NVAIL合作伙伴携最新机器人研究成果亮相ICRA 2019
2019-06-01 09:00
 分享到微信
分享到微信
 分享到微博
分享到微博
近日,众多全球顶级机器人学研究人员带着他们的前沿成果,亮相ICRA 2019。麻省理工学院、纽约大学和宾夕法尼亚大学等NVAIL(NVIDIA AI实验室)合作伙伴也参与其中,展示其各自的研究成果——基于NVIDIA平台进行实时推理。
麻省理工学院——变分端到端导航和本地化
作者称,这篇论文灵感来自于人类驾驶员所具有的三个主要特征:(1)在陌生路况中的驾驶能力;(2)在环境中本地化的能力;以及(3)当所感知的内容与地图所示不一致时的推理能力。
人类可以从地图中了解潜在的道路拓扑,并通过基于环境信息的视觉输入来定位。因此,当人们的视觉感知与从定位传感器观察到的信息不一致时,人们可以做出决策。
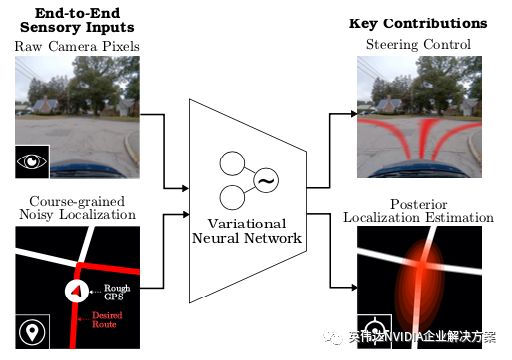
受人类能力的启发,作者着手开发一种深度学习系统,使自动驾驶汽车能够学习如何使用端到端自动驾驶系统来导航信息。导航信息采用路由和未路由地图的形式,与原始传感数据一起使用,以便在复杂的驾驶环境中进行导航和定位,如下图所示:
该算法从前方、右方和左方的三个摄像头拍摄到的图像,以及无路由的地图图像中获取输入补丁。这些图像被反馈到并行卷积管道,然后合并成完全连接的层,因此该层用于学习高斯混合模型(GMM)而不是转向控制。当可用时,路由地图被反馈到单独的卷积管道中,并与中间完全连接的层合并,以学习用于导航的确定性控制信号。
作者表示,他们的算法能够在不同复杂程度的环境中输出控制,包括直线道路行驶、交叉口以及环形交叉口。该算法被证明可以在车辆遇到未经训练的新道路和交叉路口时发挥作用。
作者还表明,基于GMM的概率控制输出可用于定位车辆,从而减少姿势不确定性并增加其定位置信度。他们首先利用从GPS中获得的姿势进行计算,然后基于该计算结果以及额外的不确定性,计算该姿势的后验概率。根据作者得出结论,如果后验分布的不确定性低于先前分布中的不确定性,则该模型能够增加其定位的置信度。这种预测姿势和降低不确定性的能力,让车辆即使在完全失去GPS信号的情况下也能获得更精确的定位。
该算法在NVIDIA V100 GPU上进行训练,训练一个模型需要3小时。推理则是在安装于配备了线控驱动功能的Toyota Prius中的DRIVE PX2上实时进行的。算法在ROS中实现,并利用NVIDIA DriveWorks SDK与车辆传感器连接。
未来,作者计划以多种方式推动自主化的界限。示例包括让车辆行驶在更多未经明确训练的情况下,理解传感器或模型何时失效,以及发现人何时应该帮助或接管控制。
麻省理工学院是ICRA 2019年度最佳会议论文奖的三名候选人之一。
纽约大学——用于自动驾驶高效推理的可重构网络
由于配备大量传感器,自动驾驶车辆会收集到海量的数据,处理这些数据需要大量的计算并训练一个大型网络。为了应对这一挑战,作者引入了一个可重构网络,可以在线预测,在既定的时间内,哪个传感器会提供最相关的数据。这种方法依赖于直觉,即在特定时刻只收集一小部分具有相关性的数据。
可重构网络包括门控网络,该门控网络基于将学习划分为子任务的概念,每个子任务由一位专家(expert)执行。门控网络决定在给定时间点使用哪个专家,这意味着算法将决定使用哪个传感器收集数据。进而,门控网络为避免大量计算成本提供了一种方法。
作者分三个步骤训练可重构网络。首先,专家组件被训练为传感器融合网络,门控网络把它们作为特征提取器,用于选择最相关传感器。其次,创建一个单独但小得多的门控网络,以模拟第一门控网络的行为,并在训练期间在门控网络的输出上实施稀疏性,以使其仅在任何给定时刻只选择一个专家。第三,通过微调专家和完全连接的层来训练可重构网络,同时参考了前一步骤中估计的门控网络的权重。
研究人员训练了两个版本的可重构网络,如下图所示。请注意,Reconf_Select所需的计算较少,因为它使用逐点求和来代替级联,从而将来自专家的特征向量进行合并。

