CV-CUDA 高性能图像处理加速库
2022-11-29 12:15
 分享到微信
分享到微信
 分享到微博
分享到微博

CV-CUDA 应用场景

图像背景模糊化通常会被应用于视频会议,美图修图等场景。在这些场景中,我们通常希望 AI 算法可以把主体之外的背景部分模糊化,这样可以保护用户隐私,美化图像等。图像背景模糊化的流程大体可以分为 3 个过程:前处理,DNN 网络以及后处理过程。前处理过程,通常包含了对图像做 Resize、Padding、Image2Tensor 等操作;DNN 网络可以是一些常见 segmentation network,比如 Unet 等;后处理过程,通常包括 Tensor2Mask、Crop、Resize、Denoise 等操作。
在传统的图像处理流程中,前处理和后处理部分通常都是使用 CPU 进行操作,这导致整个图像背景模糊化流程中,有 90% 的工作时间消耗在前后处理部分,因而成为了整个算法流水线的瓶颈。若能把前后处理妥善利用 GPU 加速,这将能大幅提升整体的计算性能。
图 2. AI 背景模糊(GPU 前后处理方案)

当前图像处理主流方案
CV-CUDA 特点
算子数量及其性能

(2) 性能对比
在本文开头的背景模糊算法里,采用 CV-CUDA 替代 OpenCV 和 TorchVision 的前后处理后,整个推理流程的吞吐率提升了 20 倍以上。下图展示了在同一个计算节点上(2x Intel Xeon Platinum 8168 CPUs,1x NVIDIA A100 GPU),以 30fps 的帧率处理 1080p 视频,采用不同的 CV 库所能支持的最大的并行流数。测试采用了 4 个进程,每个进程 batchSize 为 64。
图 5. AI 背景模糊(2x Intel Xeon Platinum 8168 CPUs , 1x NVIDIA A100 GPU)
其中涉及到的前处理操作有:
Resize (Downscale)、Padding、Convert Data Type、Normalize 及 Image to Tensor
涉及到的后处理操作有:
Tensor to Mask、Convert Data Type、Crop、Resize (Upscale)、Bilateral Filter (Denoise)、Gaussian Blur 及 Composite
对于单个算子的性能,我们也做了性能测试,下图的测试场景选用的图片大小为 480*360,CPU 选择为 Intel(R) Core(TM) i9-7900X,BatchSize 大小为 1,进程数为 1。
图 6. CV-CUDA 性能对比(CPU: Intel(R) Core(TM) i9-7900X CPU @ 3.30 GHz)
为了使 CV-CUDA 能够更加高效的运行在 GPU 上,我们采取了一系列的优化手段。
(1)kernel 融合
采用了大量的 kernel 融合策略,减少了 kernel launch 和 global memory 的访问时间。
(2)访存优化
采用了合并访存,向量化读写,shared memory 等策略,提高了数据读写的效率。
(3)异步处理
CV-CUDA 中所有算子均采用异步处理的方式,可以减少同步带来的等待耗时。
(4)高效计算
采用了 fast math、warp/block reduce、table lookup 等优化手段,可以有效提升计算效率。
(5)预分配显存
CV-CUDA 采用了预分配显存策略,并且提供了 Allocator 类,帮助使用者自定义显存分配策略或者可采取默认的显存分配策略。算子所需要的 buffer 和图片显存会在初始化阶段分配好,而在执行阶段不会再进行耗时的显存分配操作。
(1)CV-CUDA 整体架构
整个 CV-CUDA 库包含了以下几个组成部分
a. CV-CUDA 核心模块
核心模块包含了 C/C++ 和 Python API、NVCV 模块,Operator 算子模块以及 CV-CUDA Tools。
b. CV-CUDA Interop 模块
这个模块包含了和其他图像处理库以及推理框架的交互接口,目前支持 OpenCV、Pytorch 和 Pillow,后续将陆续加入其他图像处理库的交互接口。
c. CV-CUDA Tools/Tests
包含一些单元测试模块和工具函数
图 7. CV-CUDA 整体架构
(2)CV-CUDA 核心模块
图 8. CV-CUDA 核心模块
图 10. Resize
字节跳动机器学习团队应用案例
字节跳动机器学习团队某个视频相关的多模态任务,CV-CUDA 应用后就获得了不小的性能收益。该任务预处理部分逻辑很复杂,既有多帧视频的解码,也有很多的数据增强,导致在 A100 上多卡训练时 CPU 资源竞争非常明显,因而虽然已经充分利用了 CPU(Intel Xeon Platinum 8336C)的多核性能,但数据预处理的速度仍然满足不了模型计算的需求。而使用了 CV-CUDA,预处理逻辑被全部迁移到了 GPU,相应的训练瓶颈也由数据预处理转移到了模型计算本身,从而在模型训练的整体性能上我们获得了近 90% 的收益。另一个获得收益的 OCR 任务也十分相似,其预处理链路有十几个算子,使用 CV-CUDA 后我们在 V100 上训练即获得了 80% 的加速。
图 12. CV-CUDA 训练性能收益
需要注意的是,前后处理耗时占比不同的应用在使用 CV-CUDA 后带来的收益提升会有所差异。例如前后处理耗时占比为 50% 的应用,使用 CV-CUDA 后,端到端吞吐率提升的理论上限为原始的 2 倍(理论上限是指预处理耗时为 0,端到端中模型的耗时占比为 100%,实际上前后处理加速后,依然会有耗时,因此理论上限仅用于分析理想情况能达到的最大加速比);而前后处理占比 90% 以上的应用,使用 CV-CUDA 后的吞吐率提升理论上限为原始的 10 倍以上。此外,CPU 性能的差异也会影响到最终的加速效果。
(2) 模型推理
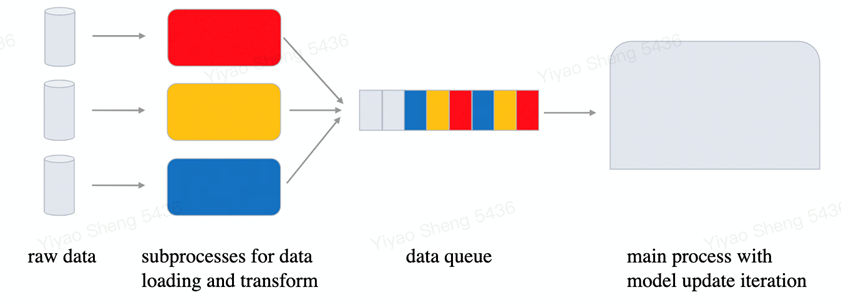
模型推理和训练略有不同:因为模型训练时数据读取和模型更新是异步的,所以基本上提升模型训练性能可以与提高 GPU 利用率划等号。但模型推理过程,数据读取和模型计算是一个串行的过程,加速数据准备过程本身即会对整体性能造成直接影响。再加上模型推理时只涉及到模型前向的计算,计算量一般都较小,GPU 通常有足够的剩余资源来进行其他的工作。因而模型推理阶段,把预处理逻辑搬到 GPU 上来加速性能,既合理而又有可行性。
图 13. 模型推理流程示意图
附录