 分享到微信
分享到微信
 分享到微博
分享到微博
内容介绍
找到正确的自动驾驶训练数据并不需要花费大量人力进行标记。
任务:
优化夜间行人检测
方法:
主动学习
读一本关于特定主题的书或者读很多包含相似内容的书不会使你成为专家。真正掌握一项技能或了解一个知识领域,需要了解各种不同来源的大量信息。
自动驾驶和其他人工智能技术也是如此。
负责自动驾驶功能的深度神经网络需要详尽的训练。该训练需要包含各种情况,无论是在日常道路中可能遇到的情况,还是希望它们永远不会遇到的不寻常情况。成功的关键是确保其接受了正确的数据训练。
什么是正确的数据?那就是新的或不确定的情况, 而不是一遍又一遍地重复相同的场景。
主动学习是一种用于机器学习的训练数据筛选方法,它可以自动找到这些多样化的数据。相较于人工操作, 它只需花费一小部分时间即可构建更好的数据集。
它采用训练有素的模型来处理收集来的数据,并对无法识别的帧进行标记从而发挥作用。这些帧随后会由人工标记, 然后将它们添加到训练数据中。这可以提高模型在恶劣条件下感知物体等情况下的准确性。
在数据中“大海捞针”
训练自动驾驶汽车所需的数据量十分巨大。RAND公司的专家预估,汽车需要拥有110亿英里的行驶经验才能比人类操作好20%。这意味着在现实世界中,我们需要一个共有100辆车的车队不间断驾驶500多年才能获得相应的驾驶经验。
而且,不是任何驾驶数据都是有效的。有效的训练数据必须包含各种挑战性的驾驶情况,以确保汽车能够安全行驶。
如果为了找到这些驾驶场景而要给这些检验数据添加注释,在100辆车一天驾驶8个小时的情况下,则需要超过100万个人员为来自车上所有摄像头的数据打标签,这将是一项巨大的工作。除了人工成本外,在此数据上训练DNN所需的计算和存储资源也是不切实际的。
数据注释和管理的结合对自动驾驶汽车的开发带来了重大挑战。通常在此过程中,我们会应用AI来减少训练的时间和成本,同时还可以提高网络的准确性。
为什么是主动学习
选择自动驾驶DNN训练数据有常见的三种方法。随机抽样以均匀的间隔从数据池中提取帧,能够捕获最常见的场景,但也可能会遗漏不常见的模式。
基于元数据的抽样使用基本标签(例如,雨水、夜晚)来选择数据,从而很容易找到常见的困难情况,但是却丢失了不容易分类的独特的帧,例如拖拉机拖车或踩着高跷的人穿过马路。

注释:并非所有数据都是公平创建的。常见公路场景的示例(左上)与一些不寻常的驾驶场景(右上:骑自行车的人在夜间玩自行车,左下:卡车拖挂拖车,右下:行人踩高跷)。
最后,手动管理将元数据
标签与人工注释者的可视化浏览结合使用,这是一个耗时的工作,容易出错且难以扩展。
通过主动学习,可以在选择有价值的数据点时自动执行筛选过程。首先,训练一个针对已标记数据的专用DNN。然后,网络会对未标记的数据进行分类,筛选无法识别的帧,从而找到对自动驾驶汽车算法具有挑战性的数据。
然后,这些数据将由人工注释者进行审查和标记,并添加到训练数据库中。
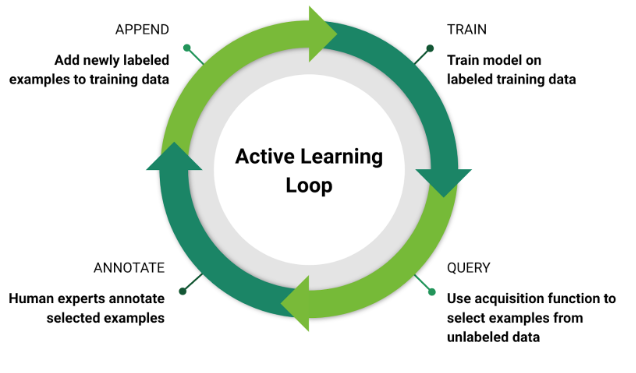
主动学习已经表明,与手动管理相比,它可以提高自动驾驶DNN的检测准确性。在我们自己的研究中,NVIDIA团队发现与手动选择的数据相比,使用主动学习数据进行训练时,行人检测的精度提高了3倍,自行车检测的精度提高了4.4倍。
在可靠且可扩展的AI基础架构上运行时,像主动学习、迁移学习和联邦学习这样的高级训练方法最有效。通过这些方式可以实现并行管理大量数据,从而缩短了开发周期。
