
NVIDIA Triton 系列文章(9):为服务器添加模型
2022-12-29 13:44
 分享到微信
分享到微信
 分享到微博
分享到微博
前面已经用 https://github.com/triton-inference-server/server/doc/examples 开源仓的范例资源,创建一个最基础的模型仓以便执行一些基础的用户端范例,现在就要带着读者为模型仓添加新的模型。
在“创建模型仓”的文章里讲解过,Triton 模型仓使用目录结构与相关文件来形成一个模型的基础要素,如下所列:
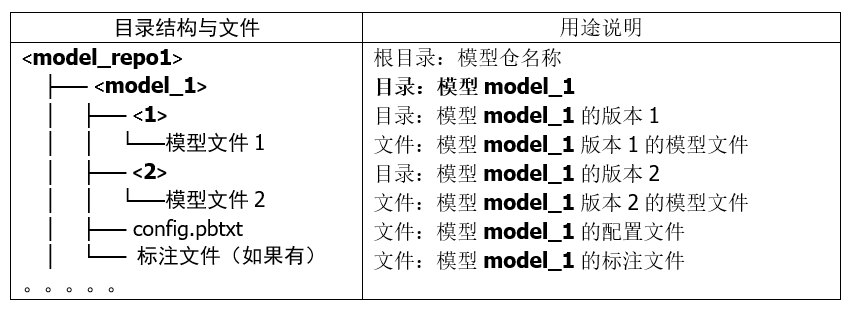
上面的目录结构与模型文件是最基本的材料,处理起来是很容易的,比较复杂的部分是配置文件 config.pbtxt 的内容,里面提供 Triton 服务器用来管理模型执行特性的各项参数,这些设置的内容主要分为静态的基础(minimal)设置项与动态的优化(optimization)设置两大部分,本文内容先针对基础配置项的部分进行说明。
为了说明这些配置内容,这里先以范例模型仓里的 inception_graphdef 模型的配置文件 config.pbtxt 为例,来配合以下的简单说明,比较容易让大家理解详细的内容:

每个配置文件里都至少包含以下5个部分:
1. 模型名称:
这部分直接使用存放模型的文件夹名称,因此可以省略,如果要指定的话就必须与文件夹名称一致。
2. 平台/后端名称(Name, Platform and Backend):
这部分必须与模型训练时使用的框架与文件格式相匹配,以下是使用频率较高的种类:
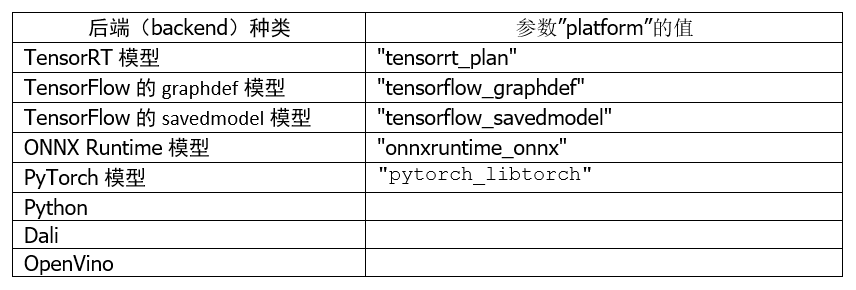
至于其他平台/后端的对应名称,就需要根据实际的平台与对应名称进行配置。
3. 模型执行策略(Model Transaction Policy):
这个属性只有一个“解耦(decoupled)与否”的选项。使用解耦意味着模型生成的响应的数量可能与发出的请求的数量不同,并且响应可能与请求的顺序无关。
默认值为 false,上面范例中并未列出这个参数的配置值,表示“不启用解耦”功能,意味着该模型将为每个请求生成一个响应。
如果需要启用解耦功能,就在配置文件内添加以下内容:
4. 最大批量值(Maximum Batch Size):
Triton 服务器支持多种调度和批处理算法,可以为每个模型独立选择。这个属性表示执行该推理模型计算时的最大批量规模,包括“无状态(stateless)”或“有状态(stateful)”等类型的模型。
