
YOLOv8 来啦!一文带你解读 YOLO"内卷"期的模型选型
2023-02-28 11:10
 分享到微信
分享到微信
 分享到微博
分享到微博
本次为大家带来 YOLOv8、PP-YOLOE+等 YOLO 全系列体验。欢迎广大开发者使用 NVIDIA 与飞桨联合深度适配的 NGC 飞桨容器,在 NVIDIA GPU 上体验 PaddleDetection v2.5 的新特性。
PaddleDetection 快速体验 YOLO 全系列模型
回顾整个虎年,堪称 YOLO 内卷元年,各路 YOLO 系列神仙打架,各显神通。一开始大部分用户做项目做实验还是使用的 YOLOv5,然后 YOLOv6、YOLOv7、PP-YOLOE+、DAMO-YOLO、RTMDet 就接踵而至,于是就在自己的数据集逐一尝试,好不容易把这些下饺子式的 YOLO 模型训练完测试完,忙完工作准备回家过年时,YOLOv8 又闪电发布,YOLOv6 又更新了 3.0 版本...用户还得跟进继续训练测试,其实很多时候就是重复工作。此外换模型训练调参也会引入更多的不确定性,而且往往业务数据集大则几十万张图片,重训成本很高,但训完了新的精度不一定更高,速度指标在特定机器环境上也未必可观,参数量、计算量的变化尤其在边缘设备上也不能忽视。所以在这样的内卷期,作为开发者我们应该怎么选择一个适合自己的模型呢?

为了方便统一 YOLO 系列模型的开发测试基准,以及模型选型,百度飞桨推出了 PaddleYOLO 开源模型库,支持 YOLO 系列模型一键快速切换,并提供对应 ONNX 模型文件,充分满足各类部署需求。此外 YOLOv5、YOLOv6、YOLOv7 和 YOLOv8 在评估和部署过程中使用了不同的后处理配置,因而可能造成评估结果虚高,而这些模型在 PaddleYOLO 中实现了统一,保证实际部署效果和模型评估指标的一致性,并对这几类模型的代码进行了重构,统一了代码风格,提高了代码易读性。下面的讲解内容也将围绕 PaddleYOLO 相关测试数据进行分析。
完整教程文档及模型下载链接:
https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.5/docs/feature_models/PaddleYOLO_MODEL.md
YOLO 系列多硬件部署示例下载链接:
https://github.com/PaddlePaddle/FastDeploy/blob/develop/examples/vision/detection/paddledetection
总体来说,选择合适的模型,要明确自己项目的要求和标准,精度和速度一般是最重要的两个指标,但还有模型参数量、FLOPs 计算量等也需要考虑。接下来就具体讲一讲这几个关键点。
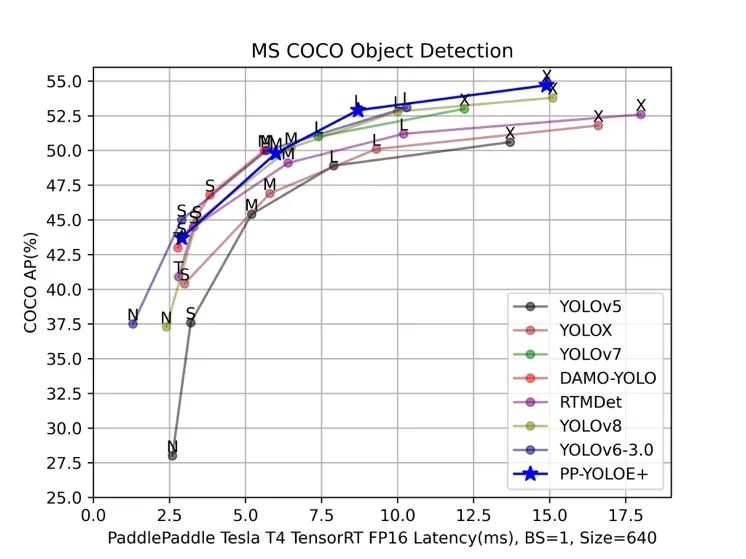
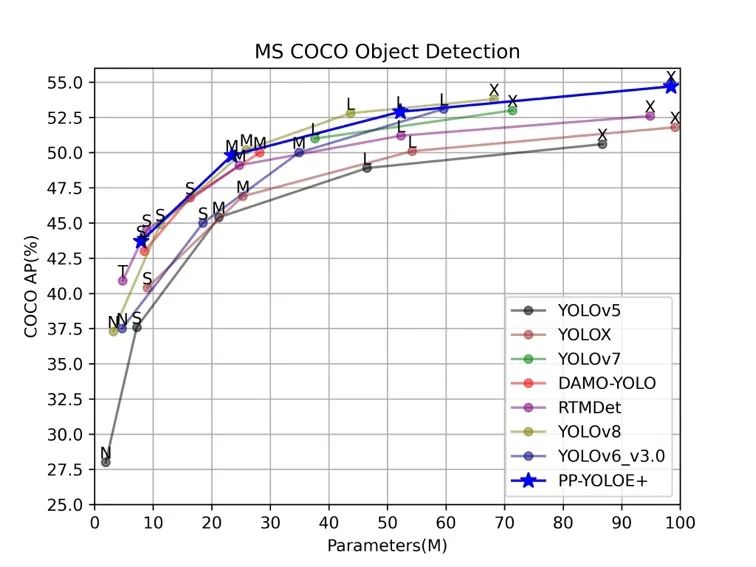
STEP1. 看精度
