NVIDIA 网络开创高频交易百 G 网络新纪元
2023-01-11 19:24
 分享到微信
分享到微信
 分享到微博
分享到微博
本文介绍了 NVIDIA 网络在高频交易领域内的产品与解决方案,我们通过高带宽的网络为该领域的客户提供了一揽子的端到端解决方案,覆盖了 Ethernet 和 InfiniBand 网络,在 TCP/RDMA 传输机制中均可以提供极具竞争力的网络产品,成为高品交易领域中不可或缺的网络解决方案。
在最近几年,分布式系统成为金融交易领域里得到广泛的应用,随着高频 CPU/Cache 和大容量高性能 DDR 技术的引入,交易系统的全链路延迟已经进入微秒度量的时代。而网络时延成为了整个交易系统的链路瓶颈,越来越多的优化方法转向到网络上来,希望对网络硬件的升级和协议栈的优化进一步降低网络上数据传输的时延。
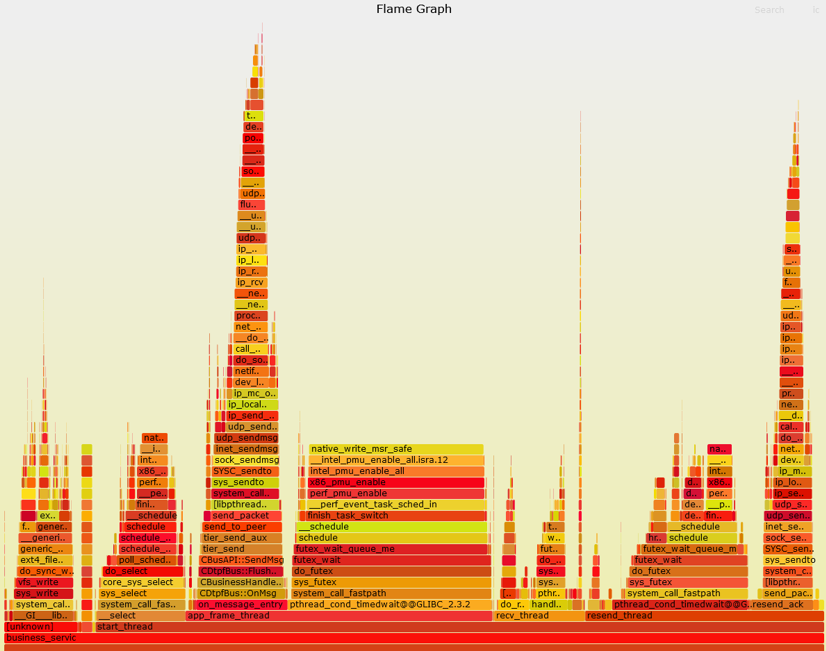
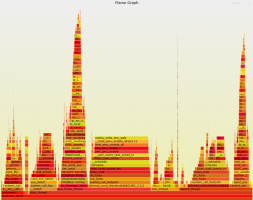
图 1:某一核心应用的性能火焰图
NVIDIA 网络网络凭借多年高端网络产品的开发经验,拥有业界最高带宽及极低网络时延的产品组合,在高频交易领域越来越注重网络性能的背景下,向客户提供一系列极具竞争性的解决方案,不断挑战低延时交易领域的时延记录。
首先,让我们从物理层面分析服务器之间通信的机制,不难发现高带宽是降低网网络时延的关键。
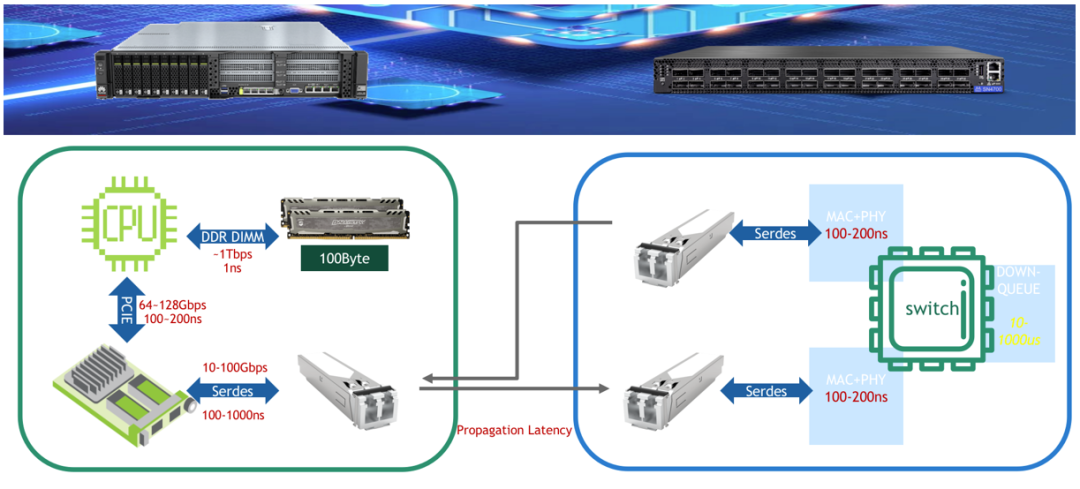
图 2:网络通信物理时延分布
