
NVIDIA超级公开课第9讲实录:揭秘深度学习
2018-08-01 12:20
 分享到微信
分享到微信
 分享到微博
分享到微博
侯宇涛此前还主讲了第三讲和第五讲,主题分别为《不需要写代码,如何用开源软件DIGITS实现图像分类》和《手把手教你使用开源软件DIGITS实现目标检测》。
主讲环节
侯宇涛:感谢智东西公开课的邀请,非常荣幸今天能有机会跟大家一起分享深度学习这一新概念在市场上盛行的情况。
我叫侯宇涛,是NVIDIA GPU应用市场总监,同时也是NVIDIA深度学习学院的一位认证讲师。在过去一年时间里,我们透过各种各样的教材,在全国各地分享NVIDIA对于深度学习的理解和体验,让更多的人理解深度学习。
今天将从以下四个方面来跟大家分享我对深度学习这个概念的理解:
-机器学习和深度学习的定义;
-深度学习的应用范围;
-深入学习的实现以及特点;
-上手NVIDIA交互式深度学习训练平台DIGITS。
机器学习和深度学习的定义
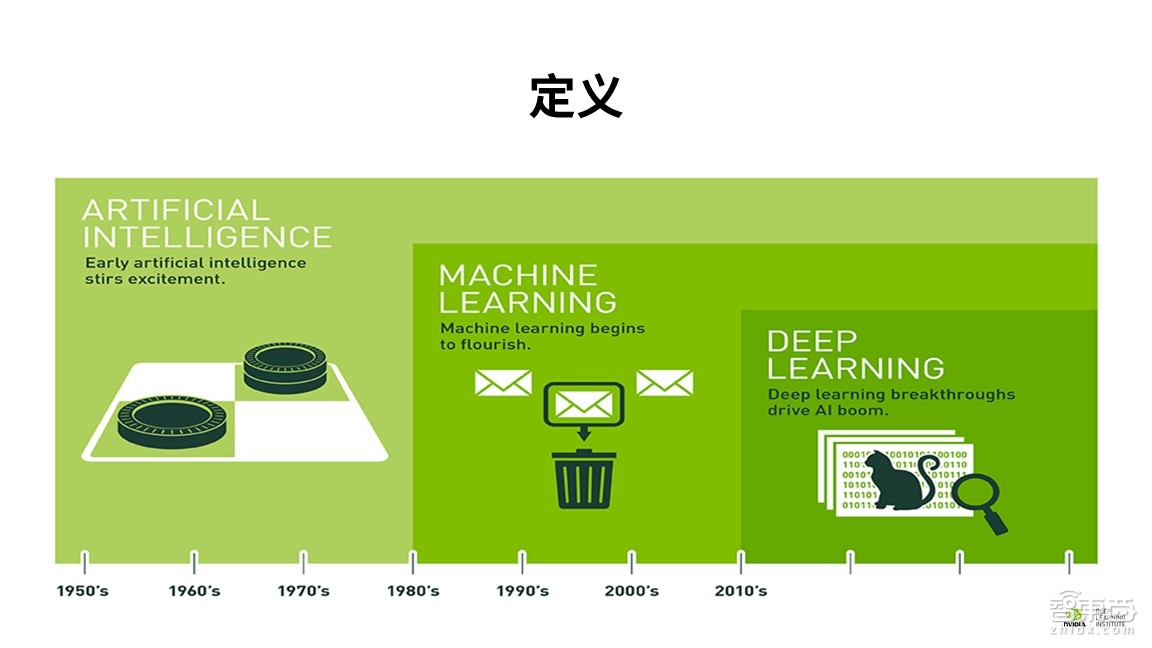
实际上,深度学习是一个解决方法,从范畴上来说,它属于人工智能这个大的学术领域范畴。从上世纪五十年代计算机被发明开始,高效地利用各种各样的工具去解决人类生活生产中的问题成为当时一个大的话题,到了1980年,利用计算机解决问题的方法被初步定义为机器学习,而机器学习有很多的学科,在设计时它是一个交叉的学科,涉及到概率论、统计学、算法复杂度理论等多门学科。
深度学习是通过对人工神经网络的研究,使得机器学习的操作和执行变得更完善、更高效。因此,深度学习是机器学习的一个分支。从概念上理解,人工智能包含机器学习,而机器学习包含深度学习。
深度学习的应用范围

首先,为什么要去学习深度学习。2012年9月Kaggle举办的分子活动数据挖掘大赛,该大赛每年都会吸引众多的分子生物学、医学、化学和药学数据科学团队来参加,参赛者要具有非常多的知识积累才能去参加。但是在2012这次,AI人工智能教父级人物让他的博士生团队带着深度学习的工具到了比赛现场,而他们一点生物学、医学、分子学和化学背景都没有,但是最后却赢得了比赛。
当时震撼了整个科技界,纽约时报也进行了相应的报道,因为这这件事带来一种新的现象,自己长期的知识积累和努力可能在某些工具面前没有办法得到更好的结果。
这种情况在目前看来或许只是序幕,在中国长时间看来,各种各样深度学习的应用,包括大家对深度学习的评论,一直都处在整个浪潮的顶端。下面我分享一个例子,有一位学者毕业于北京大学,也有了不错的工作和自己的项目,并有了不错的成就,突然有一天他沉寂了,那么他干嘛去了呢。他学深度学习去了,在学完深度学习以后,别人问他为什么要学深度学习,他说了一段话:
“学习深度学习,先跟上再说。学深度学习,是因为不得已,为什么?因为深度学习结合力太强。可以放在各个场景下,给各个领域带来冲击。我们不知道这个东西能用在多少地方,有多大的潜力,能搞出什么名堂。别的技术,你大概可以设想出它极大的发展之后能达到哪个状态,比如说,区块链彻底重构互联网,一切数字产品皆可资产,代码即法律,所有的交易都可以自动履约完成;比如说,物联网给每一粒灰尘赋予一个IP,纳米机器人在我们的血液里纵横,消灭一切疾病;比如说,VR创造出的虚拟世界让人难辨真伪,一辈子体验几十辈子的人生,等等,这些事情,不管多么科幻,你都可以想得到,它有一个明确的方向。