态解决了Wes讨厌的关于Pandas的10个问题(实际上是11个问题)等。
“我最讨厌Pandas的10个问题”列表
1、内部构件离“metal”太远;
2、不支持内存映射数据集;
3、数据库和文件摄取/导出性能不佳;
4、Warty缺少数据支持;
5、缺乏内存使用的透明度和RAM管理;
6、对分类数据的支持弱;
7、复杂的分组功能操作既笨拙又缓慢;
8、将数据附加到DataFrame很繁琐且成本高昂;
9、类型元数据有限且不可扩展;
10、急切的评估模式,无查询规划;
11、“慢”,多核算法处理较大数据集的能力有限。

RAPIDS并非独自解决这些问题;人们非常重视“生态”。没有加速发展的数据科学生态,就不可能有RAPIDS。首先,RAPIDS是基于 Apache Arrow构建的。Apache Arrow是一个用于内存中数据的跨语言开发平台。如果不是Apache项目及其贡献者,那么RAPIDS的构建将变得更加困难。然后,不要忘了Anaconda、Peter Wang和Travis Oliphant(为我们带来了许多促进其发展的PyData库)以及他们为了鼓励和突出PyData生态性能所做的一切。Numba(2012)为Python生态提供了一个JIT编译器。该编译器还可以针对RAPIDS在我们所有库中都大量使用的GPU。由于能够任意扩展功能并使用纯Python编写用户定义函数(UDF),因此Python生态系统具有许多其他语言所没有的优势。
另外还有Python原生调度程序Dask(2014)。该程序可在整个Python生态中使用,并几乎与所有调度程序(包括Slurm、Kubernetes和Yarn)存在关联。GoAi(2017)聚集了多位GPU分析领域的开拓者构建RAPIDS基础的原型并制定GPU库之间的通信和互操作标准。最后,在互操作性方面,许多CUDA Python数组和深度学习库(PyTorch、 MxNet、 Chainer、 CuPy和即将推出的 PaddlePaddle)采用DLPack和CUDA_Array_Interface(希望能够有更多)。所有这些在RAPIDS生态中连接的库一起实现了新库的快速创建,例如cuSpatial、pyBlazing、cuXFilter和GFD(下文将作进一步的介绍),并且这种趋势还将继续。
就我个人而言,这也是我最喜欢RAPIDS的地方 —— 实现了Python生态GPU的民主化,使其他人能够以前所未有的速度构建具有多种功能的高性能库。为了凑满一张“10大”列表,我还要求每个RAPIDS库的领导者说出他们对RAPIDS的喜爱之处(您会发现他们之前一定花了很多时间互相串通回答,因为他们许多人的回答都相同)。
RAPIDS库十大领先之处
Keith Kraus:
---- 速度 —— 核心功能“靠近metal”;
---- GPU生态互操作性;
---- PyData生态互操作性;
---- 强大的内存布局语义;
---- 低级别访问和控制(用户可以在需要时获取指向其数据的裸指针);
---- 开源;
---- 深度学习框架集成;
---- 遵循已知的PyData 应用编程接口(API);
---- 通过BlazingSQL实现的结构化查询语言(SQL)。
John Zedlewski:
---- 我记得以前每天要 花好几个小时等待大型集群上的机器学习工作批量完成,所以每次看到台式机能够在几秒钟内完成如此大型的工作我都很高兴!