网络时延主要分布在服务器和交换机两类节点上。在服务器上,数据要以整包的形式经过内存到 CPU,CPU 到网卡,网卡发送至交换机的三个过程。在整包传输的机制下,时延正比报文长度,反比与传输带宽,因此我们不难发现,以 100 字节为例,相比传统的万兆网卡,采用百 G 网卡的好处十分明显,CPU 至网卡阶段,由于百 G 网卡 PCIe 带宽是万兆的两倍,因此理论上会节省 100-200ns 的时延,而网卡至交换机阶段,百 G 网卡是万兆网卡时延的十分之一,节省将近 1 个 us 的时延;对于交换机,由于采用的是 Cut-Through 机制,因此在非拥塞的情况下,时延和报文长度没有关系,但是在拥塞的情况下,由于报文都会转为整包存储在交换机的下行队列缓存中,所以,排空报文的时间又正比于队列长度,反比端口转发速率,因此端口速率仍然是降低转发时延的关键。
由于在网卡端,实际情况要结合协议栈处理,所以,影响时延的因素会非常复杂,真实时延变化会和理论推导有比较大的差值,但是速率影响转发时延的结论不会改变。在相同类型网卡测试下,带宽越大的时延,就会越低。图 3 中就可以直观的看到,同样在 ConnectX-6 芯片下的 10G/25G/100G 芯片的 pingpong 测试中,任何字节报文的时延均是呈现网卡速率越大,时延越低这一趋势。
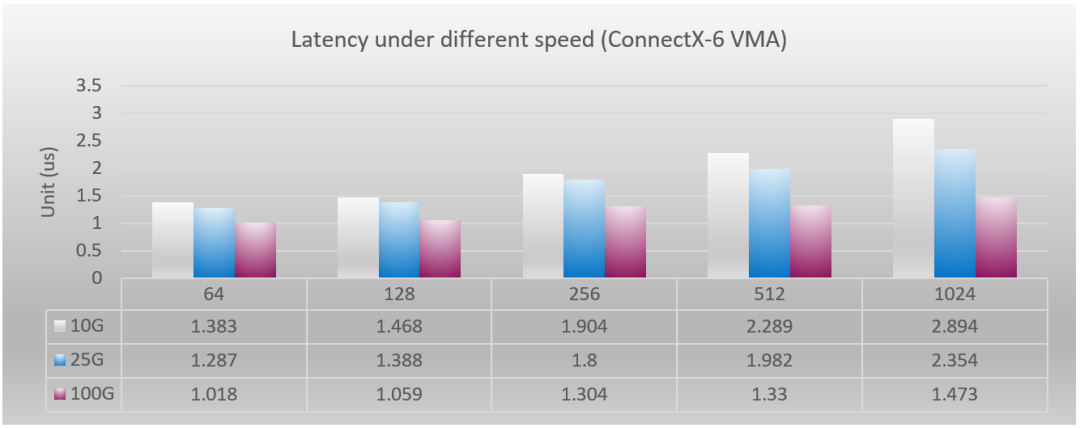
图 3:ConnectX-6 不同速率网卡的 VMA 下单向转发时延