首先是精度,从上图 YOLO 系列 Benchmark 图可以看出,几乎每个模型的目标都是希望自己的模型折线在坐标轴上是最高的,这也是各个模型的主要竞争点。各家都会训练业界权威的 COCO 数据集去刷高精度,但是迁移到实际业务数据集上时,效果哪个高并不一定,各个模型的泛化能力并不和 COCO 数据集上的精度正相关。COCO 数据集精度差距在 1.0 以内的模型,其实业务数据集上差别不会很大,而且实际业务项目一般也不会只看 mAP 这一个指标,也可能需要关注 AP50、AP75、Recall 等指标。
要想在业务数据集达到较高精度,最重要是一点其实是加载一个较强的预训练(pre-trained)权重。COCO 预训练权重可以极快收敛,精度也会远高于用 ImageNet 预训练权重训的。一个较强的预训练在下游任务中的效果会优于绝大多数的调参和算法优化。在 2022 年 9 月份,飞桨官方将 PP-YOLOE 模型升级为 PP-YOLOE+,最重要的一点就是提供了 Objects365 大规模数据集的预训练权重,Objects365 数据集含有的数据量可达百万级,在大数据量下的训练可以使模型获得更强大的特征提取能力、更好的泛化能力,在下游任务上的训练可以达到更好的效果。基于 Objects365 的 PP-YOLOE+预训练模型,将学习率调整为原始的十分之一,在 COCO 数据集上训练的 epoch 数从300减少到了只需 80,大大缩短了训练时间的同时,获得了精度上的显著提升。实际业务场景中,在遇到比 COCO 更大规模数据集的情况下,传统的基于 COCO 预训练的模型就显得杯水车薪了,无论训练 200 epoch还是80 epoch,模型收敛都会非常慢,而使用 Objects365 预训练模型可以在较少的训练轮次 epoch 数如只 30 个 epoch,就实现快速收敛并且最终精度更高。
此外还有一些自监督或半监督策略可以继续提升检测精度,但是对于开发者来讲,时间资源、硬件资源消耗极大,以及目前的开发体验还不是很友好,需要持续优化。
STEP2. 看速度
速度不像精度很快就能复现证明的,鉴于各大 YOLO 模型发布的测速环境也不同,还是得统一测试环境进行实测。上图是飞桨团队在飞桨框架对齐各大模型精度的基础上,统一在 Tesla T4 上开启 TensorRT 以 FP16 进行的测试。
另外需要注意的是,各大 YOLO 模型发布的速度只是纯模型速度,是去除 NMS(非极大值抑制)的后处理和图片前处理的,实际应用端到端的耗时还是要加上 NMS 后处理和图片前处理的时间,以及将数据从 CPU 拷贝到 GPU/XPU 等加速卡上和将数据从加速卡拷贝到 CPU 的时间。通常 NMS 的参数对速度影响极大,尤其是 score threshold(置信度阈值) 、NMS 的 IoU 阈值、top-k 框数(参与 NMS 的最多框数)以及 max_dets(每张图保留的最多框数) 等参数。
比如最常用的是调 score threshold,一般为了提高 Recall(召回率)都会设置成 0.001、0.01 之类的,但其实这种置信度范围的低分框对实际应用来说意义不大;如果设置成 0.1、0.2 则会提前过滤掉众多的低分框,这样 NMS 速度和整个端到端部署的速度就会显著上升,代价是掉一些 mAP,但对于结果可视化在视觉效果上其实影响很小。
STEP3. 看参数量、计算量