Bartley Richardson:
---- 对于专门研究某个领域 (例如网络安全和信息安全)的数据科学家而言,其他Python工具之间的互操作性至关重要。我们不但受益于更快的数据分析(通常是网络安全中的TB+级数据集),同时还能与安全分析人员所依赖的域专属下游Python软件包和API保持互操作性,这真的是太棒了。
Mark Harris:
---- 我们的团队太出色了。RAPIDS团队是一个由充满热情、能力出众的人组成的一支多元化分布式团队。尽管我们分布在世界各地,我们中的许多人在家工作,但我们的团队可以通过公开交流和合作建立新的功能并以惊人的速度解决问题。每个人都积极地提供帮助,而经常逼迫自己接触自己专业领域以外的东西以学习新的技能。我们觉得做这件事情十分快乐。
Brad Rees:
---- ETL、数据工程、机器学习和图表分析之间实现了无缝过渡。RAPIDS让数据科学家只需要考虑分析即可,而无需考虑如何在工具之间移动数据。
Matt Rocklin:
---- 我喜欢RAPIDS符合标准的Python API,这样就可以轻松地与现有的Python生态系统集成;
---- 我喜欢RAPIDS为许多其他Python软件包做出了贡献,而不是只管自己;
---- 我喜欢RAPIDS让用户可以轻松、快速地尝试各种硬件,而不必学习新系统;
---- 我喜欢RAPIDS使新科学领域的发展速度加快,而不仅仅是增加深度学习功能。
RAPIDS核心库更新
cuDF
cuDF在过去一年中的发展速度非常之快。每个版本都加入了令人兴奋的新功能、优化和错误修复。0.10版本也不例外。cuDF 0.10版本的一些新功能包括 `groupby.quantile()`、`Series.isin()`、从远程/云文件系统(例如hdfs、gcs、s3)读取、Series和DataFrame `isna()`、按分组功能中的任意长度Series分组 、Series 协方差和Pearson相关性以及从DataFrame / Series `.values` 属性返回 CuPy数组。此外,`apply` UDF函数API经过了优化,并且加入了通过`.iloc`访问器的收集和散播方法。
除了提供所有上述出色的功能、优化和错误修复之外,cuDF 0.10版本还花费大量的精力构建未来。该版本将cuStrings存储库合并到cuDF中,并为合并两个代码库做好了准备,使字符串功能能够被更紧密地集成到cuDF中,以此提供更快的加速和更多的功能。此外,RAPIDS添加了cuStreamz元数据包,因此可以使用cuDF和Streamz库简化GPU加速流处理。cuDF继续改进其Pandas API兼容性和Dask DataFrame互操作性,使我们的用户可以最大程度地无缝使用cuDF。
在幕后,libcudf的内部架构正在经历一次重大的重新设计。0.10版本加入了最新的cudf :: column和cudf :: table类,这些类大大提高了内存所有权控制的强健性,并为将来支持可变大小数据类型(包括字符串列、数组和结构)奠定了基础。由于已构建对整个libcudf API中的新类的支持,这项工作将在下一个版本周期中继续进行。此外,libcudf 0.10添加了许多新的API和算法,包括基于排序、支持空数据的分组功能、分组功能分位数和中位数、cudf :: unique_count,cudf :: repeat、cudf :: scatter_to_tables等。与以往一样,此版本还包括许多其他改进和修复。
