


每天,数以万计的语音助手、翻译、推荐、视频管理、自动驾驶等各类新兴服务,都在以超快速度完成深度学习推理。
用户会看重AI产品的实时性、高准确度,而对于开发者来说,要考虑到的因素更多,不仅要满足最终用户的需求,还要考虑成本、能效等因素,因而,能满足可编程性、低延迟、高准确度、高吞吐量、易部署的成套AI推理软硬件组合成为开发者的心头好。
而配备NVIDIA TensorRT超大规模推理平台的GPU可以说是学术界和产业界最受欢迎的AI推理组合之一,它们可以带来速度、准确度和快速响应能力的成倍提升。
去年NVIDIA最新发布的Tesla T4 GPU,因其专为推理而生的超高效率、超低功耗,能为开发者节省大笔预算,已成为业界首选AI推理神器。
本期的智能内参,我们对《NVIDIA AI推理平台》白皮书进行解读,看NVIDIA超大规模推理平台如何协同顶尖AI推理加速器Tesla T4 GPU,为深度学习推理带来吞吐量、速度等性能的倍增,并降低数据中心运营商的开发成本。如果想查阅此白皮书《NVIDIA AI 推理平台》,可直接点击“我要下载”下载。
一、NVIDIA GPU推理的应用价值
NVIDIA AI推理平台就像一个隐形的推理助手,正通过互联网巨头的超大规模数据中心,为人们带来各种新鲜且高效的AI体验。

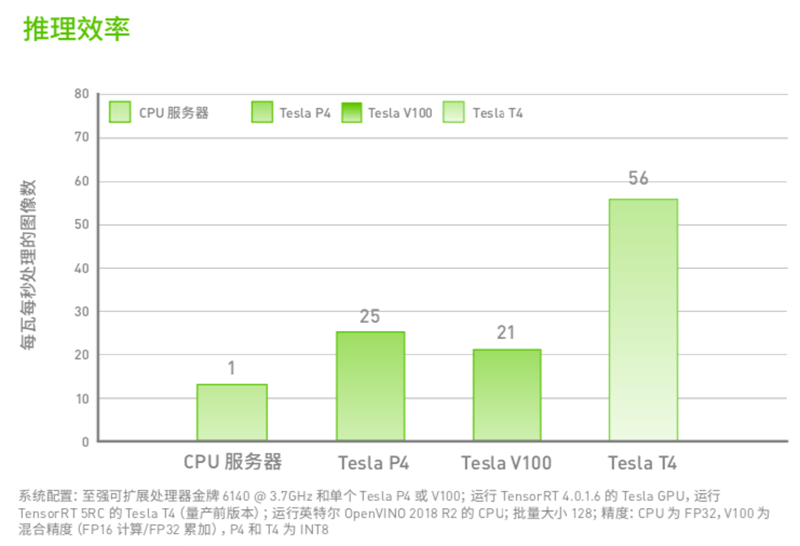
相比传统的CPU服务器,GPU产品推理组合不仅能提升推理性能,还能更节省成本。
比如京东的视频审核就使用NVIDIA AI平台,将服务器数量减少了83%。
每天由第三方商家上传到京东POP平台的视频数据不计其数,京东必须确保上传的信息安全无害。
以前,要审核1000路的视频流,京东必须在云端部署1000枚CPU,而使用NVIDIA AI推理平台后,吞吐量提升20倍,速度比CPU快40倍,1台配备4个Tesla P40的服务器能代替超过约50台CPU服务器。

T4作为NVIDIA专为加速AI推理打造的GPU,在推理性能和能效比上一代产品P4更胜一筹。
如图,左边是200台占用四个机架的CPU服务器,支持语音、NLP和视频应用,功耗达60千瓦。而相同的吞吐量和功能,一台搭载16块T4 GPU的服务器就足矣,不仅如此,这台服务器还将功耗降为原来的1/30。

