
RAPIDS 0.9 现已推出:构建了许多新的算法
2019-09-10 14:50
 分享到微信
分享到微信
 分享到微博
分享到微博
我喜欢用歌曲、体育、电影和电视节目做比喻。RAPIDS 0.9 的推出让我想起了另一个关于“9”的经典作品——《星际迷航:深空九号》(DS9),在我们的团队中,有不少成员都是这部电视剧的粉丝。其中有很多台词都能很好地用来形容RAPIDS。例如:
Gowron: “想想看吧!五年前,没有人听说过Bajor或是深空九号,而现在,它们寄托着我们所有的希望。”
五年前,还没有人把NVIDIA与数据科学联系起来。现在,我们持续扩展数据科学,并把所有希望都寄托在了RAPIDS上。计算平台不是一夜之间就能建立起来的,就像DS9一样,这将需要积年累月的时间,而最好的结果也终将到来!
RAPIDS 0.9是一个令人兴奋的飞跃,它构建了许多新的算法,既可以在一个节点中扩展到更多的GPU,也可以扩展到多个GPU节点。
cuGRAPH
cuGraph是RAPIDS的图形分析库,针对cuGraph我们推出了一个由两个新原语支持的多GPU PageRank算法:这是一个COO到CSR的多GPU数据转换器,和一个计算顶点度的函数。这些原语会被用于将源和目标边缘列从Dask Dataframe转换为图形格式,并使PageRank能够跨越多个GPU进行缩放。
下图显示了新的多GPU PageRank算法的性能。与之前的PageRank基准运行时刻不同,这些运行时刻只是测量PageRank解算器的性能。这组运行时刻包括Dask DataFrame到CSR的转换、PageRank执行以及从CSR返回到DataFrame的结果转换。平均结果显示,新的多GPU PageRank分析比100节点Spark集群快10倍以上。
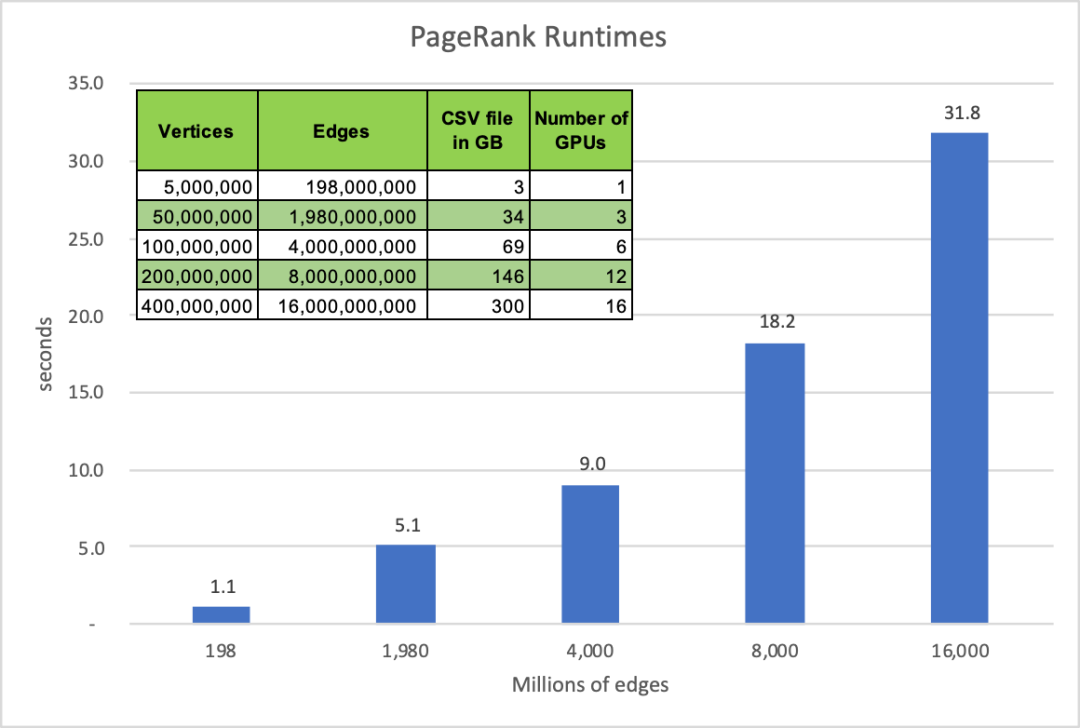
图1:cuGraph PageRank在不同数量的边缘和NVIDIA Tesla V 100上计算所用的时间
下图仅查看Bigdata数据集、5000万个顶点和19.8亿条边,并运行HiBench端到端测试。HiBench基准运行时刻包括数据读取、运行PageRank,然后得到所有顶点的得分。此前,HiBench分别在10、20、50和100个节点的Google GCP上进行了测试。

图2:5千万边缘端到端PageRank运行时刻,cuGraph PageRank vs Spark Graph(越低越好)
cuGraph 0.9还包括了一个新的单GPU强连接组件功能。
cuML
cuML 是RAPIDS 的机器学习库。0.9版的推出,为cuML带来了两个重要的里程碑。cuML 0.9包含了第一个新的基于多节点、多GPU框架的算法:cuML-MG。cuML-MG将DASK框架的易用性与高度优化的OpenUCX和NCCL库结合起来,用于关键性能的数据传输。k-均值聚类(k-Means clustering)是建立在该库上的第一个算法。它提供了一个大家熟悉的scikit-learn-style API,但是使用以太网或Infiniband在GPU和节点上几乎是线性扩展的。通过两台DGX-1服务器,k -Means-MG可以将大型集群问题的运行时间从CPU上的630秒缩短到GPU上的7.1秒。