有方向就好办,你可以选择说这个方向我要跟,或者这个方向我不跟。但是深度学习不一样,你不知道它的能力边界在哪里,更没有明确的场景限制。几乎在你可以想到的任何事情中,你都可以构造一个复杂的网络,然后把数据灌进去开始学学,蛮不讲理的就可能得到一个更好的结果。在竞争当中,这种武器是最可怕的,没有固定的形态,放到哪里都有可能弄出一个意外的大杀器。这种武器,如果别人有而你没有,不知道对方在什么地方,什么时候就突然拿出一个核弹把你榨得渣都不剩,你的准备、经验和积累完全不起作用,而且在此之前,你完全预见不了。这种感觉太可怕了,因此我必须直接掌握这个工具,这个不是技术情怀也不是前瞻,而是不得已。”这位先生的理解特别能够体验到,现在深度学习给各行业带来的冲击。无论你是从生活的环境里,还是在工作当中,看到或听到竞争对手或同行在做出各种各样精练和高效的工具时都会带来这样的压力。

这样的压力在几年前大家都应该能看到,大家可以看看这张图片,可以看到一些大牌的公司都在利用深度学习去改善自己的业务流程,从流程上提高自己的业务效率以及生产率。当然也有各种专业提供这样平台的企业。比如微软、IBM、阿里云等企业都享受或正在体验着深度学习这个工具给他们学习或工作带来的各种各样的帮助。

从深度学习的发展以及长期被运用的历史回顾中,大家总结了三个与深度学习相关的要素:
1.算法,深度学习需有算法,你要去做深度学习,算法一定要足够的精堪;
2.数据,需要有自己的数据,包括自己的业务数据流,或者整个记录你一段历史的工作流程等这些数据是必不可缺的;
3.算力,有了这两项还是不够的,还需要一个能够继续提供强力运算能力的GPU,帮助你从算法中得到数据,有了算法和数据,再加上一个计算能力的GPU,你的深度学习工程才能正常的开展。
目前,深度学习正在席卷各个行业,无论是从互联网的服务和图像与视频的分类,还是语音识别、自然语言理解等方面,我相信大家都已经体验到深度学习给生活或者工作带来的便利。从医疗上来讲,各种各样的医疗顾问系统以及高端的诊断系统,其背后都在使用着各种各样的图片分类,还有一些智能诊断的解决方案等带来的便利,很多大医院的医生和教授都感受到了深度学习给他们带来的压力。
从媒体娱乐上来讲,也有在各种各样视频使用上的改善,比如我要看一段视频或一部电影,那么这个视频和电影是否满足我个人的兴趣需求,而现在一些应用都可以提前帮助你对视频或电影进行预先的浏览,然后给出内容的总结,能够让你对于选中的电影进行第二次分类,这也是所谓的语义理解。
从安防到自动驾驶,都是深度学习涉及到的领域,安防和自动驾驶更多是从图像上去解决问题,因此我们今天可能会说更多关于图像的内容。
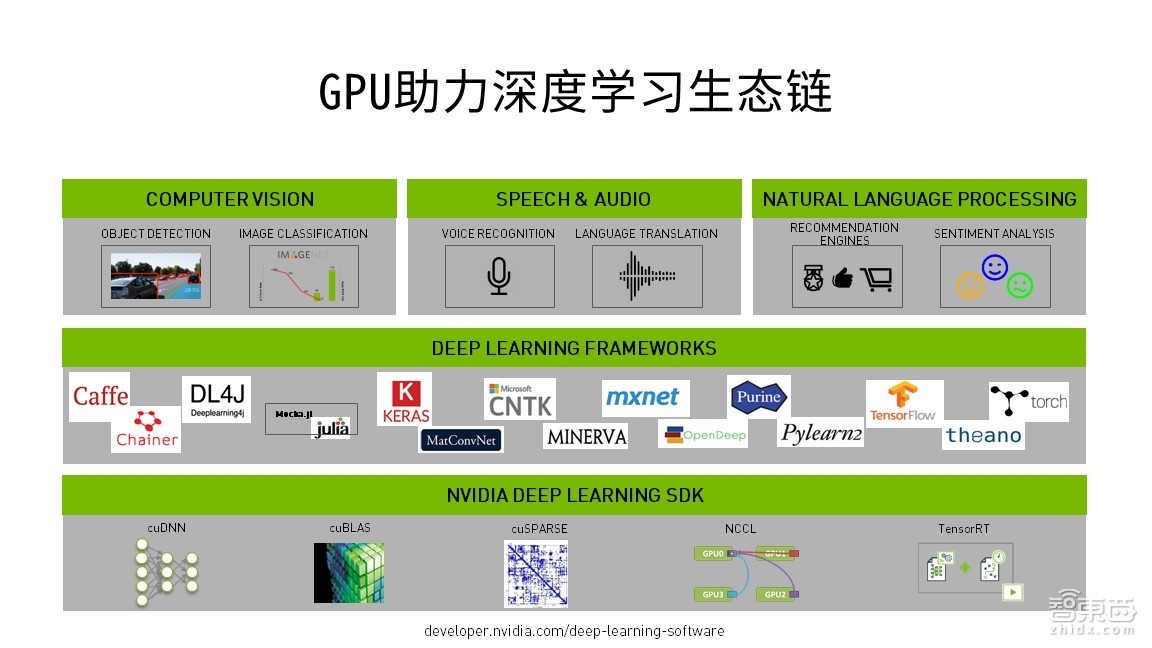
大家可以看下上面这张图,它是基于目前深度学习的行业应用做的简单分类,这个分类也是目前深度学习生态链的布局。首先,左上是与视觉相关的,包括各种各样的图片和视频等;与图像分类和目标检测相关的,也就是跟你看到的相关;中间是Speech&Audio,跟你听到的相关;最右边是跟你理解的相关。