这个参数主要配合下面“输入/输出节点内容”的张量尺度部分,例如本范例中输入节点张量格式为“format: FORMAT_NHWC”,但是下面尺度“dims: [ 299, 299, 3 ]”的三个数值是对应到“HWC(高/宽/通道)”,缺少“批量值(N)”的部分,这正是这个“最大批量值”为输入节点与输出节点所配置的数值,这样 Triton 可以使用动态批处理器或序列批处理器自动对模型进行批处理。
在这种情况下,max_batch_size 应设置为大于或等于1的值,表示应与该模型一起使用的最大批次大小;对于不支持批处理或不支持以上述特定方式进行批处理的推理模型,则将 max_batch_size 设置为 0。
5. 输入节点与输出节点(Inputs and Outputs):
每个推理模型都有至少一个输入节点与输出节点,这部分的内容必须配合模型的内容,不能自己随便定义。
要添加新的推理模型时,推荐使用 Netron 工具查看模型的网络结构,只要在浏览器上输入“netron.app”后打开模型文件就可以。目前经过测试,Netron.APP 工具能查看 ONNX、TensorFlow/graphdef、Pytorch 等模型文件的网络结构,相当方便。
下图是 model_repository/inception_graphdef/1/model.graphdef 模型文件所能看到的输入/输出节点的内容:
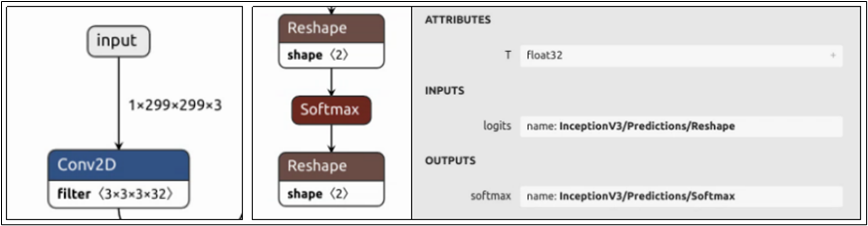
每个节点都包含“名称”、“数据类型”与“尺度(shape)”三个部分,现在就进一步说明:
(1) 节点名称(name):
上图最左边的输入节点在整个网络结构的最上方,名称为“input”;中间输出节点在网络结构最下方,点选“softmax”节点会出现右边灰色信息块,显示其完整名称为“InceptionV3/Predictions/Softmax”。现在对照模型的 config.pbtxt 里对应内容,是必须能匹配的,否则启动 Triton 服务器时会出现错误。
不过这个环节里对 PyTorch 模型需要特殊的处理,由于 TorchScript 模型文件中输入/输出的元数据不足,配置中输入/输出的“名称属性”必须遵循以下特定的命名约定:
使用张量字典(Dictionary of Tensor):
映射到 forward() 函数的输入值:
使用_格式:
如果所有输入(或输出)不遵循相同的命名约定,那么我们从模型配置中强制执行严格排序,即我们假设配置中输入(或输出)的顺序是这些输入的真实顺序。
(2) 数据类型(data_type):
输入和输出张量所允许的数据类型因模型类型而异,数据类型部分描述了允许的数据类型以及它们如何映射到每个模型类型的数据类型。