RAPIDS内存管理器库RMM也正在进行一系列重组。这次重组包括一个基于内存资源的新架构,该架构与C ++ 17 std :: pmr :: memory_resource大多兼容。这使该库更容易在公共接口之后添加新类型的内存分配器。0.10还用Cython取代了CFFI Python绑定,从而使C ++异常可以传播到Python异常,使更多可调整的错误被传递给应用程序。下一个版本将继续提高RMM中的异常支持。
cuML 和 XGBoost
RAPIDS团队开始为GPU加速XGBoost(最流行的梯度渐变决策树库之一)做出贡献时承诺将所有改进上游移至主存储库而不是创建长期运行的fork。RAPIDS团队高兴地宣布,0.10版本随附一个完全基于XGBoost主分支的XGBoost conda软件包。这是一个快照版本,该版本包含即将发布的1.0.0 XGBoost版本中的许多功能。它支持将数据从cuDF DataFrames加载到XGBoost时的透明性,并且提供更加简洁的全新Dask API选项(详细信息请参见XGBoost存储库)。目前已弃用较旧的Dask-XGBoost API,但它仍可以与RAPIDS 0.10配合使用。为了简化下载,目前XGBoost的conda软件包(rapids-xgboost)已被包含在主要的Rapidsai conda通道中,如果你安装了RAPIDS conda元软件包,就会自动安装 conda软件包(详细信息请参见入门页面)。

对比:Intel Xeon E5–2698 v4 CPU(20核)与NVIDIA V100
RAPIDS机器学习库cuML 扩展后支持多种流行的机器学习算法。cuML现在包含一个支持向量机分类器(SVC)模型,其速度比同等CPU版本快300倍。它在CannyLabs的GPU加速工作基础上建立一个加速TSNE模型,该模型提供最受欢迎的高性能降维方法,同时其运行速度比基于CPU的模型快1000倍。我们随机森林模型的每个版本都在不断改进,并且现在包含了一个分层算法,其速度比scikit-learn的随机森林训练快30倍。
Dask
Dask在HPC和Kubernetes系统上实现了标准化部署,包括支持与客户端分开运行调度程序,从而使用户可以在本地笔记本计算机上轻松地启动远程集群上的计算。Dask还为使用云但无法采用Kubernetes的机构添加了AWS ECS原生支持。
UCX上的高性能通信开发仍在继续,包括使用NVLINK的单个节点中的GPU以及使用InfiniBand的集群中的多个节点。RAPIDS团队已将ucx-py绑定重写,使其变得更简洁,并解决了跨Python-GPU库(如Numba、RAPIDS和UCX)共享内存管理方面的多个问题。
cuGraph
cuGraph已在将领先的图形框架集成到一个简单易用的接口方面迈出了新的一步。几个月前,RAPIDS收到了来自佐治亚理工学院的Hornet副本,并将其重构和重命名为cuHornet。这一名称更改表明,源代码已偏离Georgia Tech基准并体现了代码API和数据结构与RAPIDS cuGraph的匹配。cuHornet的加入提供了基于边界的编程模型、动态数据结构以及现有分析的列表。除了核心数函数之外,可用的前两个cuHornet算法是Katz centrality 和K-Cores。
cuSpatial