NVIDIA将为开发人员开放这些训练工具以及NVIDIA GPU Cloud容器注册表上丰富的自动驾驶深度神经网络库。
任务:
优化夜间行人检测
方法:
主动学习
读一本关于特定主题的书或者读很多包含相似内容的书不会使你成为专家。真正掌握一项技能或了解一个知识领域,需要了解各种不同来源的大量信息。
自动驾驶和其他人工智能技术也是如此。
负责自动驾驶功能的深度神经网络需要详尽的训练。该训练需要包含各种情况,无论是在日常道路中可能遇到的情况,还是希望它们永远不会遇到的不寻常情况。成功的关键是确保其接受了正确的数据训练。
什么是正确的数据?那就是新的或不确定的情况, 而不是一遍又一遍地重复相同的场景。
主动学习是一种用于机器学习的训练数据筛选方法,它可以自动找到这些多样化的数据。相较于人工操作, 它只需花费一小部分时间即可构建更好的数据集。
它采用训练有素的模型来处理收集来的数据,并对无法识别的帧进行标记从而发挥作用。这些帧随后会由人工标记, 然后将它们添加到训练数据中。这可以提高模型在恶劣条件下感知物体等情况下的准确性。
在数据中“大海捞针”
训练自动驾驶汽车所需的数据量十分巨大。RAND公司的专家预估,汽车需要拥有110亿英里的行驶经验才能比人类操作好20%。这意味着在现实世界中,我们需要一个共有100辆车的车队不间断驾驶500多年才能获得相应的驾驶经验。
而且,不是任何驾驶数据都是有效的。有效的训练数据必须包含各种挑战性的驾驶情况,以确保汽车能够安全行驶。
如果为了找到这些驾驶场景而要给这些检验数据添加注释,在100辆车一天驾驶8个小时的情况下,则需要超过100万个人员为来自车上所有摄像头的数据打标签,这将是一项巨大的工作。除了人工成本外,在此数据上训练DNN所需的计算和存储资源也是不切实际的。
数据注释和管理的结合对自动驾驶汽车的开发带来了重大挑战。通常在此过程中,我们会应用AI来减少训练的时间和成本,同时还可以提高网络的准确性。
为什么是主动学习
选择自动驾驶DNN训练数据有常见的三种方法。随机抽样以均匀的间隔从数据池中提取帧,能够捕获最常见的场景,但也可能会遗漏不常见的模式。
基于元数据的抽样使用基本标签(例如,雨水、夜晚)来选择数据,从而很容易找到常见的困难情况,但是却丢失了不容易分类的独特的帧,例如拖拉机拖车或踩着高跷的人穿过马路。
注释:并非所有数据都是公平创建的。常见公路场景的示例(左上)与一些不寻常的驾驶场景(右上:骑自行车的人在夜间玩自行车,左下:卡车拖挂拖车,右下:行人踩高跷)。
最后,手动管理将元数据
标签与人工注释者的可视化浏览结合使用,这是一个耗时的工作,容易出错且难以扩展。
通过主动学习,可以在选择有价值的数据点时自动执行筛选过程。首先,训练一个针对已标记数据的专用DNN。然后,网络会对未标记的数据进行分类,筛选无法识别的帧,从而找到对自动驾驶汽车算法具有挑战性的数据。
然后,这些数据将由人工注释者进行审查和标记,并添加到训练数据库中。
主动学习已经表明,与手动管理相比,它可以提高自动驾驶DNN的检测准确性。在我们自己的研究中,NVIDIA团队发现与手动选择的数据相比,使用主动学习数据进行训练时,行人检测的精度提高了3倍,自行车检测的精度提高了4.4倍。
在可靠且可扩展的AI基础架构上运行时,像主动学习、迁移学习和联邦学习这样的高级训练方法最有效。通过这些方式可以实现并行管理大量数据,从而缩短了开发周期。
NVIDIA将为开发人员开放这些训练工具以及NVIDIA GPU Cloud容器注册表上丰富的自动驾驶深度神经网络库。
订阅英伟达 NVIDIA 技术月刊