这三种分类基本覆盖了现在众多与深度学习相关的应用。另外,可以分得更细一些。从应用上来讲,整个市场上有非常多的工具能够帮到各个开发人员和开发团队去降低自己的编程工作量,也方便大家去实现各种各样的开发。上图中间这一段叫深度学习Framework(深度学习框架),包括Caffe、CNTK、TensorFlow、Theano等,这个层面是各个技术公司为了能够让自己对于行业的理解以及对于技术的把握而提供给大家的工具,其中有些收费,有些免费的。
对于NVIDIA来说,由于NVIDIA是AI计算引擎加速的平台服务供应商。对于各种行业的应用,NVIDIA都基于GPU提供了非常多的工具,比如对于深度神经网络,我们提供了专门的cuDNN加速函数库,大家可以用它实现更高效的Caffe或者是其他Framework。跟cuDNN深度神经网络对应的,有TensorRT,在上图的右下角,TensorRT是NVIDIA实现推断用的小工具。
TensorRT是针对GPU优化的工具,使得在训练中生成的网络能够在GPU平台上得到网络的重新优化,使得在GPU平台上进行Inference时的速度更快。这也是NVIDIA提供与AI相关的两个SDK。另外,我们还提供一些高性能计算,比如cuBLAs,cuSPASE等免费的工具,还包括多GPU之间通讯的NCCL。
这段生态链只是给大家一个大概的印象,也就是目前的深度学习生态链是一个什么样的分布,可以作为大家步入深度学习领域的一个参考,而目前成型或者成熟的产品,是最能够帮到大家的。
深度学习的实现及特点
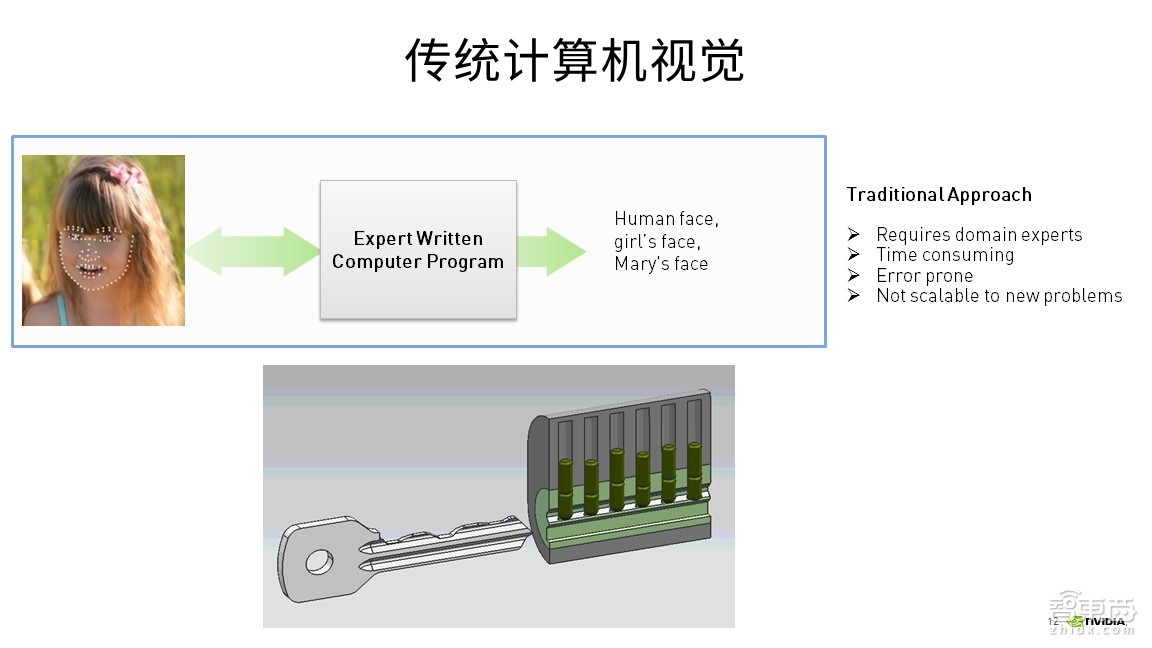
这张图展示的是关于传统计算机视觉的内容,对于图片处理,一直到现在都没有办法去高效解决人脸识别的问题。上图的事例中,在最左边小女孩儿的脸上被标了一些白点,这些白点总共有120个,也就是要识别人脸上的特征点。在传统的计算机视觉一般是要用编程的方法来处理图片识别的问题,每一个特征点都需要一段代码来完成,由计算机处理对于图片上每一个特征点的像素变化值。也就是说这张人脸有120个特征点,如果需要识别这张图片,那么至少要去写120段代码,这是一个比较固定的实现方式,并不是用一个公式就能完成一张图片各个特征点的提取。对于这种固定的方式,可以从下边这个例子来理解。
很明显,这是一把弹子锁。要打开弹子锁,则需要一把钥匙,钥匙中有凹槽,也就是要开启每把锁的钥匙都是一一对应的,因此,锁和钥匙凹槽的高度与锁之间的位置是一对一的特性,也就了规定一把锁对应一把钥匙。因此可以看出,传统的计算机视觉处理图片的方式是一对一的编程模式。
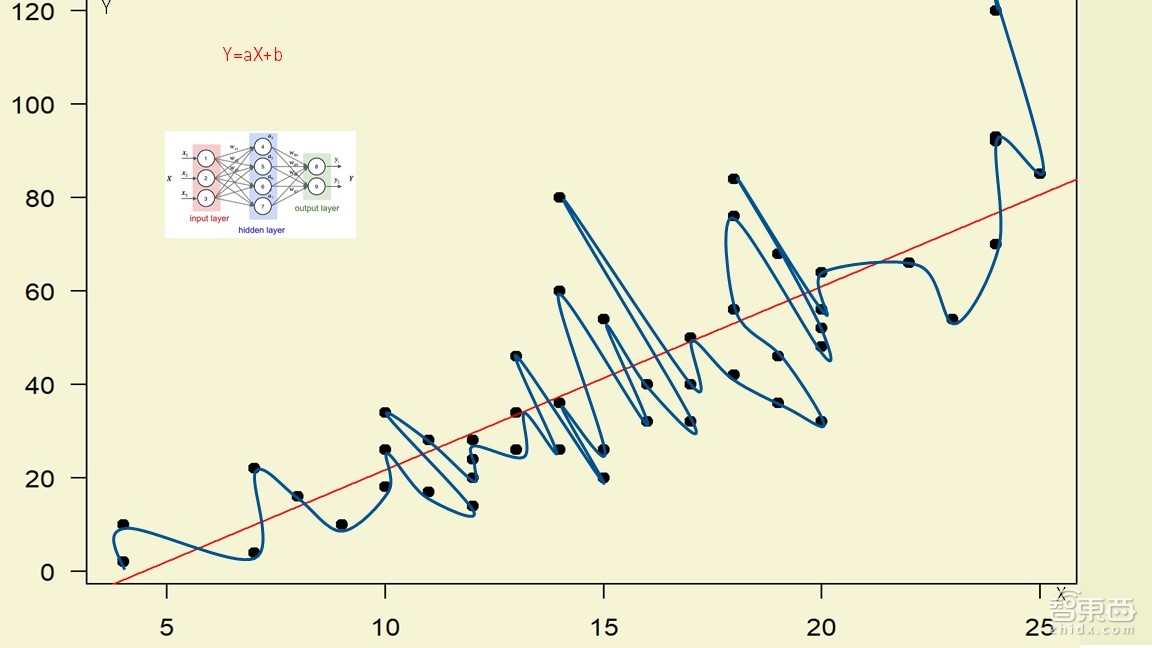
对于传统的编程模式,是没有办法实现一个算法识别多张图片的。之前一般都是实行从理论到实际的实验输出,再由实验的数据数值倒推出内在过程中遵循的理论和公式。而深度学习是完全反过来的,由于深度学习没有这方面的理论,全部都需要靠实际的数据,把实际的数据交给计算机,让计算机根据实际的数据生成一个拼成的公式。
上图红色的那条线是一条简单的直线,可以认为是线性的,比如横轴(X轴)是速度,纵轴(Y轴)是距离,在固定时间内,速度越快,距离越长,可以用简单的表达式y=ax+b来表示。但是,如果换成了一堆黑色小点形成的散状数据,这时是没有理论的,只能用一段一段的数值网络或者算法来模拟生成某一个点的公式和模型。
