Merlin HugeCTR 分级参数服务器系列之三——集成到 TensorFlow
2022-11-29 12:22
 分享到微信
分享到微信
 分享到微博
分享到微博
前两期中我们介绍了 HugeCTR 分级参数服务器 (HPS)的三级存储结构的设计,相关配置使用,数据后端以及流式在线模型更新方案。本期将为大家介绍如何将 HPS 集成到 TensorFlow 中,从而实现在 TensorFlow 中利用分级存储来部署包含庞大 Embedding Tables 的模型。
当需要基于 TensorFlow 来部署包含庞大 Embedding Tables 的深度学习模型时,数据科学家和机器学习工程师需要面对以下挑战:
庞大的 Embedding Tables:训练好的 Embedding Tables 的大小往往达到几百GB,使用 TensorFlow 原生的 Layers 或 Variable 无法放入 GPU 内存;
低延时需求: 在线推理要求 Embedding 查询的延时要足够低(几毫秒级),以保证体验质量和维持用户粘度;
多 GPU 扩展能力:分布式推理框架需要将多个模型部署在多个 GPU上,每个模型包含一个或多个 Embedding Tables;
支持加载为 Pre-trained Embeddings:对于迁移学习等任务,需要支持以 Pre-trained Embeddings 的形式加载庞大的 Embedding Tables。
针对以上挑战,我们为 HPS 提供了一个面向 TensorFlow 的 Python 定制化插件,以方便用户将 HPS 集成到 TensorFlow 模型图中,实现包含庞大 Embedding Tables 的模型的高效部署:
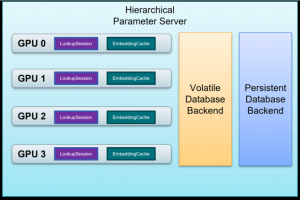
HPS 通过使用集群中可用的存储资源来扩展 GPU 内存,包含 CPU RAM 以及非易失性存储如 HDD 和 SSD,从而实现庞大 Embedding Tables 的分级存储,如图 1 所示;
HPS 通过使用 GPU Embedding Cache 来利用 embedding key 的长尾特性,当查询请求持续不断涌入时,缓存机制保证 GPU 内存可以自动存储热门(高频访问)key 的 Embeddings,从而可以提供低延迟的查询服务;
在 GPU 内存,CPU 内存以及 SSD 组成的存储层级中,HPS 以层级结构化的方式来管理多个模型的 Embedding Tables,实现参数服务器的功能;
HPS 的查询服务通过 Custom TensorFlow Layers 来接入,无论是推理还是类似迁移学习的任务,都可以有效支持。
图 1:HPS 的分级存储架构
TensorFlow 用户可以使用我们提供的 Python APIs,轻松利用 HPS 的上述特性,我们将在下文中进一步介绍。
利用 HPS 来部署包含庞大 Embedding Tables 的 TensorFlow 模型的工作流程如图 2 所示:
图 2:利用 HPS 部署 TensorFlow 模型的工作流程
流程中的步骤可以总结如下:
训练阶段:用户可以用原生的 TensorFlow Embedding Layers(例如 tf.nn.embedding_lookup_sparse)或者支持模型并行的 SOK[1] Embedding Layers(例如 sok.DistributedEmbedding)来搭建模型图并进行训练。只要模型可以用 TensorFlow 进行训练,则无论密集层以及模型图的拓扑结构如何,HPS 都可以在推理阶段集成进来。
分解训练的模型图:用户需要从训练的模型图中提取由密集层组成的子图,并将其单独保存下来。至于训练好的 Embedding Weights,如果使用的是原生 TensorFlow Embedding Layers,则需要提取 Embedding Weights 并将其转换成 HPS 支持的格式;如果使用的是 SOK Embedding Layers,可以利用 sok.Saver.dump_to_file 来直接得到所需的格式。HPS 的格式要求为:每个 Embedding Table 都被保存在一个文件夹中,包含两个二进制文件,key (int64)和 emb_vector(float32)。举例来说,如果一共有 1000 个训练好的键值对,并且 embedding vector 的长度是 16,那么 key 文件和 emb_vector 文件的大小分别为 1000*8 bytes 和 1000*16*4 bytes。
搭建并保存推理图:推理图由 HPS Layers(如 hps.SparseLookupLayer)和保存好的密集层子图搭建而成。只需将训练图中的 Embedding Layer 用 HPS Layers 加以替换,便可以得到推理图。该推理图保存后便可在生产环境中部署。
部署推理图:为了利用 HPS,用户需要提供一个 JSON 文件,来指定待部署模型的配置信息,用以启动 HPS 查询服务。接下来便可以部署保存好的推理图来执行在线推理任务,在此过程中有效地利用 HPS Embedding 查询的优化设计。关于配置信息的更多细节,请参考 HPS Configuration[2]。
HPS 提供了简洁易用的 Python API,可以与 TensorFlow 无缝地衔接。用户只需几行代码,便可以启动 HPS 查询服务以及将 HPS 集成到 TensorFlow 模型图中。
hierarchical_parameter_server.Init:该方法用来针对待部署的模型启动 HPS 查询服务,需要在执行推理任务前被调用一次。必须提供的参数为:
global_batch_size:整型,待部署模型的全局批大小。例如模型部署在 4 个 GPUs 上,每个 GPU 上批大小为 4096,则全局批大小为 16384
ps_config_file:字符串,HPS 初始化所需的 JSON 配置文件
该方法支持显式调用或隐式调用。显式调用用于基于 Python 脚本的测试工作;隐式调用则用于在生产环境中部署模型,要求待部署的推理模型中的 hps.SparseLookupLayer 或 hps.LookupLayer 指定好 global_batch_size 和 ps_config_file,当模型首次接收到推理请求时,会以 call_once 且线程安全的方式触发 HPS 的初始化
hierarchical_parameter_server.SparseLookupLayer:继承自 tf.keras.layers.Layer,通过指定模型名和 table id 订阅到 HPS 查询服务。该层执行与 tf.nn.embedding_lookup_sparse 基本相同的功能。构造时必须提供的参数为:
model_name:字符串,HPS 部署的模型名
table_id:整型,指定的 model_name 的 Embedding Tables 的索引
emb_vec_size:整型,指定的 model_name 和 table_id 的 Embedding Vector 的长度