RAPIDS 0.10还包括cuSpatial的初始版本。cuSpatial是一个高效C ++库,它被用于使用CUDA和cuDF的GPU加速地理空间分析。该库包含供数据科学家使用的python绑定。cuSpatial比现有算法实现的速度提高了50倍以上并且还在开发中。cuSpatial的初始版本包括用于计算轨迹聚类、距离和速度、hausdorff和hasrsine距离、空间窗口投影、多边形中的点以及窗口相交的GPU加速算法。在未来版本中,将有计划地添加shapefile支持和四叉树索引。
cuDataShader
发布该RAPIDS版本的同时,RAPIDS还发布了cuDataShader GPU加速和cuDF支持端口。该端口用于高性能的Datashader。凭借快速、大规模的数据可视化功能及其围绕python的设计,Datashader非常适合与GPU驱动的viz一起使用。我们的第一个版本实现了大约50倍的速度。基于这些结果,将在下一个版本中将GPU功能加入到Datashader本身 !因此请继续关注该产品。如果您想尝试,最简单的方法就是在我们的另一个Viz库cuXfilter中使用它。
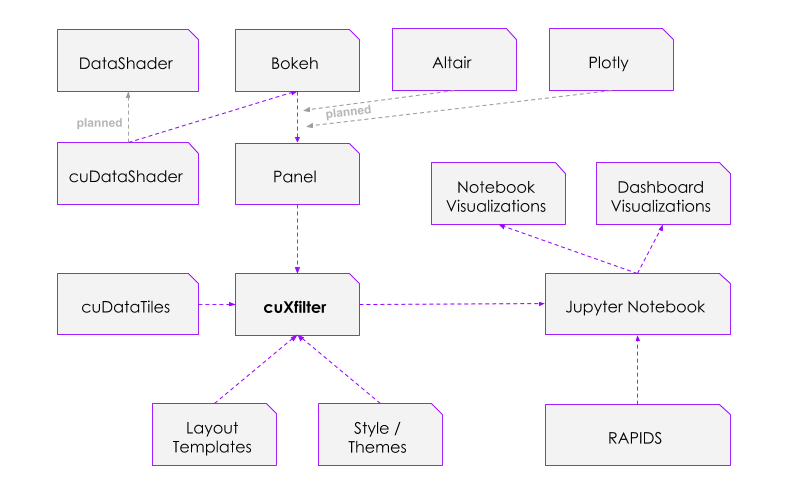
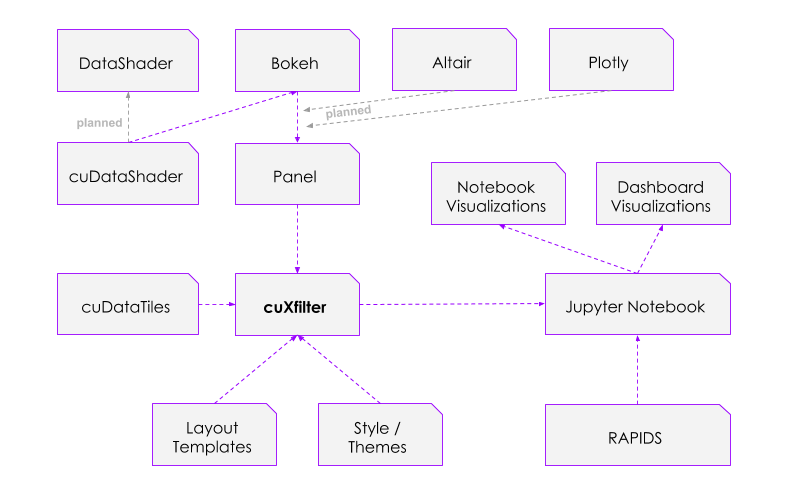
cuXfilter
cuXfilter被用于支持我们的按揭虚拟化演示(新的链接位于此处),在经过完全重构后,其交叉过滤仪表板的安装和创建变得更加简单,而所有这些工作都可以通过python笔记本计算机完成!由于网络上有许多出色的可视化库,因此我们一般不创建自己的图表库,而是通过更快的加速、更大的数据集和更好的开发用户体验来增强其他图表库,这是为了消除将多个图表互连到GPU后端的麻烦,使你可以更快地以可视化方式浏览数据。
RAPIDS社区
用户对生态的贡献是最大的。BlazingSQL刚刚发布了V0.4.5,该版本在GPU上的运行速度更快,并且加入了新的基准测试。和GCP上的TPC-H查询从本地NVME和GCS提取数据的情况相比,该基准测试能够查询600M行。ensemblecap.ai的Ritchie Ng发布了使用RAPIDS cuDF的分数差分(GFD)GPU 实现方法,该实现方法的速度比CPU高出100倍以上。
在接下来的几个月时间,RAPIDS工程团队将在全球各地的活动、会议和编程马拉松上进行演示并提供教程。加入我们的GTC DC、PyData NYC和PyData LA。RAPIDS团队希望与你共同努力,不断完善RAPIDS。
RAPIDS团队在讨论0.10版本时思考了之前Wes Mckinney所写的一篇博客《Apache Arrow和“我最讨厌Pandas的10个问题”》。
简单回顾一下数据科学的历史。十年前,组成今天大数据的许多要素相继出现 。在数据世界的一角,Hadoop生态诞生, Hadoop、Hive、Cassandra、Mahout等都在快速发展。
另一方面,数据科学家口中的PyData堆栈正在兴起。NetworkX(2005)、Numpy(2006)、Scikit-Learn(2007)和Pandas(2008)掀起了一波可用性浪潮;Hadoop、Hive、Cassandra、Flume、Pig和Spark将数据科学扩展到前所未有的水平。它们都在数据科学生态中加入了大量新的库、供应商以及几乎无数种构建数据管道方法,以解决数据科学的问题。
虽然新工具和工作流程的出现激动人心,但很少有人反过来思考在Apache Arrow之前,这些库和框架如何进行有效协作。因此,大多数数据科学家/工程师将大部分时间用于库之间的序列化和反序列化数据(大量副本和转换)。