这样的处理办法就是深度学习中机器学习的概念。机器学习针对一个固定的网络,从输入到输出,其中间的每一层都有不同的任务和功能,从而提取不同数据的特征值。以图像为例,就是从原始图片到最后定义的分类属性,这样的网络称之为深度学习网络。
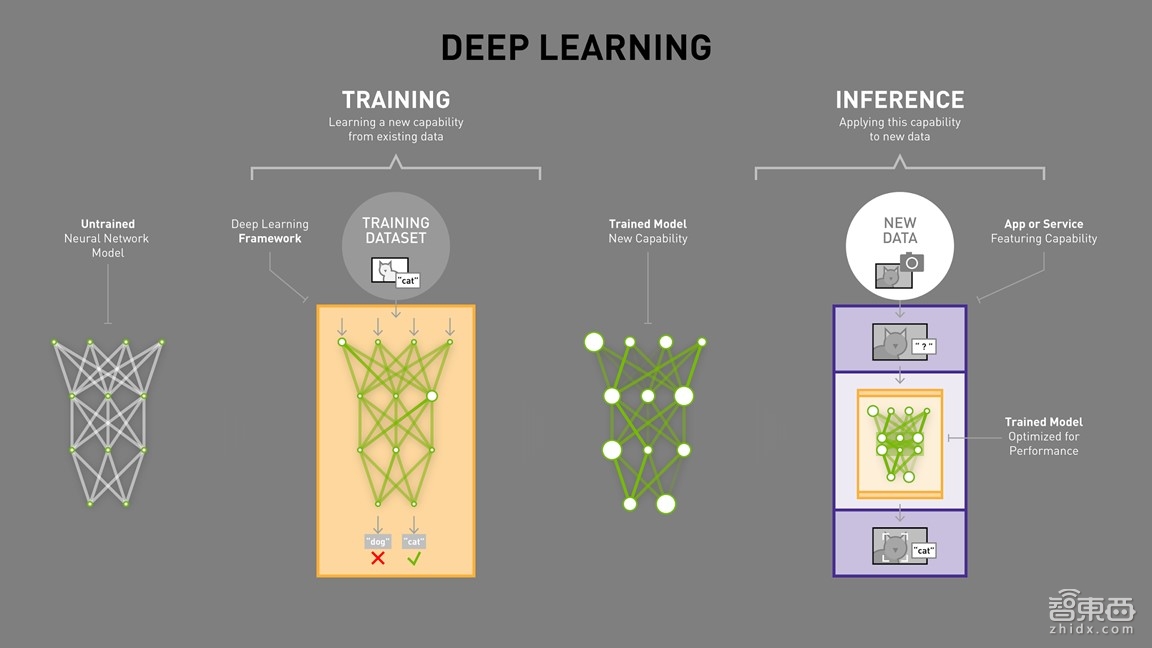
接下来给大家分享下卷积神经网络典型的过程。
首先,先定义一个初始化网络,即图上最左边,它有三层网络,四个数据点,一个是数据输入点,数据输入到第二层,再到最后的数据输出,通过这个网络去提取一张图片的信息,将提取的信息和分类的图片进行比较。
这种比较也就是学习,如果比较的数值误差比较大,那么计算机会把相对应各个节点之间的权重(也就是图片中那些绿色小点)值进行调整,这种调整是完全由计算机自己来完成的,目的就是梯度下降,使误差越来越小,这才是大家追求的方向。计算机的深度学习也是往梯度越来越小的方向进行计算的。
当一个网络被初始化的时候,它是没有任何意义的,需要输入各种各样已经分类好的原始图片,由于原始图片已经分好了类,当它被这个网络提取的特征和网络自身规定好的网络属性进行比对时,会存在一个差值。比如我输入了一只猫的特征值,在经过训练后,会得到的一个范围,这个范围经过比较以后,如果误差大于它的需求,那么就需要去把这个误差返回,调整相关的权重数值。
当权重的数值需要放大的时候,即在某个方面特征点的提取需要加强,比如上图中间的橙色图,有一个白色的亮点,表明该层网络的特征值提取需要加强,即该数值的影响要加强。如果左边亮点上的值没有被放大,反而变小了,就说明该值的提取需要降低,即影响力要降低。周而复始,一次一次输入,一次一次跟特征点的比对,会使得它形成一个对于某一类比较敏感的网络特征提取计算。
对于Inference(推理)来说,它是提取了Training Model(训练模型),就是将已经训练好的模型部署到自己的平台上。Training网络和Inference网络是一样的,但是它们执行流向不一样,Training网络是周而复始的,由输入到输出,由输出的结果返还给输入,从而调整权重。而Inference是从头到尾,正常输入后,输出是一个判断或者是一个概率。
大家可以看到,深度学习是从Training到最后的Inference这样一个框架。这个框架也是深度学习在内部网络的定义和具体的执行流程。
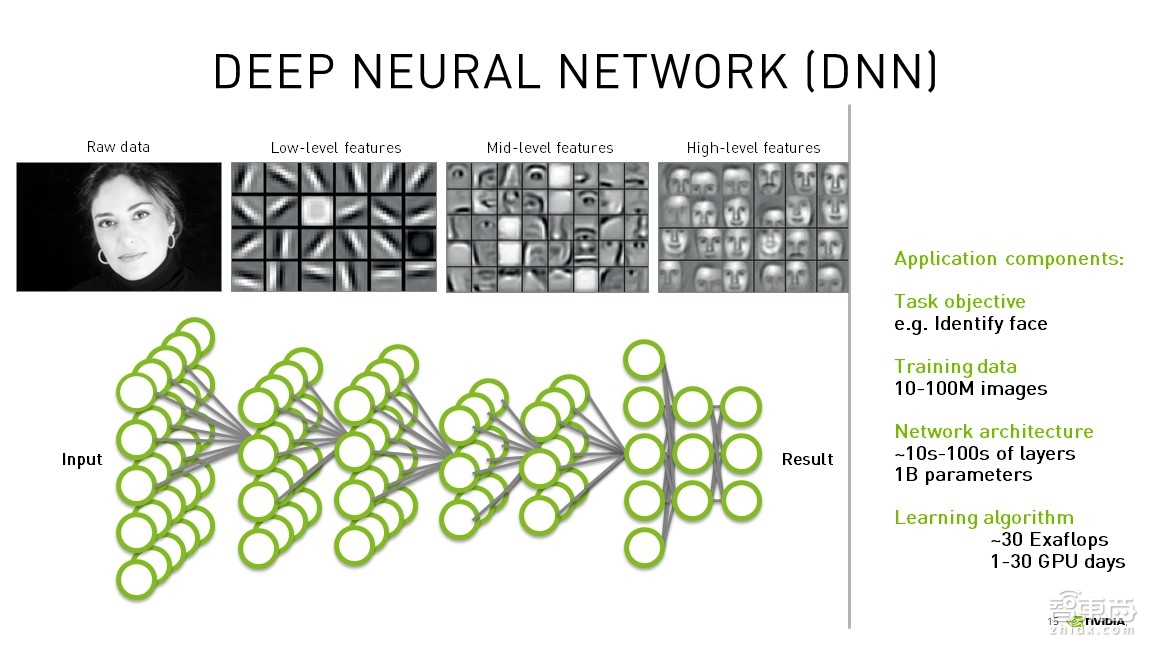
接下来分享一个典型的深度神经网络内部的操作。从操作上来讲,计算机会把一张原始图片作为一个像素的变化值输入到神经网络内部去提取特征,所谓提取特征,就是观察边缘是否变化,边缘没有变化也就没有这个特征的存在。因此,它会按照边缘变化的方式去提取特征,根据边缘提取特征后,边缘与边缘之间的几何上关系,或者人脸结构上的关系就会构成局部器官的形状,也叫中间环节的特征提取。到最后,根据器官与器官之间的联系再形成一个高端的特征提取,从而构成人脸的轮廓。这样一步一步的操作也对应着下边一层一层网络时序。而时序是非常耗费计算资源的。
右边是典型的训练数据,这些都是百万级的数据。网络的结构从十层到一百层,其中每一层中的权重以及网络的计算参数多达10亿个。在NVIDIA图像分类的一门课中,一个简单的网络仅有两层卷积网络,其中包含的参数就达到了84万个。对于这么大的参数规模,如果要手工去调,是非常耗时间的,因此一定要让机器根据输入自动去匹配调节。