以上仅是裸时延测试,时延数据仅是单个报文的的情况,而真实的交易情况却远比以上测试情况复杂,往往在某一时刻会产生大量的交易报文,由于 CPU 到内存的链路带宽非常高,这样报文会非常快的积累在内存中等待转发,而此时所有报文的转发时间应该等于所有报文长度之和除以端口速率,因此不难想象,万兆网络的排空时间会大幅低于百 G 网络的时延,有时这里的差距可能会高达百 us 级。在交换机上时延对速率的依赖会更加明显,由于目前,大多数交易系统采用 HA 架构,每一比交易均会在并行的两路服务器上转发,这样的架构会造成交换机转发过程中,下行端口会时刻接受上行两个端口的报文,势必会造成队列积累。而此时时延将会仅与端口速率相关。可以看出采用百 G 网络系统在这种情况下会有毫秒级的时延受益。
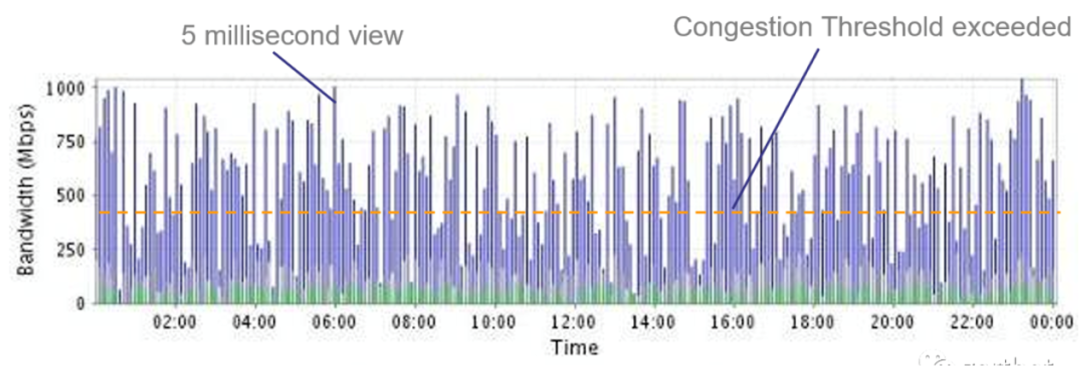
图 4:真实交易网络中的微突发导致的毫秒级时延震荡
所以,通过以上分析,可以看出,高带宽的百 G 网络才是降低时延的制胜法宝。
上面我们从物理底层角度阐明了时延与带宽的关系,但这并不是说只要采用了高速网络就可以大幅的降低通信时延了,因为,时延产生的机制错综复杂,速率是主要方向,但不是全部。对于普通情况下(不包括大量交易情况下),高低网络在单跳的时延差异不足微秒,而网络协议栈的处理在采用硬件加速和不采用硬件加速的情况下会有十微秒的差异,因此还需要配合更多的技术才能完美的发挥出大带宽网络的时延优势。
NVIDIA 网络在网络加速方面有 VMA,RoCE 和 InfiniBand 技术/产品供不同客户选择,构建出极具竞争力的解决方案。
VMA(消息加速器)

图 5:VMA 架构图