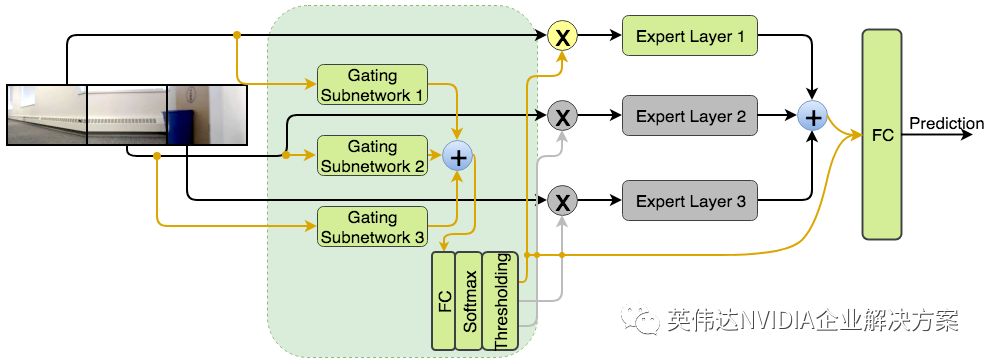
可重构网络的两种架构:Reconf_Concat (上方) 和Reconf_Select (下方)
使用NVIDIA GeForce GTX 1080 GPU在70,000个场景上对网络进行训练,大约需要6个小时。该网络在5,738个测试场景上进行了评估,使用相同的GPU进行推理,基于一张图像只需要1秒。从定量分析来看,如测试损失所证明,从同一摄像头选择输入的两个网络版本,可实现与使用来自所有摄像头的输入相同的性能,同时减少三倍的FLOPS计算。
对于车辆测试的实时性,作者在Traxxas X-Maxx遥控卡车上安装了NVIDIA Jetson TX1和三台Logitech HD Pro摄像头。网络必须选择三个摄像头中的一个,来收集室内环境的图像,以用于实时转向命令估计。该算法的在线处理能力超过20帧/秒。
宾夕法尼亚大学——用于移动机器人的集成传感和计算系统
此前,宾夕法尼亚大学在Open Vision Computer (OVC)上发表了一篇论文。OVC是一个开源计算平台,支持高速、视觉引导、GPS拒止和轻量级自主飞行机器人。OVC是与开源机器人基金会合作开发的,它将传感器和计算元素集成到一个软件包中。OVC旨在支持一系列计算机视觉算法,包括视觉惯性测距和立体声,以及包括路径规划和控制在内的自主学习相关算法。
OVC的第一个版本OVC1包含通过PCIe总线连接到计算模块的传感器子系统。传感器子系统包括一对CMOS图像传感器和惯性测量单元(IMU)。计算模块是NVIDIA Jetson TX2,专为计算密集型嵌入式应用而设计,PCIe总线为TX2的统一CPU和GPU内存系统提供直接、高速的接口。
在图像以原始图像从传感器传输到CPU和GPU的一瞬间,系统就可以提取特征。作者表示,该系统还能够处理基于深度学习的应用,如用于目标检测的单发多盒检测器(SSD512)和用于语义分割的ERFNet架构的变体。
搭载TX2模块的OVC1重量不到200克,总功耗低于20瓦。随后,OVC1被安装在重达1.3千克的Falcon 250自主飞行机器人上。该系统能够成功地穿越数百米,避开包括树木和建筑物在内的障碍物,并返回其起始位置,无需GPS信号并基于最小指令。 Falcon 250上的OVC1如下图所示。

Falcon 250自主飞行机器人,配备第一版Open Vision Computer的OVC1
作者还提出了OVC的第二种设计OVC2,旨在缩小外形尺寸并提高性能,如下图所示。OVC2基于TX2,但作者正在考虑使用比TX2性能更优的Jetson Xavier。

基于NVIDIA Jetson TX2的第二版Open Vision Computer OVC2
宾夕法尼亚大学还发表了另一篇论文,展示了一种实时立体深度估计和稀疏深度融合算法,该算法在OVC1上进行处理,并且可实现GPU加速。该算法可将从激光雷达传感器或测距相机获得的稀疏深度信息引入立体深度估计,其基于Middlebury 2014和KITTI 2015基准数据集所表现出的性能优于现有技术水平。











