NVIDIA Triton 系列文章(8):用户端其他特性
2022-12-26 13:44
 分享到微信
分享到微信
 分享到微博
分享到微博
前面文章用 Triton 开源项目提供的 image_client.py 用户端作示范,在这个范例代码里调用大部分 Triton 用户端函数,并使用多种参数来配置执行的功能,本文内容就是简单剖析 image_client.py 的代码,为读者提供撰写 Triton 用户端的流程。
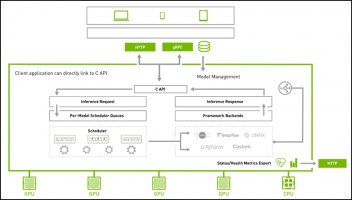
指定通信协议
为了满足大部分网路环境的用户端请求,Triton 在服务器与用户端之间提供 HTTP 与 gRPC 两种通信协议,如下架构图所示:

当我们启动 Triton 服务器之后,最后状态会停留在如下截屏的地方:

显示的信息表示,系统提供 8001 端口给 gRPC 协议使用、提供 8000 端口给 HTTP 协议使用。此时服务器处于接收用户端请求的状态,因此“指定通信协议”是执行 Triton 用户端的第一个工作。
这个范例支持两种通信协议,一开始先导入 tritonclient.http 与 tritonclient.grpc 两个模块,如下:
代码使用“-i”或“--protocal”其中一种参数指定“HTTP”或“gRPC”协议类型,如果不指定就使用“HTTP”预设值。再根据协议种类调用 httpcclient.InferenceServerClient() 或 grpcclient.InferenceServerClient() 函数创建 triton_client 对象,如下所示:
最后启用 triton_client.infer() 函数对 Triton 服务器发出推理要求,当然得将所需要的参数提供给这个函数,如下所示:
不过 image_client.py 代码中并未设定 gRPC 所需要的 8001 端口,因此使用这个通讯协议时,需要用“-u”参数设定“IP:端口”,例如下面指令:
在 examples 范例目录下还有 20 个基于 gRPC 协议的范例以及 10 个基于 HTTP 协议的范例,则是在代码内直接指定个别通信协议与端口号的范例,读者可以根据需求去修改特定的范例代码。
调用异步模式(async mode)与数据流(streaming)
大部分读者比较熟悉的并行计算模式,就是在同一个时钟脉冲(clock puls)让不同计算核执行相同的工作,也就是所谓的 SIMD(单指令多数据)并行计算,通常适用于数据量大而且持续的密集型计算任务。
对 Triton 推理服务器而言,并不能确认所收到的推理要求是否为密集型的计算。事实上很大比例的推理要求是属于零碎型计算,这种状况下调用“异步模式”会让系统更加有效率,因为它允许不同计算核(线程)在同一个时钟脉冲段里执行不同指令,这样能大大提高执行弹性进而优化计算性能。
当 Triton 服务器端启动之后,就能接收来自用户端的“异步模式”请求,不过在 HTTP 协议与 gRPC 协议的处理方式不太一样。
在代码中用 httpclient.InferenceServerClient() 函数创建 HTTP 的 triton_client 对象时,需要给定“concurrnecy(并发数量)”参数,而创建 gRPC 的用户端时就不需要这个参数。
调用异步模式有时会需要搭配数据流(stream)的处理器(handle),因此在实际推理的函数就有 triton_client.async_infer() 与 triton_client.async_stream_infer() 两种,使用 gRPC 协议创建的 triton_client,在调用无 stream 模式的 async_infer() 函数进行推理时,需要提供 partial(completion_callback, user_data) 参数。
由于异步处理与数据流处理有比较多底层线程管理的细节,初学者只需要范例目录下的代码,包括 image_client.py 与两个 simple_xxxx_async_infer_client.py 的代码就可以,细节部分还是等未来更熟悉系统之后再进行深入。
使用共享内存(share memory)
如果发起推理请求的 Triton 用户端与 Triton 服务器在同一台机器时,就可以使用共享内存的功能,这包含一般系统内存与 CUDA 显存两种,这项功能可以非常高效地降低数据传输的开销,对提升推理性能有明显的效果。
在 image_client.py 范例中并未提供这项功能,在 Python 范例下有 6 个带有“shm”文件名的代码,就是支持共享内存调用的范例,其中 simple_http_shm_client.py 与 simple_grpc_shm_client.py 为不同通信协议提供了使用共享系统内存的代码,下面以 simple_grpc_shm_client.py 内容为例,简单说明一下主要执行步骤:
至于范例中有两个 simple_xxxx_cudashm_client.py 这是针对 CUDA 显存共享的返利代码,主要逻辑与上面的代码相似,主要将上面“shm.”开头的函数改成“cudashm.”开头的函数,当然处理流程也更加复杂一些,需要有足够 CUDA 编程基础才有能力驾驭,因此初学者只要大致了解流程就行。
以上就是 Triton 用户端会用到的基本功能,不过缺乏足够的说明文件,因此其他功能函数的内容必须自行在开源文件内寻找,像 C++ 版本的功能得在 src/c++/library 目录下的 common.h、grpc_client.h 与 http_client.h 里找到细节,Python 版本的函数分别在 src/python/library/triton_client 下的 grpc、http、utils 下的 __init__.py 代码内,获取功能与函数定义的细节。