是一套运行在用户态的 lib 库,可以支持 TCP/UDP 的报文加速,实现对内核的旁路,直接调用网卡驱动,从而节省了大量的上下文数据拷贝,节省了 CPU 的资源降低了时延,实际测试中,结合 100G 网络速率应用最低时延可以达到不到 1.1us,相比 kernel 模式,节省了 80% 的时延。并且这一技术可以简单有效的实现对 sock 开发程序的对兼容,对上层应用透明, 无需开发就可以使用,而且支持单边应用,不需要对端配合。是一种便捷的降低通信时延的方式。
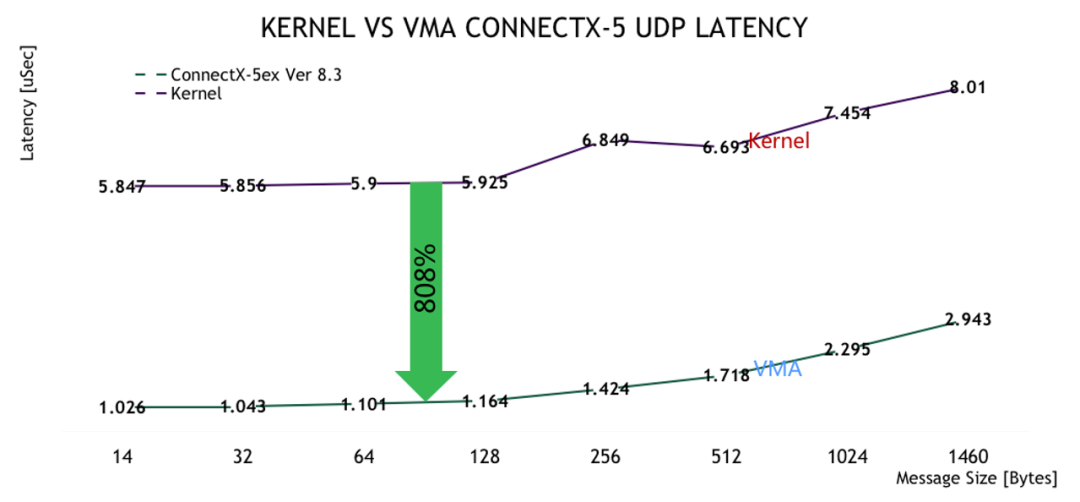
图 6:VMA 与 Kernel 多播 UDP 时延对比
RoCE(RDMA over Converged Ethernet)
在数据中信领域,远程内存访问技术 RDMA(Remote Direct Memory Access)是一种绕过远程主机操作系统内核访问其内存中数据的技术,可以直接旁路 CPU,大幅释放 CPU 的资源,提高网络通信的带宽,降低通信时延。相比与 VMA 技术,由于数据面通信不仅不需要 Kernel 介入,而且也不需要用户态的介入,所以,低时延会更有优势,时延会低至 800ns,只是需要对端共同配置 RDMA,因此应用范畴仅限在局域网内部。
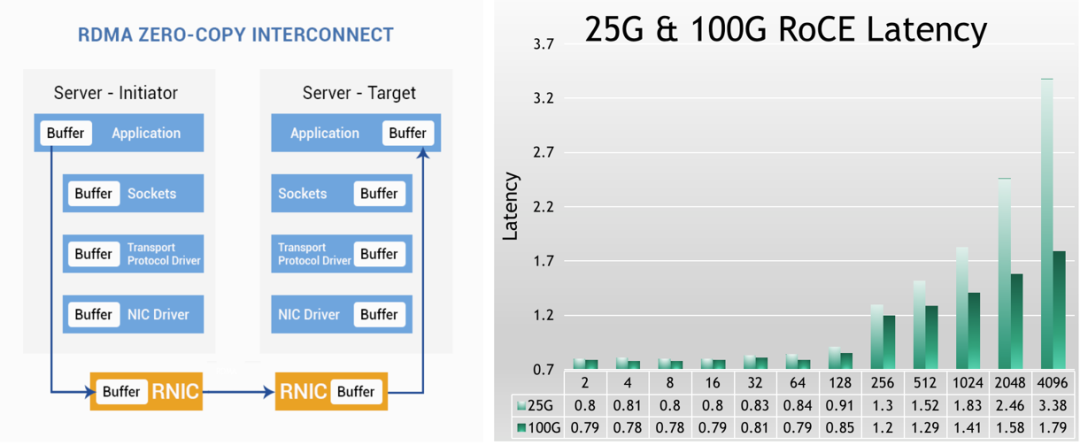
图 7:NVIDIA RoCE 网卡时延
NVIDIA 网络不仅在网卡端提供极具竞争力的产品,在交换机侧也有 Spectrum 产品,实现端到端的产品布局。众所周知,大部分交换机生产厂家使用 BroadCom 的芯片生产交换机,NVIDIA 网络则是使用自研的芯片,这一不同使得 NVIDIA 交换机可以在支持 RoCE 的情况下具有与众不同的低时延优势。
