
DevZone | NVIDIA HPC SDK
2022-09-30 19:25
 分享到微信
分享到微信
 分享到微博
分享到微博
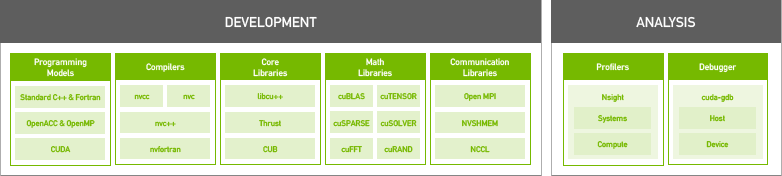
NVIDIA HPC SDK 包含经过验证的编译器、库和软件工具,对于更大程度提高开发者的工作效率以及 HPC 应用的性能和可移植性至关重要。
NVIDIA HPC SDK C、C++ 和 Fortran 编译器支持使用标准 C++ 和 Fortran、OpenACC 指令和 CUDA 实现 HPC 建模和模拟应用的 GPU 加速。GPU 加速的数学库可更大限度地提升常用 HPC 算法的性能,而经过优化的通信库支持基于标准的多 GPU 和可扩展的系统编程。性能分析和调试工具可简化 HPC 应用的移植和优化流程,而容器化工具支持在本地或云端轻松部署。HPC SDK 支持 NVIDIA GPU 和 Arm、OpenPOWER 或运行 Linux 的 x86-64 CPU,为您提供构建 NVIDIA GPU 加速的 HPC 应用所需的工具。
为何要使用 NVIDIA HPC SDK?
性能
除了应用广泛的 HPC 应用(包括 VASP、Gaussian、ANSYS Fluent、GROMACS 和 NAMD),还可以使用 CUDA、OpenACC 和 GPU 加速的数学库,为用户提供突破性性能。您可以使用这些相同的软件工具对应用进行 GPU 加速,还可以使用 NVIDIA GPU 实现速度和能效大幅提升。
可移植性
为 99% 以上的 500 强系统(包括基于 NVIDIA GPU 或 x86-64、Arm 或 OpenPOWER CPU 的系统)构建和优化应用。您可以使用嵌入式库、C++17 并行算法和 OpenACC 指令对您的代码进行 GPU 加速,并确保应用完全可移植到其他编译器和系统。
工作效率
借助能够让您快速移植、并行和优化 GPU 加速的单一集成套件(包括用于多 GPU 和可扩展计算的行业标准通信库,以及用于分析的分析和调试工具),可以更大限度地提高科学和工程吞吐量,更大限度地减少编码时间。
支持您喜欢的编程语言
C++17 并行算法
C++17 并行算法使用标准模板库(STL)实现可移植的并行编程。NVIDIA HPC SDK C++ 编译器在 CPU 上支持完整的 C++17,可将并行算法分流至 NVIDIA GPU,支持无指令、杂注或标注的 GPU 编程。使用 C++17 并行算法的程序很容易移植到常用 C++ 的 Linux、Windows 和 macOS。
Fortran 2003 编译器
NVIDIA Fortran 编译器支持 Fortran 2003,以及 Fortran 2008 的许多功能。它支持在 GPU 上的 OpenACC 和 CUDA Fortran,也支持在 x86-64、Arm 和 OpenPOWER 这些多核 CPU 上的 SIMD 向量化、OpenACC 和 OpenMP。这样,他就具有在当今由 GPU 加速的异构 HPC 系统上移植和优化 Fortran 应用所需的功能。
OpenACC 指令
NVIDIA Fortran、C 和 C++ 编译器支持基于 OpenACC 指令的并行编程,适用于 NVIDIA GPU 和多核 CPU。超过 200 款 HPC 应用端口已使用 OpenACC 启动或启用,包括 VASP、Gaussian、ANSYS Fluent、WRF 和 MPAS 等量产型应用。OpenACC 适用于 GPU 和多核 CPU,是经过验证的性能可移植指令解决方案。
主要功能
GPU 数学库
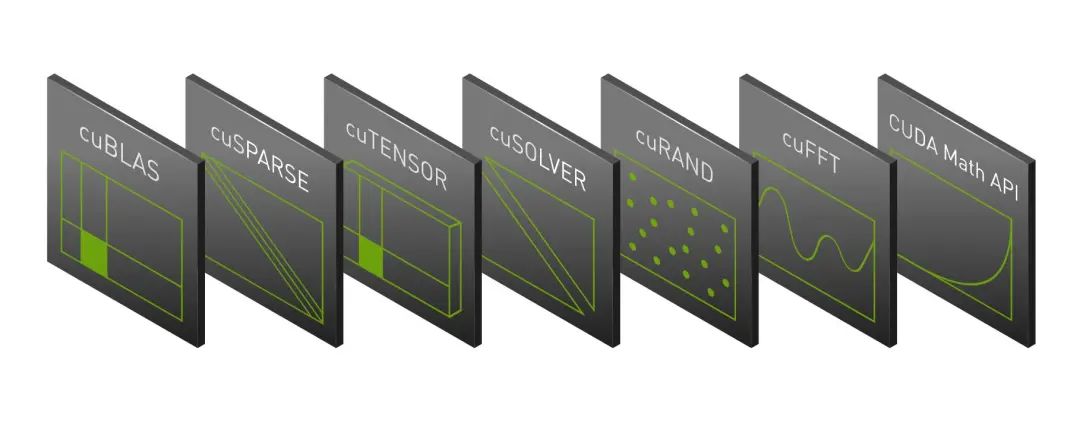
NVIDIA HPC SDK 包括一套 GPU 加速的数学库,适用于计算密集型应用。cuBLAS 和 cuSOLVER 库可提供来自 LAPACK 的各种 BLAS 例程和核心例程的经 GPU 优化的多 GPU 的实施,并尽可能自动使用 NVIDIA GPU Tensor Core。cuFFT 包括用于真实和复杂数据的 GPU 加速的 1D、2D 和 3D FFT 例程,cuSPARSE 为稀疏矩阵提供基础线性代数子例程。可以通过使用 C、C++ 和 Fortran 编写的 CUDA 和 OpenACC 程序调用这些库。
对 Tensor Core 进行优化