下表显示了 Triton 支持的张量数据类型:
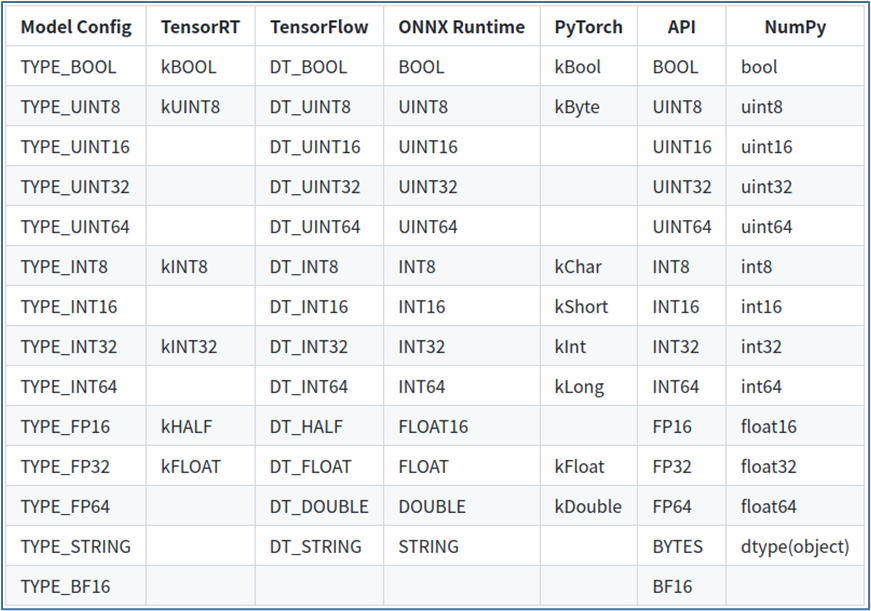
第 1 列显示模型配置文件中显示的数据类型的名称;
第 2~5 列显示了支持的模型框架的相应数据类型,如果模型框架没有给定数据类型的条目,则 Triton 不支持该模型的数据类型;
第 6 列为“API”,显示 TRITONSERVER C API、TRITONBACKEND C API、HTTP/REST 协议和 GRPC 协议的对应数据类型;
第 7 列显示 Python numpy 库的对应数据类型。
以上是关于模型数据类型的部分。
(3) 张量尺度(dims):
这里提供的张量尺度内容是去除第一个 batch_size 的部分,因此需要与前面设定的 max_batch_size 组合形成完整的张量尺度。
输入节点的张量尺度(如“dims: [ 299, 299, 3 ]”),表示模型和 Triton 在推理请求中预期的张量尺寸;输出节点的张量尺度(如“dims: [ 1001 ]”),表示模型生成的输出张量的形状,并由 Triton 服务器响应推断请求返回。
输入和输出尺度内的值都必须大于或等于 1,也就是不允许使用[]空尺度,节点的尺度由 max_batch_size 和输入或输出 dims 属性指定的维度的组合指定。
max_batch_size > 0时:整个尺度的形式为[-1, dims]。
max_batch_size = 0时:整个形状形成为[ dims]。
例如本文范例中输入节点的尺度为“dims: [ 299, 299, 3 ]”、max_batch_size=128,则张量尺度的完整表达为“[ -1, 299, 299, 3]”;如果 max_batch_size=0 时,则张量尺度的完整表达为“[ 299, 299, 3]”。
6. 版本策略(version_policy):
每个模型可以有一个或多个版本,模型配置的 ModelVersionPolicy 属性用于设置以下策略之一。
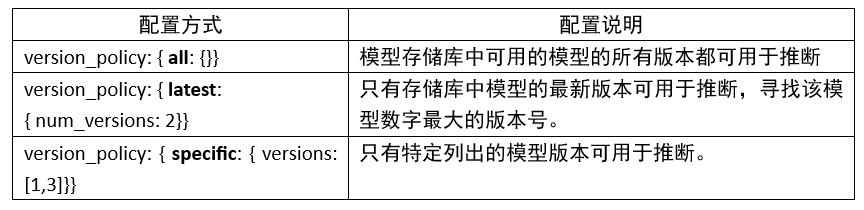
如果未指定版本策略,则使用最新版本(n=1)作为默认值,表示 Triton 仅提供最新版本的模型。在所有情况下,从模型存储库中添加或删除版本子目录都可以更改后续推理请求中使用的模型版本。
以上是完成一个 config.pbtxt 模型配置文件的最基础内容,大部分内容都比较直观,除了最后面的张量尺度会有比较多的变化之外,不过只要逐渐熟悉推理运作的过程之后,就能更进一步掌握与 batch_size 相关的应用与调试方式。