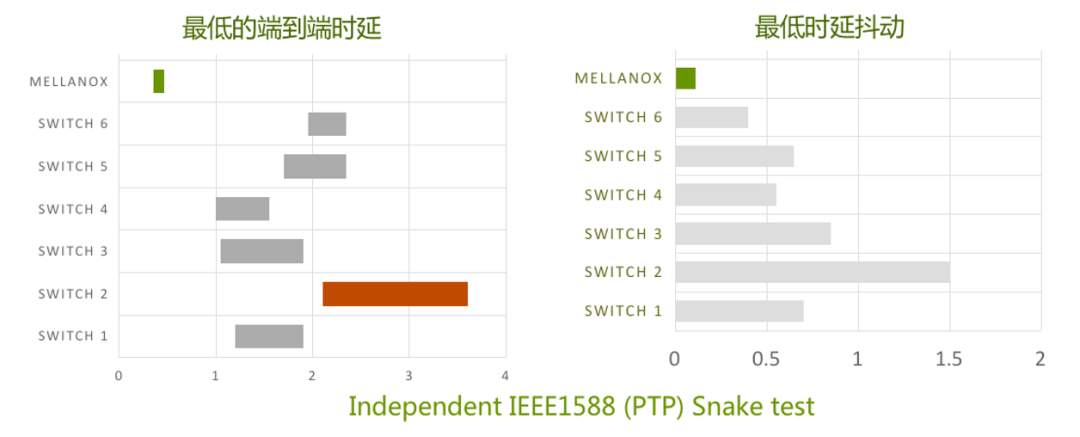
图 8:Spectrum 交换机时延与时延抖动对比
搭配 NVIDIA 的网卡与交换机可以构建出端到端最具时延优势的以太网络解决方案。
InfiniBand
InfiniBand 是 NVIDIA 网络针对高性能计算领域开发的高性能网络产品,具备无损网络的同时,拥有业界最低的网络转发时延。网卡端时延可以低至 600ns,交换机侧时延可以低至 100ns 量级,而且是原生的 RDMA 通信技术,使得在 InfiniBand 网络上构建无与伦比的低时延网络。
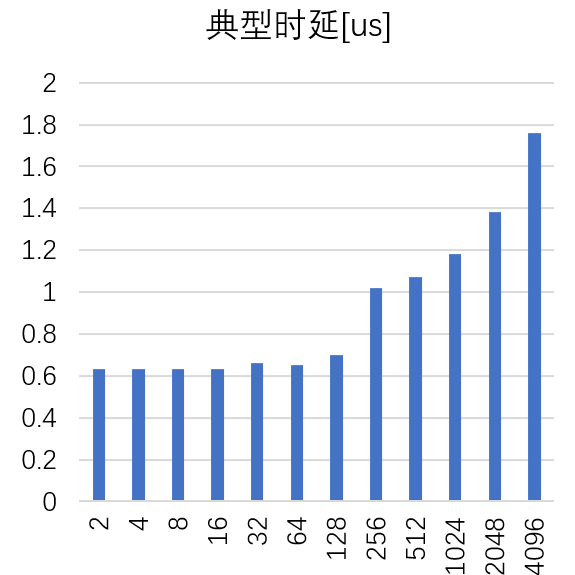
图 9:IB-HDR 网卡时延
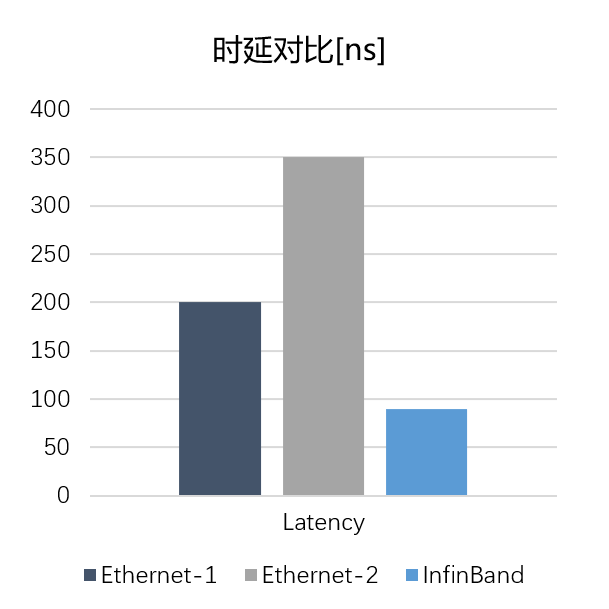
图 10:IB 交换机与万兆以太网低时延交换机时延对比
从上面的数据中可以看出,InfiniBand 网络拥有业界最低的网络时延,在局域网内部可以通过使用 InfiniBand 网络架构搭建出满足低时延要求的解决方案。而且由于 InfiniBand 是天生的无损网络,不用担心由于突发造成的偶然丢包情况的发生。这一特性也可以保证使用 IB 的集群具备更高的可靠性。