RAPIDS结合了人们喜爱的众多库.、社区和框架的诸多优点,以及人们在大规模使用这些工具时经历过的困苦和烦恼。这些正面情绪与负面情绪引导RAPIDS生态解决了Wes讨厌的关于Pandas的10个问题(实际上是11个问题)等。
“我最讨厌Pandas的10个问题”列表
1、内部构件离“metal”太远;
2、不支持内存映射数据集;
3、数据库和文件摄取/导出性能不佳;
4、Warty缺少数据支持;
5、缺乏内存使用的透明度和RAM管理;
6、对分类数据的支持弱;
7、复杂的分组功能操作既笨拙又缓慢;
8、将数据附加到DataFrame很繁琐且成本高昂;
9、类型元数据有限且不可扩展;
10、急切的评估模式,无查询规划;
11、“慢”,多核算法处理较大数据集的能力有限。
RAPIDS并非独自解决这些问题;人们非常重视“生态”。没有加速发展的数据科学生态,就不可能有RAPIDS。首先,RAPIDS是基于 Apache Arrow构建的。Apache Arrow是一个用于内存中数据的跨语言开发平台。如果不是Apache项目及其贡献者,那么RAPIDS的构建将变得更加困难。然后,不要忘了Anaconda、Peter Wang和Travis Oliphant(为我们带来了许多促进其发展的PyData库)以及他们为了鼓励和突出PyData生态性能所做的一切。Numba(2012)为Python生态提供了一个JIT编译器。该编译器还可以针对RAPIDS在我们所有库中都大量使用的GPU。由于能够任意扩展功能并使用纯Python编写用户定义函数(UDF),因此Python生态系统具有许多其他语言所没有的优势。
另外还有Python原生调度程序Dask(2014)。该程序可在整个Python生态中使用,并几乎与所有调度程序(包括Slurm、Kubernetes和Yarn)存在关联。GoAi(2017)聚集了多位GPU分析领域的开拓者构建RAPIDS基础的原型并制定GPU库之间的通信和互操作标准。最后,在互操作性方面,许多CUDA Python数组和深度学习库(PyTorch、 MxNet、 Chainer、 CuPy和即将推出的 PaddlePaddle)采用DLPack和CUDA_Array_Interface(希望能够有更多)。所有这些在RAPIDS生态中连接的库一起实现了新库的快速创建,例如cuSpatial、pyBlazing、cuXFilter和GFD(下文将作进一步的介绍),并且这种趋势还将继续。
就我个人而言,这也是我最喜欢RAPIDS的地方 —— 实现了Python生态GPU的民主化,使其他人能够以前所未有的速度构建具有多种功能的高性能库。为了凑满一张“10大”列表,我还要求每个RAPIDS库的领导者说出他们对RAPIDS的喜爱之处(您会发现他们之前一定花了很多时间互相串通回答,因为他们许多人的回答都相同)。
RAPIDS库十大领先之处
Keith Kraus:
---- 速度 —— 核心功能“靠近metal”;
---- GPU生态互操作性;
---- PyData生态互操作性;
---- 强大的内存布局语义;
---- 低级别访问和控制(用户可以在需要时获取指向其数据的裸指针);
---- 开源;
---- 深度学习框架集成;
---- 遵循已知的PyData 应用编程接口(API);
---- 通过BlazingSQL实现的结构化查询语言(SQL)。
John Zedlewski:
---- 我记得以前每天要 花好几个小时等待大型集群上的机器学习工作批量完成,所以每次看到台式机能够在几秒钟内完成如此大型的工作我都很高兴!