cuML 0.9扩展了随机森林训练,增加了对回归模型的支持,以及一种新的分层树构建算法,可以更有效地扩展到deep tree。0.9版还提供了针对于多节点、多GPU随机森林建筑的初始支持。通过多GPU支持,使用单个NVIDIA DGX-1训练森林模型,可以比双CPU、40-core节点快56倍。
从cuML 训练到推理
不仅是训练,要想真正在GPU上扩展数据科学,也需要加速端到端的应用程序。cuML 0.9 为我们带来了基于GPU的树模型支持的下一个发展,包括新的森林推理库(FIL)。FIL是一个轻量级的GPU加速引擎,它对基于树形模型进行推理,包括梯度增强决策树和随机森林。使用单个V100 GPU和两行Python代码,用户就可以加载一个已保存的XGBoost或LightGBM模型,并对新数据执行推理,速度比双20核CPU节点快36倍。在开源Treelite软件包的基础上,下一个版本的FIL还将添加对scikit-learn和cuML随机森林模型的支持。

图3:推理速度对比,XGBoost CPU vs 森林推理库 (FIL) GPU
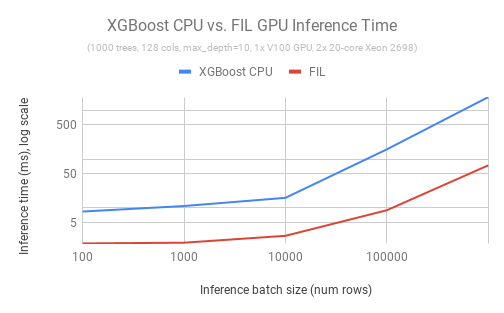
图4:XGBoost CPU和FIL推理时间随批处理大小的增加而扩展(越低越好)
将来,cuML还将支持GPU上其他算法的推理。
XGBoost & Interoperability
RAPIDS的目标是支持一个蓬勃发展的GPU加速数据科学软件生态系统,与这些数据科学软件协同工作以实现端到端的计算。其中的一个例子就是XGBoost。RAPIDS为继续支持XGBoost而感到自豪,XGBoost是构建决策树状模型最流行的软件包之一。RAPIDS团队开发了一个新的GPU-XGBoost桥接器,它允许用户无缝地从cuDF dataframe移动到XGBoost训练,而无需通过CPU内存传递数据。桥接器利用开放式__cuda_array_interface__ 接口标准来实现从cuDF的高性能传输,并在不久的将来扩展到其他支持__cuda_array_interface__ 接口标准的库。这一变化是对XGBoost上游的贡献,将在即将发布的1.0版本中推出。
Dataframe Features Galore
cuDF是RAPIDS 的数据结构库基于 Apache Arrow搭建的,0.9版本中增加了关键性功能,包括:打印格式、时间支持、类别支持和生态系统互操作性。其中的一些亮点有:
---- 打印格式:可以在控制台或笔记本上完美地打印cuDF系列和DataFrames,类似于Pandas。
---- 扩展了时间支持,包含从纳秒到秒粒度的时间单位。
---- 用于分类列的字典现在保存在GPU上,新的API增加了cuDF Pandas的兼容性。
---- cuDF 0.9为生态系统互操作性增加了更多的桥梁,包括对具有新mask属性的__cuda_array_interface__支持,以及对基于NEP18的cuDF对象的__array_function__ 协议支持。
---- 值得注意的是,dask-cuDF现在与cuDF存储库合并,为ETL提供了一个单一的代码库(尽管这对于下载RAPIDS conda包的用户来说是一个透明的更改)。