由于 InfiniBand 网络与 Ethernet 网络不兼容,因此在网络架构设计上需要做特殊的设计,我们推荐客户采用如下网络结构,在券商网络边缘节点上部署不同网络类型的 NVIDIA 网卡,对外连接(交易所侧,客户侧)使用以太网络,部署 VMA 使其可以最大化兼容各种网络设备,服务器内网侧使用 InfiniBand 网卡通过 InfiniBand 交换机连接,保证内部可以拥有最低的网络时延,这样的架构设计可以做到零时延代价部署 InfiniBand 网络到券商环境中,从而具备端到端最低网络时延。
金仕达 DTP 低延迟网络解决方案
金仕达是国内优秀的金融方案提供上,在证券、期货、银行黄金、机构资管等多个行业领域落地分布式交易架构产品,经过对该行业需求的深入分析,对比了业界各种产品技术指标与方案,最终选择了 NVIDIA 网络产品作为分布式交易产品的网络解决方案,为高频交易客户提供优秀的产品服务。
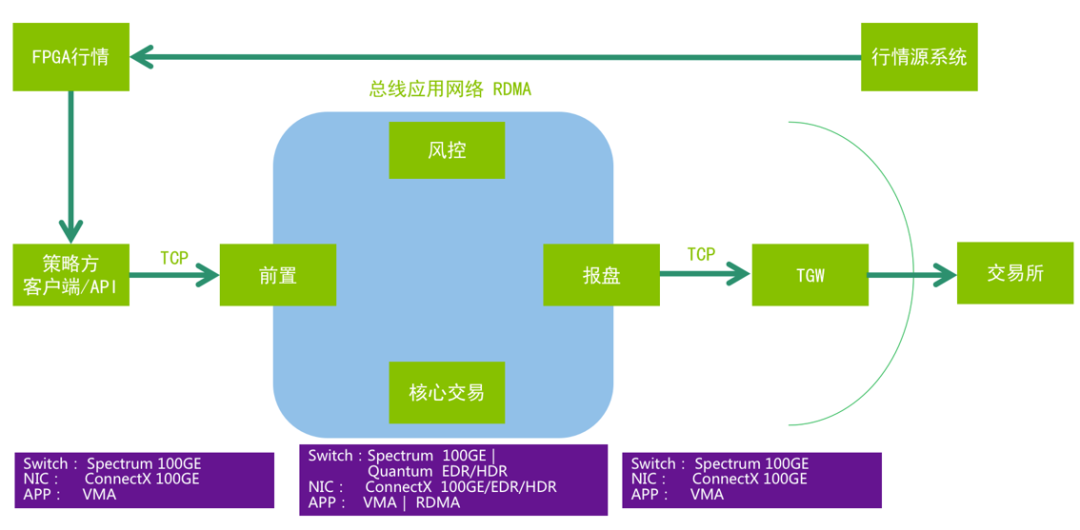
图 11:金仕达端到端网络模块布局方案
金仕达 DTP 关于网络技术方面的方案要素包括:
在交易平台的总线应用网络中消息容错总线从基于 UDP 组播方式调整为基于 RDMA 方式,全面大幅度优化网络吞吐量和低延迟消息,其效果将内部穿透延迟推进到个位数微秒级别;
在策略方 API 和交易前置间采用 RDMA 方式替代原先的 TCP 通讯模式;
在报盘和 TGW 间,采用 VMA 方式以优化仅为 TCP 模式的限制性应用网络环境;
金仕达交易系统负责人夏之春表示:“NVIDIA 的产品在低延时领域具有非常出众的表现,不仅可以满足内网的超低时延转发,而且也可以对外网 TCP 的通信具有非常好的低时延加速,为金仕达的产品提供了出色的网络通信基础。”











