
NVIDIA Triton 系列文章(5):安装服务器软件
2022-11-29 12:22
 分享到微信
分享到微信
 分享到微博
分享到微博
在前一篇文章已经带着读者创建一个 Triton 的推理模型仓,现在只要安装好服务器端与用户端软件,就能进行基本的测试与体验。
为了简化过程,我们使用 NVIDIA Jetson AGX Orin 设备进行示范,所有步骤都能适用于各种基于 NVIDIA Jetson 智能芯片的边缘设备上,也适用于大部分装载 Ubuntu 18 以上操作系统的 x86 设备上,即便设备上没有安装 NVIDIA 的 GPU 计算卡也能使用,只不过我们的提供的内容都是基于 GPU 计算环境,对于纯 CPU 的使用则需要用户自行研读说明文件。
现在就开始安装 Triton 服务器软件,NVIDIA 为 Triton 服务器提供以下三种软件安装的方式:
1. 源代码编译
这种方式需要从https://github.com/triton-inference-server/server下载源代码,然后安装依赖库,再用 cmake 与 make 工具进行编译。通常会遇到的麻烦是步骤繁琐,并且出错率较高,因此并不推荐使用这个方法。
有兴趣者,请自行参考前面下载的开源仓里的 docs/customization_guide/build.md文件,有关于 Ubuntu 20.04、Jetpack 与 Windows 等各种平台的编译细节。
2. 可执行文件
Triton 开发团队为使用者提供编译好的可执行文件,包括 Ubuntu 20.04、Jetpack 与 Windows 平台,可以在https://github.com/triton-inference-server/server/releases/ 上获取,每个版本都会提供对应 NGC 容器的版本,如下图:

然后到下面的“Assets”选择合适的版本:
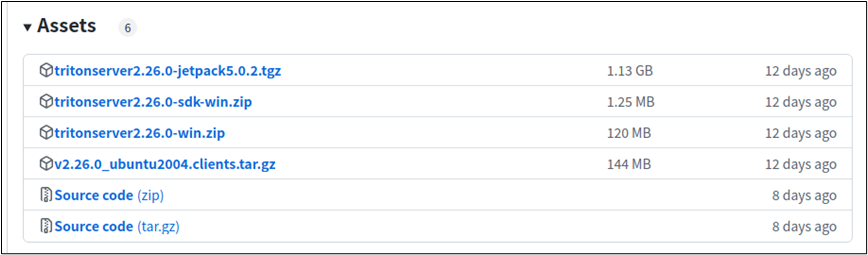
以装载 Jetpack 5 的 Orin 为例,就下载
tritonserver2.26.0-jetpack5.0.2.tgz(1.13GB) 压缩文件到本机上,然后解压缩到指定目录下就可以,例如 ${HOME}/triton 目录,会生成
在执行 Triton 服务器软件前,还得先安装所需要的依赖库,请执行以下指令:
现在就可以执行以下指令启动 Triton 服务器:
如果最后出现以下画面并且进入等待状态:
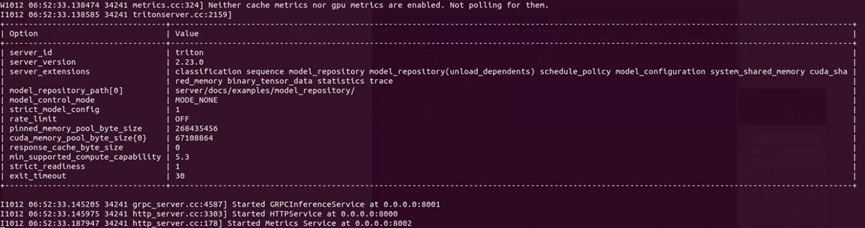
现在 Triton 服务器已经正常运行,进入等待用户端提出请求(request)的状态。
3. Docker容器
在NGC的
https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tritonserver/tags 可以找到 Triton 服务器的 Docker 镜像文件,每个版本主要提供以下几种版本:
year-xy-py3:包含 Triton 推理服务器,支持 Tensorflow、PyTorch、TensorRT、ONNX 和 OpenVINO 模型;
year-xy-py3-sdk:包含 Python 和 C++ 客户端库、客户端示例和模型分析器;
year-xy-tf2-python-py3:仅支持 TensorFlow 2.x 和 python 后端的 Triton 推理服务器;
year-xy-pyt-python-py3:仅支持 PyTorch 和 python 后端的 Triton 服务器;
year-xy-py3-min:用作创建自定义 Triton 服务器容器的基础,如 Customize Triton Container(自定义Triton容器)说明文件所描述的内容;
其中“year”是年份的数字,例如 2022 年提交的就是“22”开头;后面的“xy”是流水号,每次往上加“1”,例如 2022 年 10 月 4 日提交的版本为“22-09”。
NVIDIA 提供的 Triton 容器镜像是同时支持 x86 / AMD64 与 ARM64 架构的系统,以 22.09-py3 镜像为例,可以看到如下图所标示的“2 Architectures”:

点击最右方的“向下”图标,会展开如下图的内容,事实上是有两个不同版本的镜像,不过使用相同镜像名:
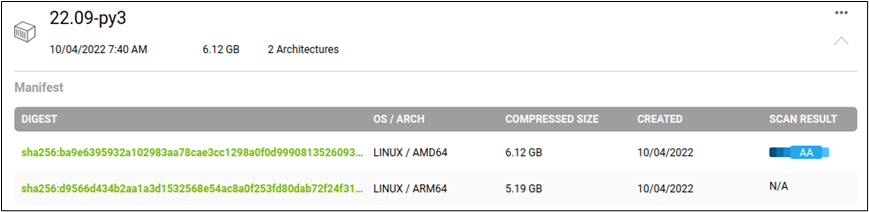
因此在 x86 电脑与 Jetson 设备都使用相同的镜像下载指令,如下:
就能根据所使用设备的 CPU 架构去下载对应的镜像,现在执行以下指令来启动 Triton 服务器:
如果执行正常,也会出现以下的等待画面,表示运行是正确的:
以上三种方式都能在计算设备上启动 Triton 服务器软件,目前看起来使用 Docker 镜像是最为简单的。当服务器软件启动之后,就处于“等待请求”状态,可以使用“Ctrl-C”组合键终止服务器的运行。
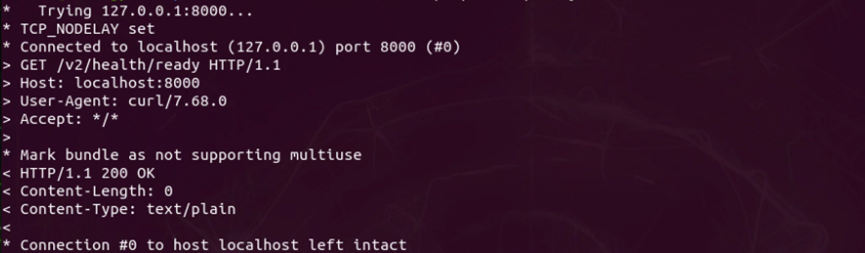
有一种确认 Triton 服务器正常运行的最简单方法,就是用 curl 指令检查 HTTP 端口的状态,请执行以下指令:
如果有显示“HTTP/1.1 200 OK”的信息(如下图),就能确定 Triton 服务器处于正常运行的状态:
接下去就要安装客户端软件,用来对服务器提出推理请求,这样才算完成一个最基础的推理周期。