Bartley Richardson:
---- 对于专门研究某个领域 (例如网络安全和信息安全)的数据科学家而言,其他Python工具之间的互操作性至关重要。我们不但受益于更快的数据分析(通常是网络安全中的TB+级数据集),同时还能与安全分析人员所依赖的域专属下游Python软件包和API保持互操作性,这真的是太棒了。
Mark Harris:
---- 我们的团队太出色了。RAPIDS团队是一个由充满热情、能力出众的人组成的一支多元化分布式团队。尽管我们分布在世界各地,我们中的许多人在家工作,但我们的团队可以通过公开交流和合作建立新的功能并以惊人的速度解决问题。每个人都积极地提供帮助,而经常逼迫自己接触自己专业领域以外的东西以学习新的技能。我们觉得做这件事情十分快乐。
Brad Rees:
---- ETL、数据工程、机器学习和图表分析之间实现了无缝过渡。RAPIDS让数据科学家只需要考虑分析即可,而无需考虑如何在工具之间移动数据。
Matt Rocklin:
---- 我喜欢RAPIDS符合标准的Python API,这样就可以轻松地与现有的Python生态系统集成;
---- 我喜欢RAPIDS为许多其他Python软件包做出了贡献,而不是只管自己;
---- 我喜欢RAPIDS让用户可以轻松、快速地尝试各种硬件,而不必学习新系统;
---- 我喜欢RAPIDS使新科学领域的发展速度加快,而不仅仅是增加深度学习功能。
RAPIDS核心库更新
cuDF
cuDF在过去一年中的发展速度非常之快。每个版本都加入了令人兴奋的新功能、优化和错误修复。0.10版本也不例外。cuDF 0.10版本的一些新功能包括 `groupby.quantile()`、`Series.isin()`、从远程/云文件系统(例如hdfs、gcs、s3)读取、Series和DataFrame `isna()`、按分组功能中的任意长度Series分组 、Series 协方差和Pearson相关性以及从DataFrame / Series `.values` 属性返回 CuPy数组。此外,`apply` UDF函数API经过了优化,并且加入了通过`.iloc`访问器的收集和散播方法。
除了提供所有上述出色的功能、优化和错误修复之外,cuDF 0.10版本还花费大量的精力构建未来。该版本将cuStrings存储库合并到cuDF中,并为合并两个代码库做好了准备,使字符串功能能够被更紧密地集成到cuDF中,以此提供更快的加速和更多的功能。此外,RAPIDS添加了cuStreamz元数据包,因此可以使用cuDF和Streamz库简化GPU加速流处理。cuDF继续改进其Pandas API兼容性和Dask DataFrame互操作性,使我们的用户可以最大程度地无缝使用cuDF。
在幕后,libcudf的内部架构正在经历一次重大的重新设计。0.10版本加入了最新的cudf :: column和cudf :: table类,这些类大大提高了内存所有权控制的强健性,并为将来支持可变大小数据类型(包括字符串列、数组和结构)奠定了基础。由于已构建对整个libcudf API中的新类的支持,这项工作将在下一个版本周期中继续进行。此外,libcudf 0.10添加了许多新的API和算法,包括基于排序、支持空数据的分组功能、分组功能分位数和中位数、cudf :: unique_count,cudf :: repeat、cudf :: scatter_to_tables等。与以往一样,此版本还包括许多其他改进和修复。
RAPIDS内存管理器库RMM也正在进行一系列重组。这次重组包括一个基于内存资源的新架构,该架构与C ++ 17 std :: pmr :: memory_resource大多兼容。这使该库更容易在公共接口之后添加新类型的内存分配器。0.10还用Cython取代了CFFI Python绑定,从而使C ++异常可以传播到Python异常,使更多可调整的错误被传递给应用程序。下一个版本将继续提高RMM中的异常支持。
cuML 和 XGBoost
RAPIDS团队开始为GPU加速XGBoost(最流行的梯度渐变决策树库之一)做出贡献时承诺将所有改进上游移至主存储库而不是创建长期运行的fork。RAPIDS团队高兴地宣布,0.10版本随附一个完全基于XGBoost主分支的XGBoost conda软件包。这是一个快照版本,该版本包含即将发布的1.0.0 XGBoost版本中的许多功能。它支持将数据从cuDF DataFrames加载到XGBoost时的透明性,并且提供更加简洁的全新Dask API选项(详细信息请参见XGBoost存储库)。目前已弃用较旧的Dask-XGBoost API,但它仍可以与RAPIDS 0.10配合使用。为了简化下载,目前XGBoost的conda软件包(rapids-xgboost)已被包含在主要的Rapidsai conda通道中,如果你安装了RAPIDS conda元软件包,就会自动安装 conda软件包(详细信息请参见入门页面)。