在RAPIDS ETL hood 下面是libcudf、C++和CUDA库,提供了cuDF的高性能GPU实现。libcudf 0.9增加了一个新的GPU加速的Apache Avro读卡器,以及对其他读卡器的改进,例如更广泛的输入类型支持、在CSV中解析十六进制数字以及更好的ORC时间戳支持。0.9版还添加了新的算法,如用于合并已排序列的cudf::merge 和cudf::upper_bound 和cudf::lower_bound,这些算法允许在已排序列和表上并行搜索键数组(通过searchsorted在Python中公开)。这个版本还添加了列上的平均值、标准偏差和方差聚合(cuDF系列)。cudf::apply_boolean_mask 和cudf::drop_nulls 现在对整个表(DataFrame)而不是单个列(Series)进行操作。cudf::is_sorted 检查表/ DataFrame是否排序,cudf::nans_to_nulls 启用将浮点NaN值转换为空位掩码。
此外,cudf::rolling_window 现在支持即时(JIT)编译用户定义函数(UDF)。Python cuDF接口允许你将numba @cudajit 函数作为一个UDF传递给滚动窗口。在下面,cuDF从numba获取函数的PTX汇编代码,将其注入滚动窗口CUDA内核,JIT编译它并执行。编译后的代码被高速缓存以获得高性能的重复调用。这是在cuDF 0.8中为二进制操作和cudf::transform 添加的方法的一个概括。
最后,你会注意到cuDF在这个版本中速度有了显著提升,包括join(最多11倍)、gather和scatter on tables(速度也快2-3倍)的大幅性能改进,以及更多如图5所示的内容。
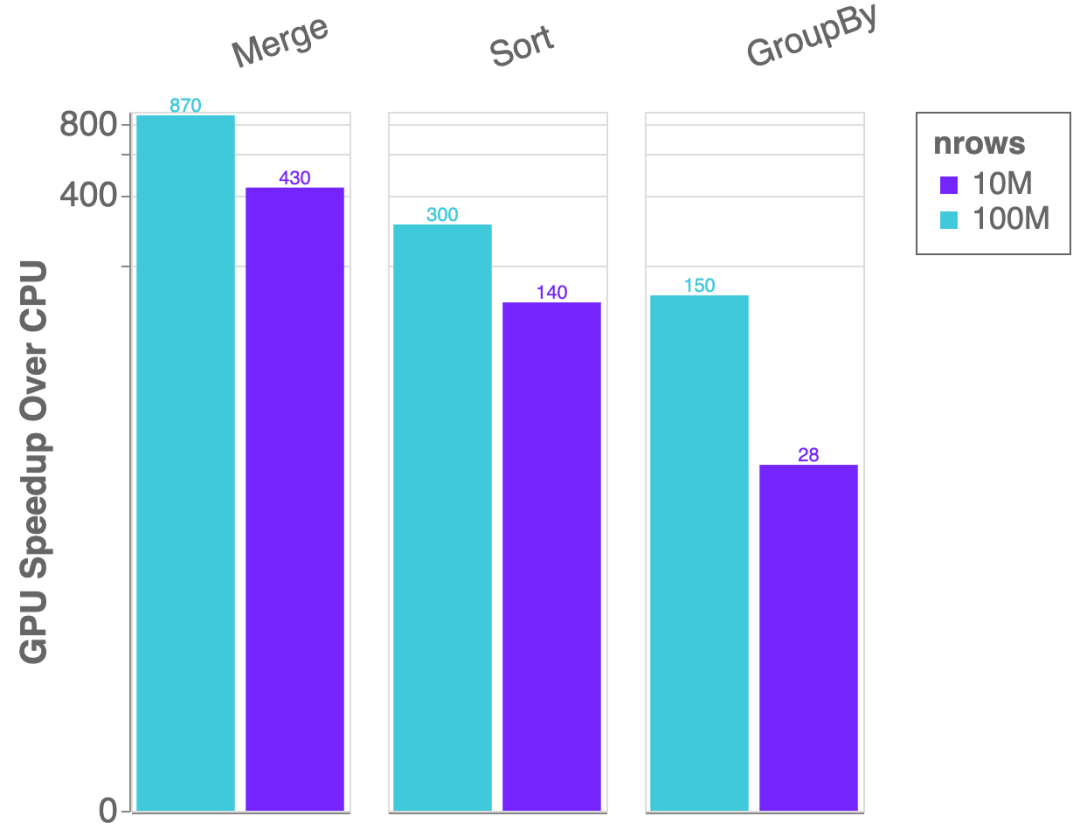
图5:单个NVIDIA Tesla V100 GPU与双路Intel Xeon E5–2698 v4 CPU(20核)上的cuDF vs Pandas加速
RAPIDS生态系统
在接下来的几个月里,RAPIDS工程团队将在全球各地的本地会议、会议和骇客大会上进行大量的演示和指导。我们希望有更多的人能够在会议或当地活动中轻松展示RAPIDS内容。
Gowron: “想想看吧!五年前,没有人听说过Bajor或是深空九号,而现在,它们寄托着我们所有的希望。”
五年前,还没有人把NVIDIA与数据科学联系起来。现在,我们持续扩展数据科学,并把所有希望都寄托在了RAPIDS上。计算平台不是一夜之间就能建立起来的,就像DS9一样,这将需要积年累月的时间,而最好的结果也终将到来!
RAPIDS 0.9是一个令人兴奋的飞跃,它构建了许多新的算法,既可以在一个节点中扩展到更多的GPU,也可以扩展到多个GPU节点。
cuGRAPH
cuGraph是RAPIDS的图形分析库,针对cuGraph我们推出了一个由两个新原语支持的多GPU PageRank算法:这是一个COO到CSR的多GPU数据转换器,和一个计算顶点度的函数。这些原语会被用于将源和目标边缘列从Dask Dataframe转换为图形格式,并使PageRank能够跨越多个GPU进行缩放。
下图显示了新的多GPU PageRank算法的性能。与之前的PageRank基准运行时刻不同,这些运行时刻只是测量PageRank解算器的性能。这组运行时刻包括Dask DataFrame到CSR的转换、PageRank执行以及从CSR返回到DataFrame的结果转换。平均结果显示,新的多GPU PageRank分析比100节点Spark集群快10倍以上。
