
CUDA小妙招:这种快捷查询设备属性的方法你知道吗?
2019-09-03 12:07
 分享到微信
分享到微信
 分享到微博
分享到微博
在使用CUDA应用程序的时候,开发者通常需要知道每个块的最大可用共享内存,或者需要时常查询活动GPU中的多处理器数量。这时,一种查询的方法是调用cudaGetDeviceProperties()。但是,根据代码的不同,在代码的性能关键部分调用此函数会导致速度的大幅下降。cudaGetDeviceProperties() 甚至会导致cuML中随机森林算法的速度下降20倍。
针对这一问题,本文将在此教你一个非常简单的办法——cudaDeviceGetAttribute() ,借助于cudaDeviceGetAttribute() 你能够更快速地查询设备属性。
只查询你所需要的属性
在GPU运行的过程中,通常,你并不需要知道其全部属性。相对的,只要知道其中的一、两个属性即可,例如最大模块的大小、多处理器的数量或每个模块的最大共享内存。但是,cudaGetDeviceProperties() 只会粗暴地向你提供所有属性信息,根本不管你是否真的需要所有这些信息。因此,调用这个函数通常会增加大量的多余信息,而这些多余的信息又会增加你的投入,因为查询某些设备属性需要PCIe读取,而这个过程是非常耗时的。
与之相反的,cudaDeviceGetAttribute() 则是可以每次根据用户的调用需求,调用其中某一个属性。这样可以使得大多数属性查询的速度变得更快。这里所说的“更快”,不是一点半点的提速,而是整整一个数量级的提速:从毫秒级提速到纳秒级。下面,让我们做一个基准测试,对比两种方法的查询速度:
设备属性查询基准测试
在这里,我们设计了一个简单的基准测试来比较cudaGetDeviceProperties() 和cudaDeviceGetAttribute()的性能。测试采用了NVIDIA DGX-1中的单个Tesla V100和v410.79驱动程序,以及和CUDA Toolkit 10.0。该基准测试比较了使用cudaGetDeviceProperties()获取完整的cudaDeviceProp结构,以及使用cudaDeviceGetAttribute()查询两个调用:每个块的最大共享内存,以及多处理器数量。其平均运行时刻超过25次迭代。以下为cudaGetDeviceProperties()的测试代码:
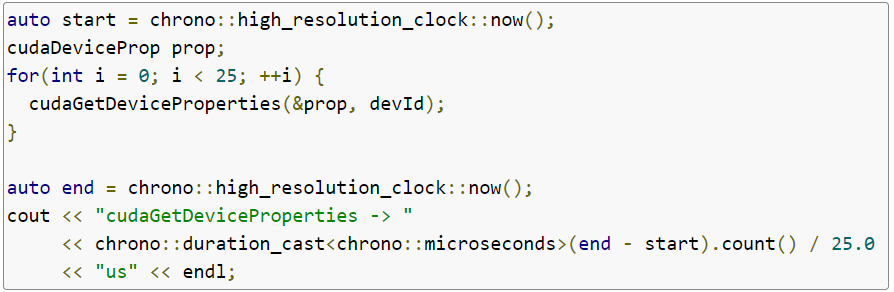
输出:

下面是cudaDeviceGetAttribute()的测试代码:

输出:

如你所见,对比两种方法的属性查询速度,cudaDeviceGetAttribute() 比cudaGetDeviceProperties() 快了四个数量级:80纳秒对1.15毫秒。
注意:有些属性查询很费时
如上所述,某些设备属性查询需要进行PCIe读取,而该过程又是极为耗时的,这就是就是为什么cudaGetDeviceProperties() 的速度会比较慢的原因。出于同样的原因,在使用cudaDeviceGetAttribute()查询以下属性时,速度会比查询其他属性慢得多:
cudaDevAttrClockRate;
cudaDevAttrKernelExecTimeout;
cudaDevAttrMemoryClockRate;
cudaDevAttrSingleToDoublePrecisionPerfRatio。
针对这一问题,本文将在此教你一个非常简单的办法——cudaDeviceGetAttribute() ,借助于cudaDeviceGetAttribute() 你能够更快速地查询设备属性。
只查询你所需要的属性
在GPU运行的过程中,通常,你并不需要知道其全部属性。相对的,只要知道其中的一、两个属性即可,例如最大模块的大小、多处理器的数量或每个模块的最大共享内存。但是,cudaGetDeviceProperties() 只会粗暴地向你提供所有属性信息,根本不管你是否真的需要所有这些信息。因此,调用这个函数通常会增加大量的多余信息,而这些多余的信息又会增加你的投入,因为查询某些设备属性需要PCIe读取,而这个过程是非常耗时的。
与之相反的,cudaDeviceGetAttribute() 则是可以每次根据用户的调用需求,调用其中某一个属性。这样可以使得大多数属性查询的速度变得更快。这里所说的“更快”,不是一点半点的提速,而是整整一个数量级的提速:从毫秒级提速到纳秒级。下面,让我们做一个基准测试,对比两种方法的查询速度:
设备属性查询基准测试
在这里,我们设计了一个简单的基准测试来比较cudaGetDeviceProperties() 和cudaDeviceGetAttribute()的性能。测试采用了NVIDIA DGX-1中的单个Tesla V100和v410.79驱动程序,以及和CUDA Toolkit 10.0。该基准测试比较了使用cudaGetDeviceProperties()获取完整的cudaDeviceProp结构,以及使用cudaDeviceGetAttribute()查询两个调用:每个块的最大共享内存,以及多处理器数量。其平均运行时刻超过25次迭代。以下为cudaGetDeviceProperties()的测试代码:
输出:
下面是cudaDeviceGetAttribute()的测试代码:
输出:
如你所见,对比两种方法的属性查询速度,cudaDeviceGetAttribute() 比cudaGetDeviceProperties() 快了四个数量级:80纳秒对1.15毫秒。
注意:有些属性查询很费时
如上所述,某些设备属性查询需要进行PCIe读取,而该过程又是极为耗时的,这就是就是为什么cudaGetDeviceProperties() 的速度会比较慢的原因。出于同样的原因,在使用cudaDeviceGetAttribute()查询以下属性时,速度会比查询其他属性慢得多:
cudaDevAttrClockRate;
cudaDevAttrKernelExecTimeout;
cudaDevAttrMemoryClockRate;
cudaDevAttrSingleToDoublePrecisionPerfRatio。