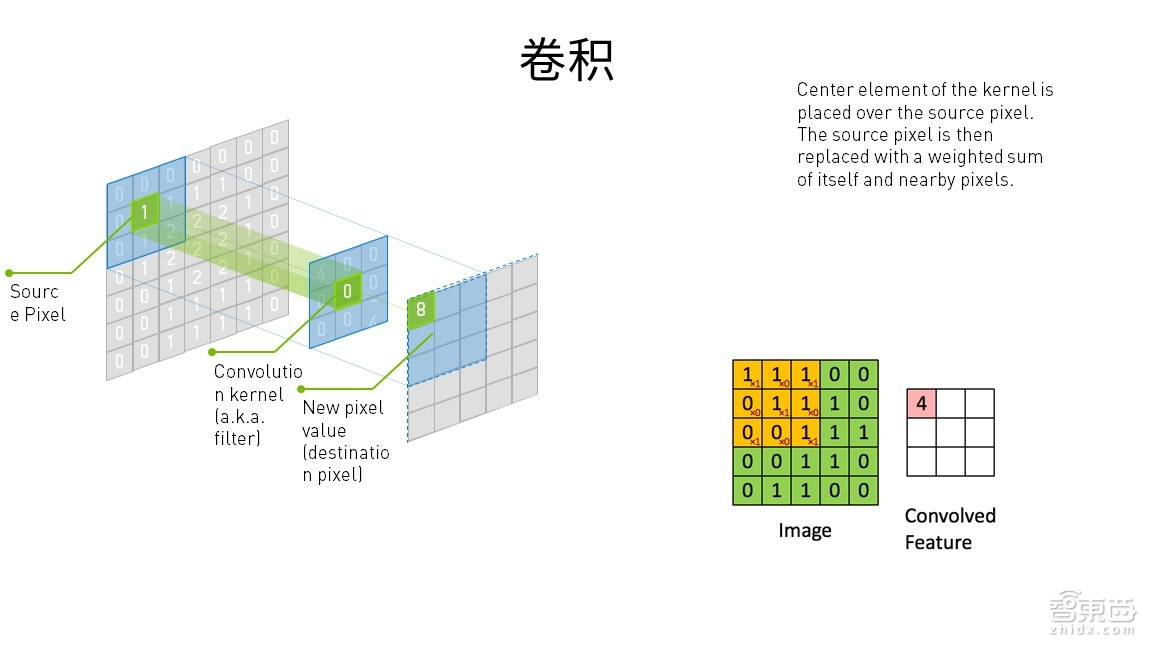
卷积是深度神经网络中非常重要的一个概念。深度神经网络对于特征提取的计算,一定要用卷积的方式,即通过卷积核在原始图片上进行遍历的方式,提取一张图片上所有有用的特征,在提取完特征以后,生成新图片的维度都会降低,从图上可以看到,原本是一个7x7的矩阵,经过卷积计算之后变成了5x5的矩阵,也就是生成了一个小的图片,这个图片包含了第一张7x7图片的每一个像素的特征,这就是科学家们想到的一个方案,对于原始图片,要提取到所有特征,同时降低它的维度,维度小了,矩阵小了,计算量自然就小了。比如最右边有一个5x5的矩阵,边上有一个3x3的矩阵,粉红色的4就是由橙色的3x3矩阵计算出来的。
举个例子,假如有一个十万平方米的广场,如何把它拍成高清晰的图片展示给大家看呢?如果在飞机上拍,飞机飞得太快,有可能一张图片的高精度无法达到厘米级的清晰度。因此,我们可以用一个小的无人机,把十万平方米的广场均分成1000个面积为100平方米的方块,通过无人机分次将广场拍下来。拍下来后就相当于图片上显示的矩阵。矩阵第一次在左上角将3x3往右挪,再将其他的3x3也往右挪,总共挪四次就可以把它拍下来。而无人机也是这种形式,由于无人机有时拍的角度不一样,可能不会特别清晰,这时我可以用100个无人机拍1000遍的就可以了,虽然拍的工作量比较大,但是保证了数据的完整性以及提取的完整性,因此还是值得去取的。每一个无人机都拍了1000张图片,100个无人机就拍了100x1000张图片,其中一定会有你要的信息。而前提是后端的计算平台的算力要足够强。对于卷积也是一样,图上显示3x3中间是一个绿色的零,这就是一个卷积核,一个卷积核得到一张维度减少的图片。用100个卷积核就可以得到100个包含第一张图片的feature maps(特征映射)。
有了众多的卷积核,能够充分提取第一个数据源的特征值,同时保证特征值不漏掉,也是卷积非常重要的特点,保证特征不丢失。
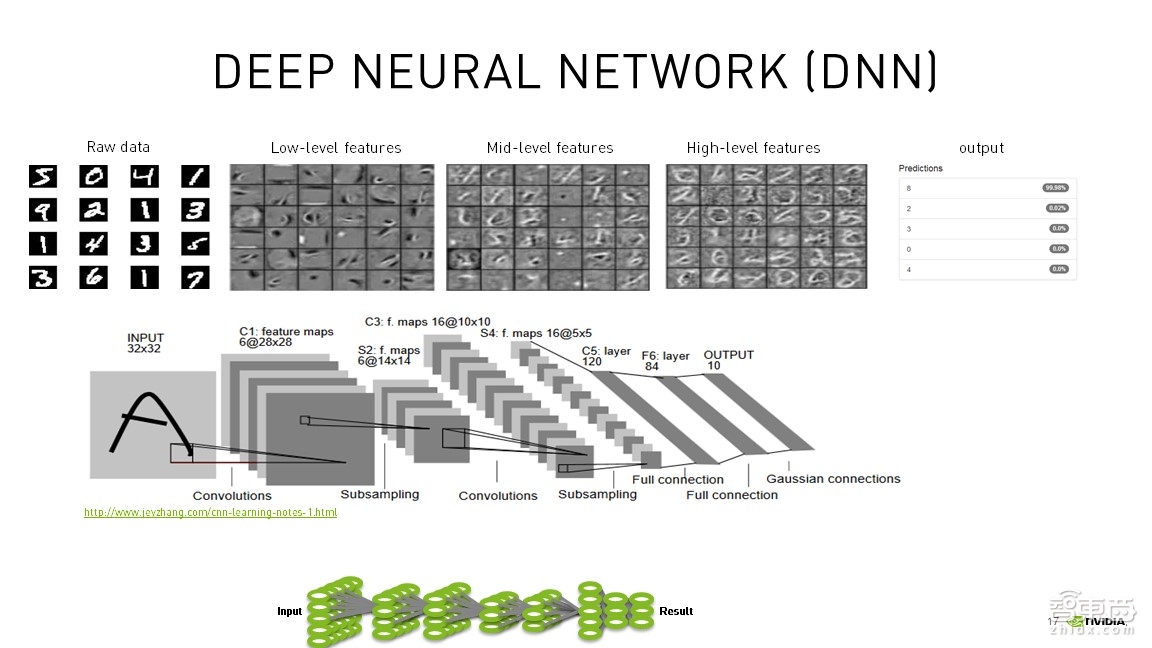
上图展示了深度神经网络的结构。左边可以看到大写字母A,它是一个32x32的矩阵,经过了第一层的卷积后变成了28x28的矩阵,可以输出6个卷积核。也就是说有6个小无人机拍摄的就是28x28的图片,然后继续传到后面的网络来降低维度,再到后边的全连接层,最后输出分类的OUTPUT。这就是典型LeNet卷积神经网络特征。还可以看到上面也是一个典型Inference端(推理端)的实现流程图。
Inference端的实际流程图,在左边可以看到有些数字,每一张图片的输入到中间的网络都是分次从低到高进行特征提取,最后,经过Softmax函数,判断出可能的数字,这就是典型的训练好的网络进行Inference推断的流程。
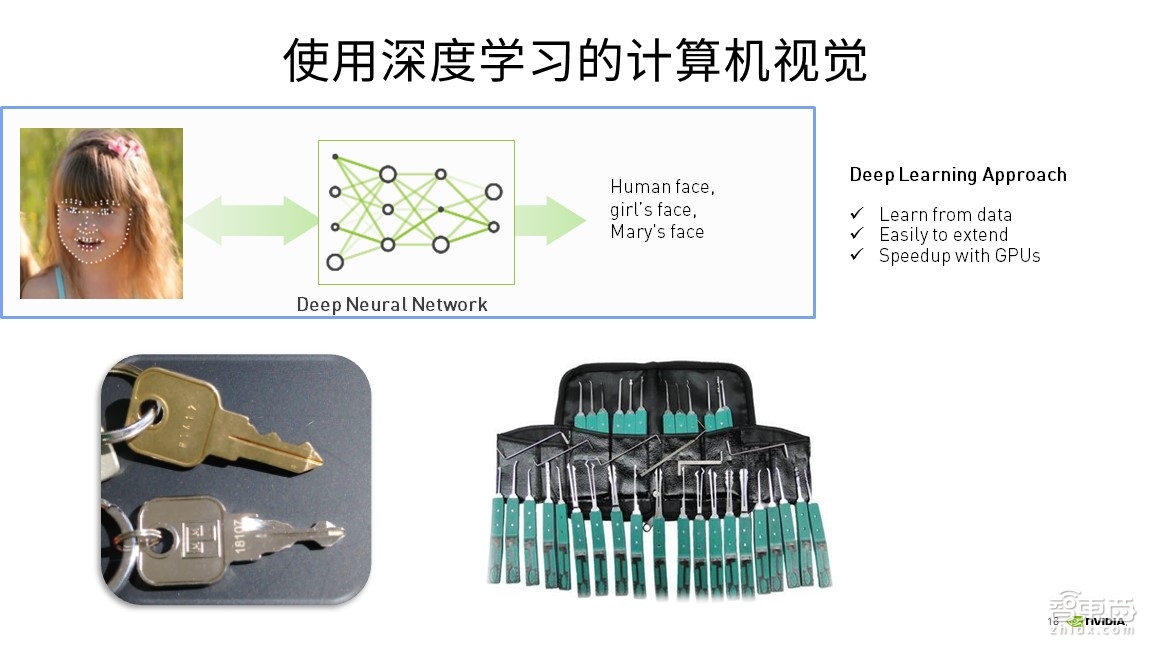