图1:cuGraph PageRank在不同数量的边缘和NVIDIA Tesla V 100上计算所用的时间
下图仅查看Bigdata数据集、5000万个顶点和19.8亿条边,并运行HiBench端到端测试。HiBench基准运行时刻包括数据读取、运行PageRank,然后得到所有顶点的得分。此前,HiBench分别在10、20、50和100个节点的Google GCP上进行了测试。
图2:5千万边缘端到端PageRank运行时刻,cuGraph PageRank vs Spark Graph(越低越好)
cuGraph 0.9还包括了一个新的单GPU强连接组件功能。
cuML
cuML 是RAPIDS 的机器学习库。0.9版的推出,为cuML带来了两个重要的里程碑。cuML 0.9包含了第一个新的基于多节点、多GPU框架的算法:cuML-MG。cuML-MG将DASK框架的易用性与高度优化的OpenUCX和NCCL库结合起来,用于关键性能的数据传输。k-均值聚类(k-Means clustering)是建立在该库上的第一个算法。它提供了一个大家熟悉的scikit-learn-style API,但是使用以太网或Infiniband在GPU和节点上几乎是线性扩展的。通过两台DGX-1服务器,k -Means-MG可以将大型集群问题的运行时间从CPU上的630秒缩短到GPU上的7.1秒。
cuML 0.9扩展了随机森林训练,增加了对回归模型的支持,以及一种新的分层树构建算法,可以更有效地扩展到deep tree。0.9版还提供了针对于多节点、多GPU随机森林建筑的初始支持。通过多GPU支持,使用单个NVIDIA DGX-1训练森林模型,可以比双CPU、40-core节点快56倍。
从cuML 训练到推理
不仅是训练,要想真正在GPU上扩展数据科学,也需要加速端到端的应用程序。cuML 0.9 为我们带来了基于GPU的树模型支持的下一个发展,包括新的森林推理库(FIL)。FIL是一个轻量级的GPU加速引擎,它对基于树形模型进行推理,包括梯度增强决策树和随机森林。使用单个V100 GPU和两行Python代码,用户就可以加载一个已保存的XGBoost或LightGBM模型,并对新数据执行推理,速度比双20核CPU节点快36倍。在开源Treelite软件包的基础上,下一个版本的FIL还将添加对scikit-learn和cuML随机森林模型的支持。
图3:推理速度对比,XGBoost CPU vs 森林推理库 (FIL) GPU
图4:XGBoost CPU和FIL推理时间随批处理大小的增加而扩展(越低越好)
将来,cuML还将支持GPU上其他算法的推理。
XGBoost & Interoperability
RAPIDS的目标是支持一个蓬勃发展的GPU加速数据科学软件生态系统,与这些数据科学软件协同工作以实现端到端的计算。其中的一个例子就是XGBoost。RAPIDS为继续支持XGBoost而感到自豪,XGBoost是构建决策树状模型最流行的软件包之一。RAPIDS团队开发了一个新的GPU-XGBoost桥接器,它允许用户无缝地从cuDF dataframe移动到XGBoost训练,而无需通过CPU内存传递数据。桥接器利用开放式__cuda_array_interface__ 接口标准来实现从cuDF的高性能传输,并在不久的将来扩展到其他支持__cuda_array_interface__ 接口标准的库。这一变化是对XGBoost上游的贡献,将在即将发布的1.0版本中推出。