通过 NVIDIA GPU Tensor Core,科学家和工程师能够使用混合精度或双精度大幅加速合适的算法。这些 NVIDIA HPC SDK 数学库对 Tensor Core 和多 GPU 节点进行了优化,无需多费力编码,即可提供系统的全部性能潜力。利用 NVIDIA Fortran 编译器,通过将可转换的数组内联函数自动映射至 cuTENSOR 库,您可以使用 Tensor Core。
对您的 CPU 进行优化

异构 HPC 服务器使用 GPU 进行加速计算,并基于 x86-64、OpenPOWER 或 Arm 指令集架构使用多核 CPU。NVIDIA HPC 编译器和工具在这些 CPU 上受支持,并且所有编译器优化可在支持这些编译器的 CPU 上完全启用。借助跨所有受支持系统的统一功能、命令行选项、语言实现、编程模型、工具和库用户界面,NVIDIA HPC SDK 可简化开发者在各种 HPC 环境中的体验。
多 GPU 编程
NVIDIA 集合通信库(NCCL)使用 MPI 兼容的 all-gather、all-reduce、broadcast、reduce 和 reduce-scatter 例程实现高度优化的多 GPU 和多节点集合通信基元,以利用 HPC 服务器节点内和跨 HPC 服务器节点的所有可用 GPU。NVSHMEM 可实现 GPU 显存的 OpenSHMEM 标准,并提供多 GPU 和多节点通信基元,这些基元可通过主机 CPU 或 GPU 启动,也可在 CUDA 内核中调用。
可扩展系统编程

MPI 是编程分布式内存可扩展系统的标准。NVIDIA HPC SDK 包括基于 Open MPI 的 CUDA-aware MPI 库,支持 GPUDirect,这样您可以直接使用远程直接数据存取(RDMA)来发送和接收 GPU 缓冲区,包括在 CUDA 统一内存中分配的缓冲区。CUDA-aware Open MPI 完全兼容 CUDA C / C++、CUDA Fortran 和 NVIDIA OpenACC 编译器。
Nsight 性能分析
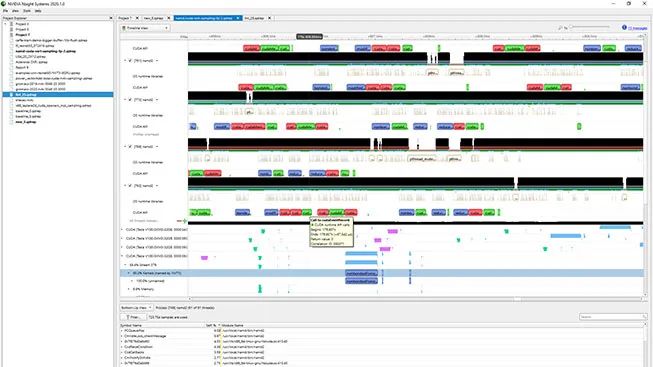
Nsight 系统可在系统范围内可视化 HPC 服务器上的应用性能,并使您能够在多核 CPU 和 GPU 中优化瓶颈并扩展并行应用。Nsight Compute 允许您通过图形或命令行用户界面,在交互式分析器中深入探讨 GPU 内核,以用于 GPU 加速的应用,并允许您使用 NVTX API 直接检测源代码的区域,从而确定性能瓶颈。
随时随地部署

容器将应用及其依赖项捆绑到便携式虚拟环境中,从而简化软件部署。NVIDIA HPC SDK 包含使用 HPC Container Maker 开发、分析和部署软件简化容器镜像创建流程的说明。NVIDIA Container Runtime 可在几乎所有容器框架(包括 Docker 和 Singularity)中实现无缝 GPU 支持。