用深度学习实现图片分类的识别。如果用传统的解决方法,每一个像素点需要写一段代码,120个特征点就需要写120段代码。现在由于神经网络处理方法的存在,可以用众多的图片让计算机自己去学习并拼成一个公式,通过这个公式就能够去识别从多角度拍摄的小女孩图片。这就像下边的这个例子,有两把钥匙,白色钥匙是我平常工作推柜的钥匙,黄色钥匙是我们办公室经理的钥匙。如果我哪天没有带白钥匙的时候,我就可以去找行政部经理拿一把黄钥匙,这个黄钥匙是一把万用钥匙,它能够开我们这层一百多个同事的推柜,但黄钥匙是不能开壁柜的。类似于算法,当你在做某一个人脸识别时,你给它一只猫,它是识别不了。因此,算法还是有很大的空间能够让大家去做相关的研究。上图右边是一堆镊子,是配锁师傅的专门钥匙,可以开非常多机械保险柜的锁。但是在人工智能领域,还没有像这种钥匙一样可以识别非常多物体的算法。
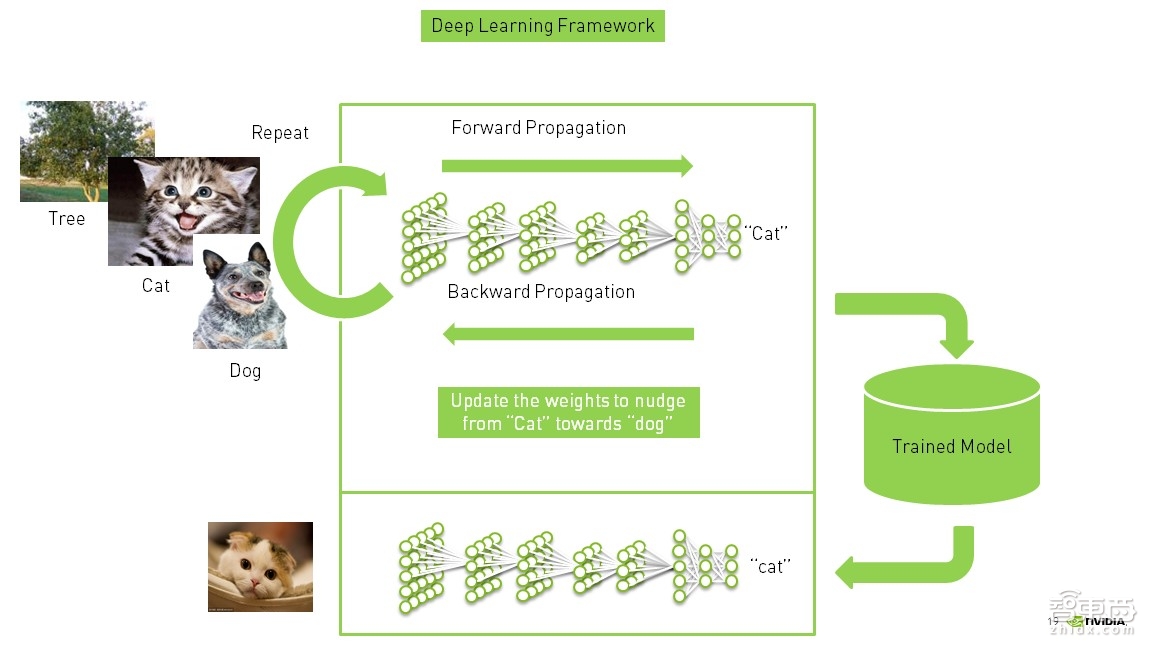
总结一下刚才讲的训练过程,对于定义的神经网络,如果让它对三个物体进行判断,比如狗、猫和树,研究人员要把大量标记好的狗、猫和树的图片一次性投入到训练网络中。当狗的图片输入进去以后,它会与狗的特征进行比较,如果这个比较值得到了猫的结论,就说明这个网络模型是不对的,需要把出错的概率和数值减少,因此就要去调整权重,减少误差。通过一次一次的训练,使得输出结果更贴近输入的标注图片。
有了这样一次一次的优化和精度提高的训练模型以后,基于不同类的图片,需要一次一次地输入进去,计算机进行一次又一次理解和学习。这个过程更多地是一个大规模数据的统计,统计一张图片在360°空间中像素点存在的可能性有多少,模型只要记住了这个可能性,以后进行比对和特征提取时,就会得到一个相对的概率。在得到这样的模型以后,也会将其部署到下面的推演过程,也就是整个深度神经网络的实现流程。
接下来总结一下要构建和部署深度神经网络需要的步骤:
第一,准备好原始数据和要用的原始网络,这个网络也就是你需要用到的算法;
第二,数据的准备,是要用监督式学习,还是用非监督式学习,如果用监督式学习,就要把准备的图片进行分类和打标签;
第三,根据自己的业务流在不同的Framework中定义网络;
第四,网络训练,在训练时也有非常多的技巧,比如批处理、定义优化参数等;
第五,根据训练结果优化网络和数据。其中,网络完成后一次一次输入的小数据、大数据或者超大规模数据都会对精度带来不同的影响;
第六,网络部署,将训练好的网络结构、网络参数以及Labor文件部署到推演平台上。
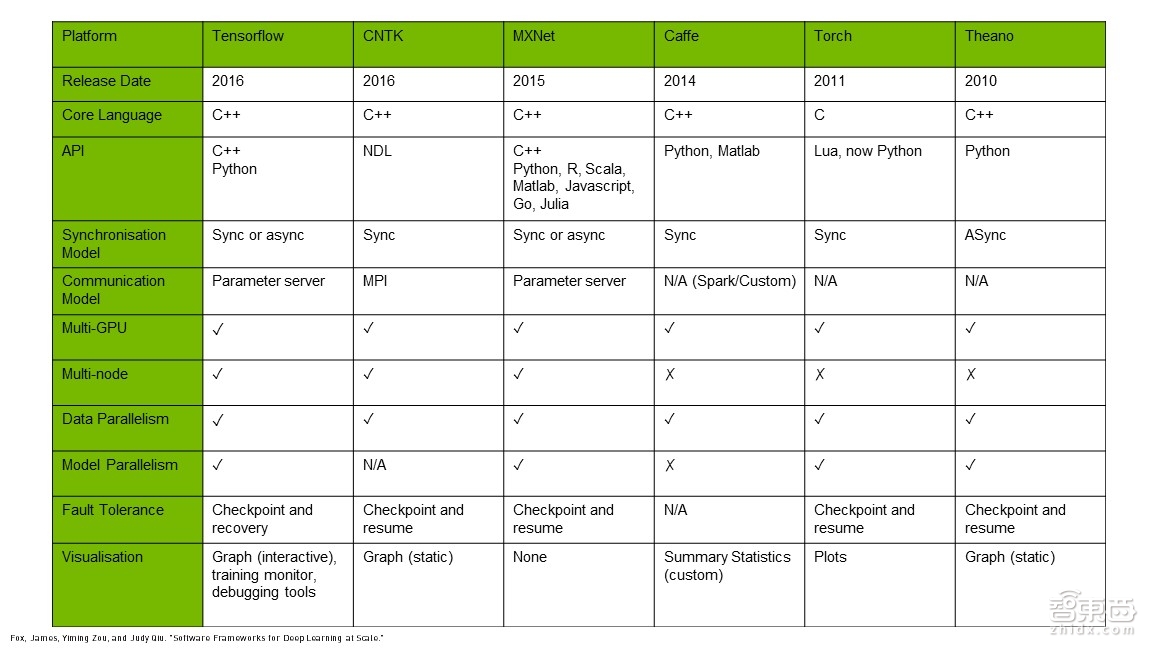
在做网络部署之前,如何选择适合自己的工具呢?比如Framework的种类非常多,包括TensorFlow、CNTK、MXNet、Caffe、Torch以及Theano等。目前用得最多的是TensorFlow,因为它功能比较强,尤其对于分布式训练也有类似参数服务器的功能,能够让多级标注节点之间的训练得到同步。
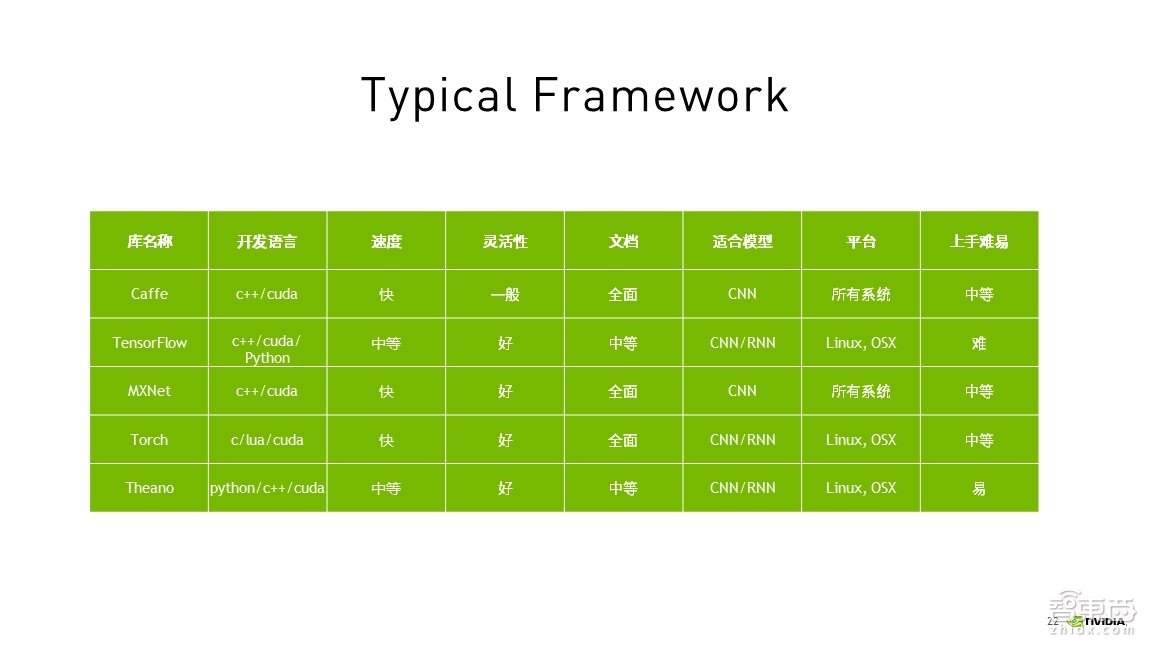
每个人选择Framework都会按照自己的习惯进行选择,如果你以前没有学过相关的编程,那么需要花费的时间会比较多,如果你以前学过C语言或者Python,可以根据上表选择相应的Framework,利用自身编程知识的积累,将会减少非常多重新学习的时间。每个Framework的特点都不一样,比如你选择用Caffe,那么与时序相关的东西做起来就比较费劲,因此需要根据自己的需求进行选择。

