Merlin HugeCTR v4.3 发布说明
2023-01-11 19:23
 分享到微信
分享到微信
 分享到微博
分享到微博
新增内容
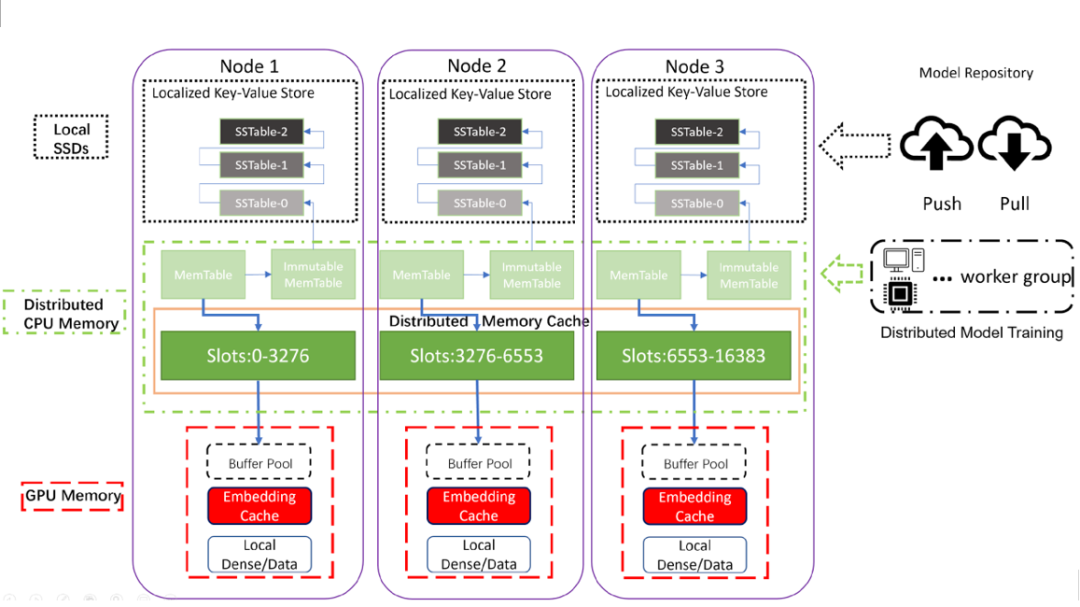
HugeCTR 分层参数服务器(HPS)更新:
RedisClusterBackend 现在支持 TLS/SSL 通信。相关示例代码,请参阅分层参数服务器演示笔记本。该笔记本更新了分步说明,向您展示如何设置 HPS 以使用带(和不带)加密的 Redis。同时, 易失性数据库参数 文档对 enable_tls、tls_ca_certificate、tls_client_certificate、tls_client_key 和 tls_server_name_identification 等参数进行了更新。
对 Embedding 缓存添加了静态表支持。当 Embedding 表可以完全放在 GPU 内存中时,静态表是合适的。在这种情况下,静态表比 Embedding 缓存查找快三倍以上。当然,静态表将不支持 Embedding 的更新。
用于 TensorFlow 与 TensorFlow-TensorRT 集成的 HPS 插件 (TF-TRT):有关示例代码请参阅部署 SavedModel 笔记本
Redis 或 Kafka 使用的更改:更新了用 RedisClusterBackend 和用 Kafka 参数流部署模型的方式。使用了 HPS 分区选择算法的第三方库以提高性能。新算法可以为易失性数据库生成不同的分区分配。
新易失性数据库类型:此版本将 multi_process_hash_map 的 db_type 值添加到分层参数服务器。此数据库类型支持使用共享内存和 /dev/shm 设备文件跨进程的共享 Embedding。运行 HPS 的多个进程可以读取和写入同一个哈希映射。
HPS Redis 后端的优化:在此版本中,分层参数服务器可以并行打开多个连接到每个 Redis 节点。此增强功能使 HPS 能够利用 Redis 服务器 I/O 模块中的重叠处理优化。此外,HPS 现在可以利用 Redis 散列标签来共同定位 Embedding 值和元数据。此增强功能可以减少对 Redis 节点的访问次数以及完成事务所需的每个节点往返通信的次数。
向 ONNX 模型转换器添加了多任务模型支持:此版本向 ONNX 转换器添加了对多任务模型的支持。此版本还包括对 preprocess_census.py 脚本的更新。
删除了对一些库的依赖。
Layer 以及优化器的更新以及新的模型支持:
增加了对动态 Embedding 表 (DET) 的 SGD、Momentum SGD、Nesterov Momentum、AdaGrad、RMS-Prop、Adam 和 FTRL 优化器的支持。示例代码请参考目录中的test_embedding_table_optimizer.cpp 文件 test/utest/embedding_collection/ 目录。
添加了对稠密网络 FTRL 优化器的支持。
支持了 BERT 和其变体:包括对 MultiHeadAttention 层并为序列掩码层。有关详细信息,请参阅 samples/bst 目录。
Deep & Cross Network Layer 版本 2 支持:有关概念信息,请参阅 https://arxiv.org/abs/2008.13535。多交叉层文档也已更新。
MLP Layer 更新:添加了一个带有 hugectr.Layer_t.MLP 类的 MLP 层。该层非常灵活,可以更轻松地使用一组融合的全连接层并启用相关优化。对于 MLPLayer 中的每个融合全连接层,输出维度、偏差和激活函数都是可调的。MLPLayer 支持 FP32、FP16 和 TF32 数据类型。有关示例请参阅 dlrm 目录中的 dgx_a100_mlp.py 以了解如何使用该层。