emb_vec_dtype:返回的 Embedding Vector 的数据类型,目前只支持为 tf.float32
ps_config_file:字符串,HPS 隐式初始化所需的 JSON 配置文件
global_batch_size:整型,待部署模型的全局批大小
执行时的输入和返回值为:
sp_ids:输入,int64 类型的 id 的 N x M SparseTensor,其中 N 通常是批次大小,M 是任意的
sp_weights:输入,可以是具有 float/double weight 的 SparseTensor,或者是 None 以表示所有 weight 应为 1。如果指定,则 sp_weights 必须具有与 sp_ids 完全相同的 shape 和 indice
combiner:输入,指定 reduction 操作的字符串。目前支持“mean”,“sqrtn”和“sum”
max_norm:输入,如果提供,则在 combine 之前将每个 embedding 规范化为具有等于 max_norm 的 l2 范数
emb_vector: 返回值,表示 combined embedding 的密集张量。对于由 sp_ids 表示的密集张量中的每一行,通过 HPS 来查找该行中所有 id 的 embedding,将它们乘以相应的 weight,并按指定的方式组合这些 embedding
hierarchical_parameter_server.LookupLayer:继承自 tf.keras.layers.Layer,通过指定模型名和 table id 订阅到 HPS 查询服务。该层执行与 tf.nn.embedding_lookup 基本相同的功能。构造时的参数与 hierarchical_parameter_server.SparseLookupLayer 相同。执行时的输入和返回值为:
inputs:输入,保存在 Tensor 中的键。数据类型必须为 tf.int64
emb_vector: 返回值,查询到的 Embedding Vector。数据类型为 tf.float32
按照图 2 的工作流程得到集成了 HPS 的推理模型后,用户可以根据生产环境选择多种部署方案:
Triton TensorFlow backend[3]:Triton 推理服务器是开源推理服务软件,可简化 AI 推理流程,支持部署不同深度学习框架的推理模型。集成了 HPS 的 TensorFlow 推理模型可以基于 Triton TensorFlow backend 进行部署,只需将 HPS 的 embedding lookup 视作 custom op,并在启动 tritonserver 前用 LD_PRELOAD 将其 shared library 加载到 Triton 即可
TensorFlow Serving[4]:集成了 HPS 的 TensorFlow 推理模型也可方便地部署在 TensorFlow Serving 这一灵活高性能的推理服务系统上,HPS 的 embedding lookup 同样可作为 custom op 被加载到 TensorFlow Serving中
如果用户希望进一步对集成了 HPS 的推理模型中的密集网络层进行优化,还可以使用 tensorflow.python.compiler.tensorrt.trt_convert 对 SavedModel 进行转换,HPS 的 embedding lookup 可自动 fallback 到其 TensorFlow plugin 对应的 kernels,而可被优化的密集网络层则会生成 TensorRT engine 来执行。转换后的 SavedModel 仍然可以使用 Triton TensorFlow backend 或 TensorFlow Serving 进行部署。
除了使用 HPS 的 TensorFlow plugin 外,用户还可使用 Triton HPS backend[5]。利用 Triton Ensemble Model[6],用户可以方便地将 HPS backend 和其他 Triton backend 连接起来,搭建出 HPS 用于 embedding lookup、其他 backend 用于密集网络层前向传播的推理服务流水线。使用该方案来部署模型的工作流程如图 3 所示:
图 3:利用 Triton Emsemble Model 部署模型的工作流程
这里密集网络层部分除了可以使用 TensorFlow backend 进行部署外,还可以使用 TensorRT backend 进行部署,此时需要将密集网络层的 SavedModel 通过 TensorFlow->ONNX->TensorRT 的转化,得到性能优化的 TensorRT engine。
在这一期的 HugeCTR 分级参数服务器文章中,我们介绍了使用 HPS 部署包含庞大 Embedding Tables 的 TensorFlow 模型的解决方案,工作流程以及 API。更多信息,请参考 HPS 官方文档:
https://nvidia-merlin.github.io/HugeCTR/master/hierarchical_parameter_server/index.html
在下一期中,我们将着重介绍 HugeCTR 分级参数服务器中最关键的组件:Embedding Cache 的设计细节,敬请期待。
以下是 HugeCTR 的 Github repo 以及其他发布的文章,欢迎感兴趣的朋友阅读和反馈。Github:
https://github.com/NVIDIA-Merlin/HugeCTR (更多文章详见 README)
[1] SOK
https://nvidia-merlin.github.io/HugeCTR/sparse_operation_kit/master/index.html
[2] HPS Configuration
https://nvidia-merlin.github.io/HugeCTR/master/hugectr_parameter_server.html#configuration
[3] Triton TensorFlow backend
https://github.com/triton-inference-server/tensorflow_backend
[4] TensorFlow Serving
https://github.com/tensorflow/serving
[5] Triton HPS backend
https://github.com/triton-inference-server/hugectr_backend/tree/main/hps_backend
[6] Triton Ensemble Model
https://github.com/triton-inference-server/server/blob/main/docs/user_guide/architecture.md#ensemble-models
Merlin HugeCTR 分级参数服务器简介
Merlin HugeCTR 分级参数服务器简介之二