深度学习的优势有三个:
1.鲁棒性,所谓鲁棒性就是它的性能非常稳定,数据越多,它的稳定性越强,不会有用着用着就非常不可靠的情况;
2.通用性,也是让人觉得很惊奇的地方,前段时间的围棋大赛事件,AlphaGo算法不仅仅用在娱乐,很多相同的业务流程都会拿它去做,尤其是在医疗方面,很多学者都开始参考它的算法来做一些肿瘤的分析。这就是所谓内部流逻辑上的一致性,使得计算的通用性得到的体验。
3.可扩展性,由于做数据分析的时候,各个数据样本之间是相互独立的,我们可以拿这些独立的数据进行训练,也可以使用分布式集群的方式进行模型和数据的并行化,从而快速地帮助模型训练,并得到一个更好的精度。
上手NVIDIA交互式深度学习训练平台DIGITS
基于大家对于深入学习的理解,如何快速地启动深度学习的旅程呢。

如果用传统的深度学习开发平台,会发现需要去学非常多基于命令行的操作,比如要了解Linux、了解相关的命令行环境、需要去学很多Framework之间各种各样的人工开发技巧等,这些都会约束你进入人工智能或者深度学习开发。

NVIDIA结合了这些普遍存在的问题开发了一个非常棒的工具——DIGITS,并且该工具是免费开源的,可以让新手快速步入自己的深度学习开发领域中。DIGITS是一个基于浏览器的交互式深度学习训练平台。通过上图可以看到,从左到右有四个步骤,最左边是数据操作界面,用鼠标点击自己保存在硬盘空间某个位置的数据提取出来,放到DIGITS的工作环境中,它能够显示出分类后的图片张数。
第二步,数据集加载完后,用鼠标点击选择要使用的Framework、求解器的定义、训练的圈数以及相关GPU的选择。这些都是一目了然的,相对于用命令行进行操作,图形化界面的显示更加直接。
第三步,可以看到上图中间有一个图表,图表上有一条从低往高走的橙色曲线,绿色和蓝色的曲线是从高往低走,橙色曲线代表训练精度的曲线,蓝色和绿色曲线代表训练误差的曲线,随着训练时间的增加,数据的加载,如果精度越来越高,误差越来越小,说明现在用的训练算法是正确的;如果训练误差越来越高,或者训练误差不再降低,或者训练的精度不再提升而是趋于平缓,这些结果都说明你的训练出现了问题。

如果使用传统命令行的形式,我们需要非常关注每一行命令行滚动式的输出,靠每一次看数据积累的历史经验来判断决定现有的训练流程是否被认可,而DIGITS给大家提供可视化的的操作界面,最后也是可视化判断的输出结果。

DIGITS是一个非常有用的工具,目前NVIDIA在这个工具中已经嵌入了图像分类、目标检测和图像分割三个功能,大家可以非常方便地去使用它,去解决有关图片处理的人工智能开发。上面的图片列出了如何获取DIGITS,可以用Ubuntu 14.04版本这种典型的方式,下载地址也在下面。如果你有其他操作系统的需求,可以看一下图片的右边。最后,有一个非常重要的建议,所使用GPU的计算能力要在3.0以上,cuDNN要选5.0版本。
以上就是我要分享的内容,谢谢大家。
Q&A环节
问题一
张晓冬-上海沐帆科技-技术总监
如何评价计算精度对训练结果的影响。现在有说法是将计算的精度由双精降低到单精度,甚至使用定点精度,只要网络深度足够就对最终结果没有大的影响。这个趋势是否属实? 为何深度网络没有出现那种前端小的扰动导致后续计算结果出现大的偏差?