这方面在学术研究场景中一般不会着重考虑,但是在产业应用场景中就非常重要,需要注意设备的硬件限制。例如堆叠一些模块结构来改造原模型,增加了 2~3 倍参数量提高了一点点 mAP,这是 AI 竞赛常用的“套路”,精度虽然有少许提升,但速度变慢了很多,参数量和 FLOPs 也都变大了很多,对于产业应用来说意义不大,又如一些特殊模块,例如 ConvNeXt,参数量极大但是 FLOPs 很小,虽然可以提升精度,但也会降低速度,参数量也可能受设备容量限制。
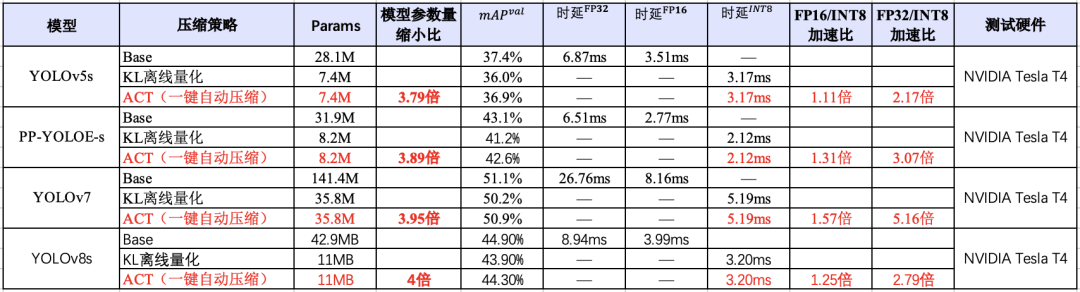
在对资源、显存及其敏感的场景,除了选择参数量较小的模型,也需要考虑和压缩工具联合使用。如下图所示,在 YOLO 系列模型上,使用 PaddleSlim 自动压缩工具(ACT)压缩后,可以在尽量保证精度的同时,降低模型大小和显存占用,并且该能力已经在飞桨全场景高性能 AI 部署工具 FastDeploy 中集成,实现一键压缩。
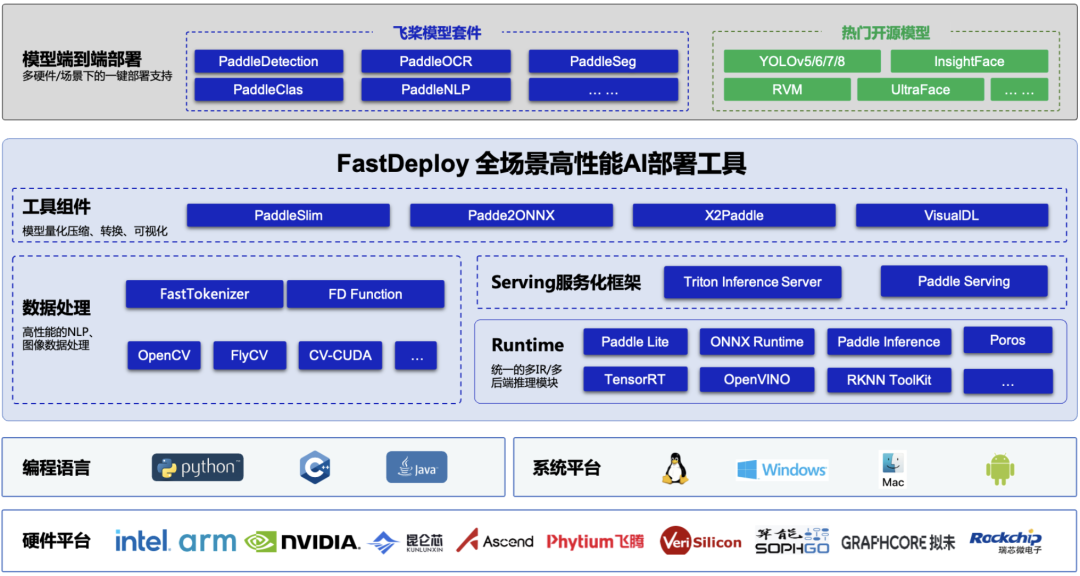
FastDeploy 快速部署
基于产业落地部署需求,全场景高性能 AI 部署工具 FastDeploy 统一了飞桨的推理引擎和生态推理引擎(包括 Paddle Inference、Paddle Lite、TensorRT、Poros 等多推理后端),并融合高性能 NLP 加速库 FastTokenizer、CV 高新能加速库 CV-CUDA,实现了AI 模型端到端的推理性能优化,支持 YOLOv5、YOLOv8、PP-YOLOE+等在内的 160 多个产业级特色模型。支持 NVIDIA Jetson、NVIDIA GPU 等全系列硬件,同时支持高性能服务化部署,助力企业用户快速完成 AI 模型部署。
加入 PaddleDetection 技术交流群,体验 NVIDIA NGC + PaddleDetection
入群方式:微信扫描下方二维码,关注公众号,填写问卷后进入微信群随时进行技术交流,获取 PaddleDetection 学习大礼包

NGC 飞桨容器介绍
如果您希望体验 PaddleDetection v2.5 的新特性,欢迎使用 NGC 飞桨容器。NVIDIA 与百度飞桨联合开发了 NGC 飞桨容器,将最新版本的飞桨与最新的 NVIDIA 的软件栈(如 CUDA)进行了无缝的集成与性能优化,最大程度的释放飞桨框架在 NVIDIA 最新硬件上的计算能力。这样,用户不仅可以快速开启 AI 应用,专注于创新和应用本身,还能够在 AI 训练和推理任务上获得飞桨+NVIDIA 带来的飞速体验。
最佳的开发环境搭建工具 - 容器技术
容器其实是一个开箱即用的服务器。极大降低了深度学习开发环境的搭建难度。例如你的开发环境中包含其他依赖进程(redis,MySQL,Ngnix,selenium-hub 等等),或者你需要进行跨操作系统级别的迁移
容器镜像方便了开发者的版本化管理
容器镜像是一种易于复现的开发环境载体
容器技术支持多容器同时运行
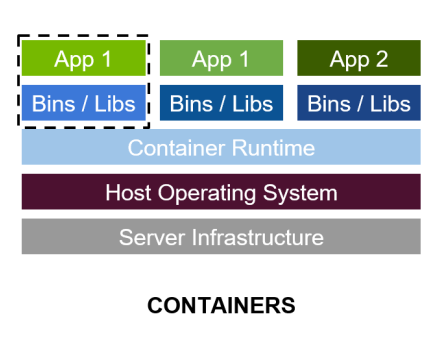
最好的 PaddlePaddle 容器