二、基于Turing架构的Tesla T4 GPU
NVIDIA Tesla T4 GPU是全球顶尖的通用加速器,适用于所有AI推理工作负载,不仅有小巧的外形规格和仅70瓦的超低功耗,而且效率比前一代Tesla P4超出两倍以上。
它采用的Turing架构,除了继承Volta架构为CUDA平台引入的增强功能外,还新增独立线程调度、统一内存寻址等许多适合推理的特性。
Turing GPU能提供比历代GPU更出色的推理性能、通用性和高效率,这主要归功于如下几个创新特性:
1、新型流式多元处理器(SM)
新型SM具有Turing Tensor核心,基于Volta GV100架构上经过重大改进的SM而构建。
它能像Volta Tensor核心一样,可提供FP16和FP32混合精度矩阵数学,还新增了INT8和INT4精度模式。
通过实现线程间细粒度同步与合作等功能,Turing SM使得GPU的性能和能效均远高于上一代Pascal GPU,同时简化了编程。
2、包含实验特性,首用GDDR6
Turing是首款采用GDDR6显存的GPU架构,最高可提供320GB/s的显存带宽,其存储器接口电路也经过全面重新设计。
相比此前Pascal GPU使用的GDDR5X。Turing的GDDR6将速度提升40%,能效提升20%。
3、专用硬件转码引擎
视频解码正呈现爆炸式增长,在内容推荐、广告植入分析、无人车感知等领域都获得大规模应用。
T4凭借专业的硬件转码引擎,将解码能力提升至上代GPU的两倍,可以解码多达38路全高清视频流,而且能在不损失视频画质的前提下实现快速编码或最低比特率编码。
三、超大规模推理平台TensorRT
仅有强大硬件还不够,要搭配高适配度的软件工具,才能最大化硬件算力的利用率,为开发者带来更完整和优化的开发体验。
NVIDIA加速推理的优势也正是在软硬件的结合上凸显出来,既有专为深度学习定制的处理器,又具备软件可编程特质,还能加速TensorFlow、PyTorch、MXNet等各种主流深度学习框架,为全球开发者生态系统提供支持。
面向深度学习推理,NVIDIA提供了一套完整的推理套餐——TensorRT超大规模推理平台。
TensorRT包含T4推理加速器、TensorRT5高性能深度学习推理优化器和运行时、TensorRT推理服务三部分,支持深度学习推理应用程序的快速部署。
其中,TensorRT5将能够优化并精确校准低精度网络模型的准确度,最终将模型部署到超大规模数据中心、嵌入式或汽车产品平台。
TensorRT推理服务是NVIDIA GPU Cloud免费提供的即用型容器,能提高GPU利用率,降低成本,还能简化向GPU加速推理框架的转换过程,更加节省时间。
配备TensorRT的GPU,推理性能最高可达CPU的50倍。
这得益于TensorRT对网络结构的重构与优化。在精度方面,TensorRT提供INT8和FP16优化,通过降精度推理,在显著减少应用程序的同时保持高准确度,满足许多实时服务的需求。
另外,TensorRT还通过融合内核的节点,优化GPU显存和带宽的使用,并以更大限度减少显存占用,以高效方式重复利用张量内存。
TensorRT和TensorFlow现已紧密集成,Matlab也已通过GPU编码器实现与TensorRT的集成,能协助工程师和科学家在使用MATLAB时为Jetson、NVIDIA DRIVE和Tesla平台自动生成高性能推理引擎。
TensorRT和Turing架构两相结合,能提供高达CPU服务器45倍的吞吐量。
智东西认为,深度学习推理需要强大的计算平台,来满足云端与终端日益增长的AI处理需求。而一款强大的计算平台不仅需要强大的芯片,还需要完整的软件工具。
通过软硬件协同作用,NVIDIA TensorRT能在带来高吞吐量和高能效的同时,实现推理神经网络的快速优化、验证和部署,既能降低开发门槛,又能节省服务器成本,使得工程师和科学家更好地专注于深度学习研究,推动各行业智能化升级。
如需查阅此白皮书《NVIDIA AI 推理平台》,可直接点击“我要下载”下载。