Dataframe Features Galore
cuDF是RAPIDS 的数据结构库基于 Apache Arrow搭建的,0.9版本中增加了关键性功能,包括:打印格式、时间支持、类别支持和生态系统互操作性。其中的一些亮点有:
---- 打印格式:可以在控制台或笔记本上完美地打印cuDF系列和DataFrames,类似于Pandas。
---- 扩展了时间支持,包含从纳秒到秒粒度的时间单位。
---- 用于分类列的字典现在保存在GPU上,新的API增加了cuDF Pandas的兼容性。
---- cuDF 0.9为生态系统互操作性增加了更多的桥梁,包括对具有新mask属性的__cuda_array_interface__支持,以及对基于NEP18的cuDF对象的__array_function__ 协议支持。
---- 值得注意的是,dask-cuDF现在与cuDF存储库合并,为ETL提供了一个单一的代码库(尽管这对于下载RAPIDS conda包的用户来说是一个透明的更改)。
在RAPIDS ETL hood 下面是libcudf、C++和CUDA库,提供了cuDF的高性能GPU实现。libcudf 0.9增加了一个新的GPU加速的Apache Avro读卡器,以及对其他读卡器的改进,例如更广泛的输入类型支持、在CSV中解析十六进制数字以及更好的ORC时间戳支持。0.9版还添加了新的算法,如用于合并已排序列的cudf::merge 和cudf::upper_bound 和cudf::lower_bound,这些算法允许在已排序列和表上并行搜索键数组(通过searchsorted在Python中公开)。这个版本还添加了列上的平均值、标准偏差和方差聚合(cuDF系列)。cudf::apply_boolean_mask 和cudf::drop_nulls 现在对整个表(DataFrame)而不是单个列(Series)进行操作。cudf::is_sorted 检查表/ DataFrame是否排序,cudf::nans_to_nulls 启用将浮点NaN值转换为空位掩码。
此外,cudf::rolling_window 现在支持即时(JIT)编译用户定义函数(UDF)。Python cuDF接口允许你将numba @cudajit 函数作为一个UDF传递给滚动窗口。在下面,cuDF从numba获取函数的PTX汇编代码,将其注入滚动窗口CUDA内核,JIT编译它并执行。编译后的代码被高速缓存以获得高性能的重复调用。这是在cuDF 0.8中为二进制操作和cudf::transform 添加的方法的一个概括。
最后,你会注意到cuDF在这个版本中速度有了显著提升,包括join(最多11倍)、gather和scatter on tables(速度也快2-3倍)的大幅性能改进,以及更多如图5所示的内容。
图5:单个NVIDIA Tesla V100 GPU与双路Intel Xeon E5–2698 v4 CPU(20核)上的cuDF vs Pandas加速
RAPIDS生态系统
在接下来的几个月里,RAPIDS工程团队将在全球各地的本地会议、会议和骇客大会上进行大量的演示和指导。我们希望有更多的人能够在会议或当地活动中轻松展示RAPIDS内容。