侯宇涛:由于深度学习是一个直接基于实践结果体验的解决办法,因此计算精度并不能说深度足够就没有太大的影响,对于精度的选择,需要看实际的应用,如果数据足够多、足够大,那么网络深度只是一个方面;如果精度不能满足梯度,对后面的处理就会有很大的影响。因此,不能直接这样去理解,还需要看具体的训练结果,最好的解决办法就是能满足你训练和工程的需求,如果不能,大家可以一同讨论。
对于为什么网络没有出现前端小的扰动导致后续结果出现大的偏差的问题。这是深度学习一个大的优势,在大数据训练的前提下,使得小数据的影响变得不那么重要。对于内部来说,小规模数据的精度和网络实现的影响不是很大,相当于在一亿个人中,一百人的存在对它的影响不是特别大。
问题二
王佐仁-中科院神经所-研究员
1,如何改进深度学习方法从而实现在线的小样本学习?
2,如何增强深度学习的可解释性?
侯宇涛:1、我是这样理解的,在推理端部署了训练和推理两种功能,然后根据实际的情况去启动训练。有一些操作上的细节需要注意,首先,如何启动训练,因为系统无法判断你目前的判断是错误的。要解决这样的问题,建议你使用嵌入式训练会比较快。
2、对于深入学习,专家定义它为黑盒子,在隐藏的网络中,你没有办法从输出端一步步可逆,去看到它如何去形成这些权重的参数。由于深度学习在一些比较关键的流程中都不太管用,在结构上,大家也不知道机器是怎么学出来的。因此对于可解释性,目前还没有看到特别好的解决办法。
问题三
李亚城-中兴-传感器融合工程师
学习深度学习的一个思路和方法是怎样的?从入门新手到高级进阶的思路是什么?
侯宇涛:这个问题比较广泛。在主讲环节也讲过构建和部署深度学习网络需要的几个步骤,你可以从这些步骤中去理解或者探讨,给自己做一个入门的思路。首先,需要有原始数据或者原始网络,有了数据,需要去给数据打标签,去规划和整理数据。这就是如何对数据或者原始网络进行构想,所谓原始网络的构想,由于目前深度神经网络这一行业都是以经验为主,因此你可以去参考一些比较好的网络,这将给你带来非常大的帮助。对于新手来说,还需要去了解Framework,根据你的工作选择更有效的Framework。
另外,还需要了解各种网络,如VGG、GoogleNet等等,也可以从别人成功的经验去参考和理解。从网络到Framework再到数据整理,这些行业预备知识都是需要去了解的,至于后期的高级进阶,也是基于现在初步入门的操作和体验,届时可以专注于自己的某一项长处,比如进行多分类的能力,或者多种数据处理的能力。这些能力可以让你快速地在某一个行业得到领先的机会。当然不止这些,网络优化、网络训练等每一块都有非常多的成功经验,自己也可以去体会各个细分模块的优劣。我认为作为入门级,可以先从数据、网络以及自己对于行业的处理和理解开始,这些将能够帮助你快一点去入门。希望我的分享能给到你一些帮助。
问题四
易礼艳-德赛西威-工程师
深度学习需要大量的样本,当识别效果不佳时,如何判断是样本问题和还是算法问题?
侯宇涛:这个问题也是目前经常存在的问题,由于在训练的过程当中,无法知道是数据集不合适还是算法不合适。我认为,这个时候不需要花太多精力去用一个不能定义的标准来判断另外一个不能定义的物体,而最好的办法就是能够带着你的数据去找一个模型进行迁移式训练的判断。比如在行业中,你了解到谁跟你做差不多的模型,你可以把这个模型拿过来,再把你的数据丢进去,如果这个数据是收敛的,那一定是算法问题,如果这个数据跑不通,那肯定是数据集的问题。
问题五
李太白-中国网安广州分公司-安全工程师
如何更好利用NVIDIA JETSON TX2 进行深度学习方面的应用(TX2适用于什么领域)?
侯宇涛:JETSON TX2是NVIDIA嵌入式GPU平台,主要用于做Inference的,因此你可以使用TX2去做一些嵌入式行业的应用,比如机器人、自动化设备或者与移动行业相关的判断。TX2有着非常强的计算能力,同时它的功耗也不大,低功耗加上强悍的计算能力,也使得它在很多自动驾驶车中得到了应用。
问题六
宋富强-continental-系统工程师
1、如何优化神经网络或者软件架构来提高硬件的效率(英伟达芯片功耗高,效率就不会很突出)?
2、没有硬件资源的开发者怎么来使用英伟达云端服务器做开发?
侯宇涛:1、按照我的理解,您的问题应该是在推演端。在推演端,我们现在有Tegra,它的功耗从十几W到二十多W,效率也比较高。我觉得您说的不是训练平台,因为训练平台在数据中心应该是以计算为主,从功耗上来说,整体的计算体系的功耗要远小于同样计算能力GPU计算集群的功耗。因此如果在训练端,应该不会存在这个问题。对于推演端,您可以用低功耗的Tegra,它会帮助你快速地达到你的需求。
2、NVIDIA没有云端服务器,我们有各种各样与服务器相关的云端解决方案,咱们中国的阿里云有提供有云端服务器GPU云,您可以去买它的服务来做开发,它是基于NGC(NVIDIA GPU Cloud),同时它里面也有配置好的各种Framework环境,非常方便和好用。