NGC 飞桨容器针对 NVIDIA GPU 加速进行了优化,并包含一组经过验证的库,可启用和优化 NVIDIA GPU 性能。此容器还可能包含对 PaddlePaddle 源代码的修改,以最大限度地提高性能和兼容性。此容器还包含用于加速 ETL (DALI, RAPIDS),、训练(cuDNN, NCCL)和推理(TensorRT)工作负载的软件。
PaddlePaddle 容器具有以下优点:
适配最新版本的 NVIDIA 软件栈(例如最新版本 CUDA),更多功能,更高性能
更新的 Ubuntu 操作系统,更好的软件兼容性
按月更新
满足 NVIDIA NGC 开发及验证规范,质量管理
通过飞桨官网快速获取

环境准备
使用 NGC 飞桨容器需要主机系统(Linux)安装以下内容:
Docker 引擎
NVIDIA GPU 驱动程序
NVIDIA 容器工具包
有关支持的版本,请参阅 NVIDIA 框架容器支持矩阵 和 NVIDIA 容器工具包文档。
不需要其他安装、编译或依赖管理。无需安装 NVIDIA CUDA Toolkit。
NGC 飞桨容器正式安装:
要运行容器,请按照 NVIDIA Containers For Deep Learning Frameworks User’s Guide 中 Running A Container 一章中的说明发出适当的命令,并指定注册表、存储库和标签。有关使用 NGC 的更多信息,请参阅 NGC 容器用户指南。如果您有 Docker 19.03 或更高版本,启动容器的典型命令是:
*详细安装介绍 《NGC 飞桨容器安装指南》
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/install_NGC_PaddlePaddle_ch.html
*详细产品介绍视频
【飞桨开发者说|NGC飞桨容器全新上线 NVIDIA产品专家全面解读】
https://www.bilibili.com/video/BV16B4y1V7ue?share_source=copy_web&vd_source=266ac44430b3656de0c2f4e58b4daf82
飞桨与 NVIDIA NGC 合作介绍
NVIDIA 非常重视中国市场,特别关注中国的生态伙伴,而当前飞桨拥有超过 470 万的开发者。在过去五年里我们紧密合作,深度融合,做了大量适配工作,如下图所示。

今年,我们将飞桨列为 NVIDIA 全球前三的深度学习框架合作伙伴。我们在中国已经设立了专门的工程团队支持,赋能飞桨生态。
为了让更多的开发者能用上基于 NVIDIA 最新的高性能硬件和软件栈。当前,我们正在进行全新一代 NVIDIA GPU H100 的适配工作,以及提高飞桨对 CUDA Operation API 的使用率,让飞桨的开发者拥有优秀的用户体验及极致性能。
以上的各种适配,仅仅是让飞桨的开发者拥有高性能的推理训练成为可能。但是,这些离行业开发者还很远,门槛还很高,难度还很大。
为此,我们将刚刚这些集成和优化工作,整合到三大产品线中。其中 NGC 飞桨容器最为闪亮。
NVIDIA NGC Container – 最佳的飞桨开发环境,集成最新的 NVIDIA 工具包(例如 CUDA)