Sparse Operation Kit(SOK) 的更新:
DeepRec 中 Sparse Operation Kit 的增强功能:此版本包括对 Sparse Operation Kit 的更新,以提高 DeepRec 中 Embedding 变量查找操作的性能。lookup_sparse() 函数的 API 已更改以删除热度参数。lookup_sparse() 函数得到优化,可以动态计算非零元素的数量。有关详细信息,请参阅 sparse_operation_kit 目录 。
Sparse Operation Kit 可从 PyPi 安装:1.1.4 版的 SOK 可从 PyPi 安装了。
HugeCTR I/O 模块更新:
支持了在离线推理中从远端文件系统(HDFS, S3 等)中读取推理数据:HugeCTR 除了训练时读取外,现在还支持离线推理时通过 DataSourceParams API 从远程文件系统如 HDFS 和 S3 读取数据。HugeCTR Training and Inference with Remote File System Example 已更新以展示这个新功能。
修复的问题
已知问题
以下是目前 HugeCTR 存在的已知问题,我们将在之后的版本中尽快修复:
如果客户端代码调用 RMM rmm::mr::set_current_device_resource() 方法或 rmm::mr::set_current_device_resource() 方法,HugeCTR 可能会出现运行时错误。该错误是由于 HugeCTR 中的 Parquet 数据读取器也调用了 rmm::mr::set_current_device_resource(),因此该设备对同一进程中的其他库可见。参考 GitHub 问题 #356 以获取更多信息。作为解决方法,如果您知道 rmm::mr::set_current_device_resource() 被 HugeCTR 以外的客户端代码调用,您可以将环境变量 HCTR_RMM_SETTABLE 设置为 0 以防止 HugeCTR 设置自定义 RMM 设备资源。但要小心,因为该设置会降低 Parquet 读取的性能。
HugeCTR 使用 NCCL 在队列之间共享数据,并且 NCCL 可能需要共享系统内存用于 IPC 和固定(页面锁定)系统内存资源。如果您在容器内使用 NCCL,请在启动容器时通过指定参数 -shm-size=1g -ulimit memlock=-1 来增加这些资源。
即使目标 Kafka 代理没有响应,KafkaProducers 启动也会成功。为避免与来自 Kafka 的流模型更新相关的数据丢失,您必须确保足够数量的 Kafka 代理正在运行、正常运行,并且可以从运行 HugeCTR 的节点访问。
文件列表中的数据文件数量应大于或等于数据读取器工作人员的数量。否则,不同的 worker 会映射到同一个文件,并且数据加载不会按预期进行。
暂时不支持使用正则化器的联合损失训练。
暂时不支持将 Adam 优化器状态导出到 AWS S3。
HugeCTR v4.3 发布说明,已更新至 GitHub 和文档:
GitHub:
https://github.com/NVIDIA-Merlin/HugeCTR
文档:
https://nvidia-merlin.github.io/HugeCTR/master/hugectr_user_guide.html
从 2023 年一月起,HugeCTR 的版本号将从数字版本(v.4.4)变更为年历版本(v23.01)。











