
NVIDIA TensorRT 加速 GALA Sports Arena4D 打造实时数字化运动场景
2022-03-22 20:32
 分享到微信
分享到微信
 分享到微博
分享到微博
望尘科技(GALA Sports)于 2013 年在深圳成立,是一家以技术为驱动的互联网公司,多年来一直专注于体育游戏和赛场数字化,致力于为用户提供高品质的体育在线娱乐体验,目前团队成员 300 余人,分别于深圳、成都设有办公地点。
凭借历年来在体育游戏市场的深耕与稳定的高质量产品研发,望尘科技推出了《足球大师》、《NBA 篮球大师》、《最佳 11 人》等多款体育类手游,与 FIFPro、NBA、皇马、巴萨、拜仁、曼城等体育联盟及豪门俱乐部保持着长期的合作关系。在赛场三维重构、人体运动模拟、球类竞技 AI、表情与肌肉物理模拟、超写实数字人、大场景渲染等几个领域处于国内外领先地位。
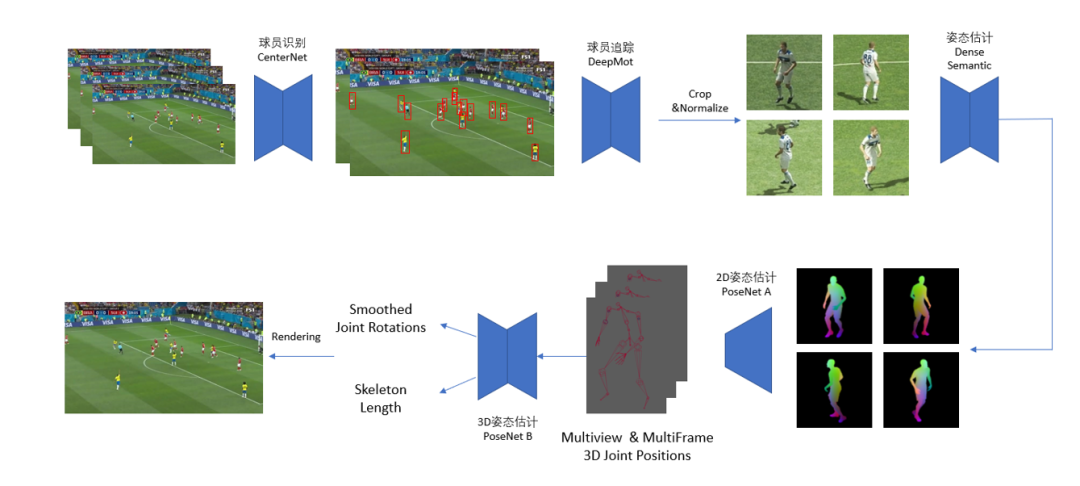
而本文将为您详细介绍 GALA Sports 的 Arena4D 方案如何藉由 NVIDIA 解决方案,能在使用多个高清摄像机时,同时将数据传输到一个本地 HPC 中,经过一系列的神经网络流水线,实时计算出每个运动员的位置与姿态,从而将整个比赛场景数字化。

(图片来源于望尘科技授权)
Arena4D 的中央处理 HPC 需要以 30FPS 的速度处理 4-12 个 4K 相机的数据,流水线包括图像前处理、运动员追踪与识别、球的追踪识别、骨骼关键点识别,多帧时间轴降噪等多个算法模块,为了达到实时计算,Arena4D 使用了 NVIDIA A100 GPU 加速神经网络计算,并使用 Tensor RT、CUDA 进行深度优化,经过优化部署的算法计算速度相对于早期算法原型有 10 倍以上的性能提升。
(图片来源于望尘科技授权)
而在系统优化的过程中,GALA Sports 团队也面临着不同的挑战,包含了:
1. 多台高清摄像头每帧图像需上传到显卡进行实时转码、降噪等前处理工作,数据吞吐量较大。
2. 基于神经网络的计算流水线,需要实时进行多个视角、多个运动员的追踪、识别、姿态估计与降噪计算。
3. 在多个 AI 模型级联计算流水线中,每个 AI 模型之间的数据处理与拷贝占用了大量的时间。
基于以上挑战,GALA Sports 选择了 NVIDIA 提供的 AI 加速解决方案——TensorRT。
针对多相机从内存到显存大量数据拷贝 IO bound 问题,GALA Sports 团队 使用 CUDA 多流技术实现了内存拷贝与数据处理并行化,降低了 overhead,4 路 4k 相机数据的拷贝与转码从约 50ms 减少到 30ms。
针对神经网络流水线的计算延迟问题,首先 GALA Sports 团队根据体育比赛的使用场景与相机视角对模型结构进行了优化,根据不同体育类型的相机机位和球场尺度,设计了专门针对特定比赛的识别网络,大大降低了网络的复杂度;然后使用量化工具对网络进行 fp16 量化加速,最后使用 TensorRT 针对 A100 编译,在 A100 上能达到最优性能的模型。

针对计算流水线模型之间数据处理耗时的问题,首先 GALA Sports 团队通过合并部分神经网络模型重新训练,然后对于必须保留的数据处理代码,用 CUDA C++ 重写了大部分数据处理的 kernel,并针对 A100 的硬件结构对并行参数进行调优,最终将数据处理 30ms 的计算时间降低到 5ms。

(图片来源于望尘科技授权)
最终,以足球场场景为例,追踪目标为 1 个足球 + 22 名球员 + 3 名教练的位置与骨骼,在 1 张 A100 设备上 NVIDIA 实现了平均 50ms/帧的速度,在 2 张 A100 设备上能达到平均 30ms/帧的速度,整个流水线比原型提升了 18 倍。
基于上述方法优化后,GALA Sports 团队发现整个推理端算法流水线,相较于未用 TensorRT 与 CUDA 优化的算法原型,竟实现了 18 倍的性能提升,使超大规模体育场景的姿态捕捉与重建的实时计算成为可能,在体育比赛过程中的实时计算产生了许多新的用途,而 GALA Sports 的客户能够将这些数字化内容用于直播解说、实时战术分析、自由视角回放、比赛结果预测等新场景,提升了系统方案的价值。
GALA Sports的硬件方案也从 4 台 HPC 缩减到 1 台 HPC 搭载 2 张 A100 GPU,不仅显著地降低了成本,也显著降低了系统维护和使用的复杂度,提升了系统可靠度。
后续,GALA Sports 团队也将计划:
通过将流水线中部分网络使用 Int8 量化以进一步提升性能;
将整体流水线迁移到 CUDA C++ 代码中进一步提升性能;
把性能提升空余的计算资源用于提升网络模型的复杂度以提升精度;
将 CenterNet 与 Dense Sematic 网络特征提取部分替换成 Vision Transformer 以提升精度;
使用 Nsight 在 A100 真实环境中进一步 profile,减少 overhead。