对比:Intel Xeon E5–2698 v4 CPU(20核)与NVIDIA V100
RAPIDS机器学习库cuML 扩展后支持多种流行的机器学习算法。cuML现在包含一个支持向量机分类器(SVC)模型,其速度比同等CPU版本快300倍。它在CannyLabs的GPU加速工作基础上建立一个加速TSNE模型,该模型提供最受欢迎的高性能降维方法,同时其运行速度比基于CPU的模型快1000倍。我们随机森林模型的每个版本都在不断改进,并且现在包含了一个分层算法,其速度比scikit-learn的随机森林训练快30倍。
Dask
Dask在HPC和Kubernetes系统上实现了标准化部署,包括支持与客户端分开运行调度程序,从而使用户可以在本地笔记本计算机上轻松地启动远程集群上的计算。Dask还为使用云但无法采用Kubernetes的机构添加了AWS ECS原生支持。
UCX上的高性能通信开发仍在继续,包括使用NVLINK的单个节点中的GPU以及使用InfiniBand的集群中的多个节点。RAPIDS团队已将ucx-py绑定重写,使其变得更简洁,并解决了跨Python-GPU库(如Numba、RAPIDS和UCX)共享内存管理方面的多个问题。
cuGraph
cuGraph已在将领先的图形框架集成到一个简单易用的接口方面迈出了新的一步。几个月前,RAPIDS收到了来自佐治亚理工学院的Hornet副本,并将其重构和重命名为cuHornet。这一名称更改表明,源代码已偏离Georgia Tech基准并体现了代码API和数据结构与RAPIDS cuGraph的匹配。cuHornet的加入提供了基于边界的编程模型、动态数据结构以及现有分析的列表。除了核心数函数之外,可用的前两个cuHornet算法是Katz centrality 和K-Cores。
cuSpatial
RAPIDS 0.10还包括cuSpatial的初始版本。cuSpatial是一个高效C ++库,它被用于使用CUDA和cuDF的GPU加速地理空间分析。该库包含供数据科学家使用的python绑定。cuSpatial比现有算法实现的速度提高了50倍以上并且还在开发中。cuSpatial的初始版本包括用于计算轨迹聚类、距离和速度、hausdorff和hasrsine距离、空间窗口投影、多边形中的点以及窗口相交的GPU加速算法。在未来版本中,将有计划地添加shapefile支持和四叉树索引。
cuDataShader
发布该RAPIDS版本的同时,RAPIDS还发布了cuDataShader GPU加速和cuDF支持端口。该端口用于高性能的Datashader。凭借快速、大规模的数据可视化功能及其围绕python的设计,Datashader非常适合与GPU驱动的viz一起使用。我们的第一个版本实现了大约50倍的速度。基于这些结果,将在下一个版本中将GPU功能加入到Datashader本身 !因此请继续关注该产品。如果您想尝试,最简单的方法就是在我们的另一个Viz库cuXfilter中使用它。
cuXfilter
cuXfilter被用于支持我们的按揭虚拟化演示(新的链接位于此处),在经过完全重构后,其交叉过滤仪表板的安装和创建变得更加简单,而所有这些工作都可以通过python笔记本计算机完成!由于网络上有许多出色的可视化库,因此我们一般不创建自己的图表库,而是通过更快的加速、更大的数据集和更好的开发用户体验来增强其他图表库,这是为了消除将多个图表互连到GPU后端的麻烦,使你可以更快地以可视化方式浏览数据。
RAPIDS社区
用户对生态的贡献是最大的。BlazingSQL刚刚发布了V0.4.5,该版本在GPU上的运行速度更快,并且加入了新的基准测试。和GCP上的TPC-H查询从本地NVME和GCS提取数据的情况相比,该基准测试能够查询600M行。ensemblecap.ai的Ritchie Ng发布了使用RAPIDS cuDF的分数差分(GFD)GPU 实现方法,该实现方法的速度比CPU高出100倍以上。
在接下来的几个月时间,RAPIDS工程团队将在全球各地的活动、会议和编程马拉松上进行演示并提供教程。加入我们的GTC DC、PyData NYC和PyData LA。RAPIDS团队希望与你共同努力,不断完善RAPIDS。




