NVIDIA Triton 系列文章(11):模型类别与调度器-1
2023-01-11 19:24
 分享到微信
分享到微信
 分享到微博
分享到微博
在 Triton 推理服务器的使用中,模型(model)类别与调度器(scheduler)、批量处理器(batcher)类型的搭配,是整个管理机制中最重要的环节,三者之间根据实际计算资源与使用场景的要求去进行调配,这是整个 Triton 服务器中比较复杂的部分。
在模型类别中有“无状态(stateless)”、“有状态(stateful)”与“集成(ensemble)”三种,调度器方面则有“标准调度器(default scheduler)”与“集成调度器(ensemble scheduler)”两种,而标准调度器下面还有“动态批量处理器(dynamic batcher)”与“序列批量处理器(sequence batcher)”两种批量处理器。
模型类别与调度器/批量处理器之间存在一些关联性,以下整理出一个简单的配合表格,提供大家参考:
类别
调度器
批量处理器
使用场景
无状态
标准调度器
动态批量处理器
面向各自独立的推理模型
有状态
标准调度器
序列批量处理器
处理存在交互关系的推理模型组
集成
集成调度器
创建复杂的工作流水线
接下去就要为这几个管理机制的组合进行说明,由于内容较多并且不均衡,特别是“有状态模型”与“集成模型”两部分的使用是相对复杂的,因此这些组合会分为三篇文章来进行较为深入的说明。
1. 无状态(Stateless)模式:
这是 Triton 默认的模型模式,最主要的要求就是“模型所维护的状态不跨越推理请求”,也就是不存在与其他推理请求有任何交互关系,大部分处于最末端的独立推理模型,都适合使用这种模式,例如车牌检测最末端的将图像识别成符号的推理、为车辆识别颜色/种类/厂牌的图像分类等,还有 RNN 以及具有内部内存的类似模型,也可以是无状态的。
2. 有状态(Stateful)模式:
很多提供云服务的系统,需要具备同时接受多个推理请求去形成一系列推理的能力,这些推理必须路由到某些特定模型实例中,以便正确更新模型维护的状态。此外,该模型可能要求推理服务器提供控制信号,例如指示序列的开始和结束。
Triton 服务器提供动态(dynamic)与序列(sequence)两种批量处理器(batcher),其中序列批量处理器必须用于这种有状态模式,因为序列中的所有推理请求都被路由到同一个模型实例,以便模型能够正确地维护状态。
序列批量处理程序还需要与模型相互传递信息,以指示序列的开始、结束、具有可执行推理请求的时间,以及序列的关联编号(ID)。当对有状态模型进行推理请求时,客户端应用程序必须为序列中的所有请求提供相同的关联编号,并且还必须标记序列的开始和结束。
下面是这种模式的控制行为有“控制输入”、“隐式状态管理”与“调度策略”三个部分,本文后面先说明控制输入的内容,另外两个部分在下篇文章内讲解。
(1) 控制输入(control inputs)
为了使有状态模型能够与序列批处理程序一起正确运行,模型通常必须接受 Triton 用于与模型通信的一个或多个控制输入张量。
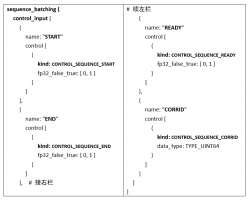
模型配置的 sequence_batching 里的 control_input 部分,指示模型如何公开序列批处理程序应用于这些控件的张量。所有控件都是可选的,下面是模型配置的一部分,显示了所有可用控制信号的示例配置:

开始(start):
这个输入张量在配置中使用“CONTROL_SEQUENCE_START”指定,上面配置表明模型有一个名为“START”的输入张量,其数据类型为 32 位浮点数,序列批量处理程序将在对模型执行推理时定义此张量。
START 输入张量必须是一维的,大小等于批量大小,张量中的每个元素指示相应批槽中的序列是否开始。上面配置中“fp32_false_true”表示,当张量元素等于 0 时为“false(不开始)”、等于 1 时为“ture(开始)”。
结束(End):
结束输入张量在配置中使用“CONTROL_SEQUENCE_END”指定,上面配置表明模型有一个名为“END”的输入张量,具有 32 位浮点数据类型,序列批处理程序将在对模型执行推理时定义此张量。
END 输入张量必须是一维的,大小等于批量大小,张量中的每个元素指示相应批槽中的序列是否开始。上面配置中“fp32_false_true”表示,当张量元素等于 0 时为“false(不结束)”、等于 1 时为“ture(结束)”。
准备就绪(Ready):
就绪输入张量在配置中使用“CONTROL_SEQUENCE_READY”指定,上面配置表明模型有一个名为“READY”的输入张量,其数据类型为 32 位浮点数,序列批处理程序将在对模型执行推理时定义此张量。
READY 输入张量必须是一维的,大小等于批量大小,张量中的每个元素指示相应批槽中的序列是否开始。上面配置中“fp32_false_true”表示,当张量元素等于 0 时为“false(未就绪)”、等于1时为“ture(就绪)”。
关联编号(Correlation ID):
关联编号输入张量在配置中使用“CONTROL_SEQUENCE_CORRID”指定,上面置表明模型有一个名为“CORRID”的输入张量,其数据类型为无符号 64 位整数,序列批处理程序将在对模型执行推理时定义此张量。
CORRID 张量必须是一维的,大小等于批量大小,张量中的每个元素表示相应批槽中序列的相关编号。
(2) 隐式状态管理(implicit State Management)
这种方式允许有状态模型将其状态存储在 Triton 服务器中。当使用隐式状态时,有状态模型不需要在模型内部存储推理所需的状态。不过隐式状态管理需要后端(backend)支持。目前只有 onnxruntime_backend 和 tensorrt_backend 支持隐式状态。
下面是模型配置的一部分,在 sequence_batching 配置中的 state 部分,就是用于指示该模型正在使用隐式状态:
这里做简单的说明:
字段说明:
执行要点:
默认情况下,序列中的启动请求包含输入状态的未初始化数据。模型可以使用请求中的开始标志来检测新序列的开始,并通过在模型输出中提供初始状态来初始化模型状态,如果模型状态描述中的 dims 部分包含可变尺度,则 Triton 在开始请求时将每个可变尺寸设置为“1”。对于序列中的其他非启动请求,输入状态是序列中前一个请求的输出状态。
对于状态初的初始化部分,有以下两种状况需要调整:
启动请求时:则模型将“OUTPUT_STATE”设置为等于“INPUT”张量;
非启动请求时:将“OUTPUT_STATE”设为“INPUT”和“INPUT_STATE”张量之和。
除了上面讨论的默认状态初始化之外,Triton 还提供了“从 0 开始”与“从文件导入”两种初始化状态的机制。下面提供两种初始化的配置示例:

两个配置只有粗体部分不一样,其余内容都是相同的,提供读者做个参考。
以上是关于有状态模型的“控制输入”与“隐式状态管理”的使用方式,剩下的“调度策略”部分,会在后文中提供完整的说明。











