为什么 NVIDIA Grace Hopper 是新一代推荐系统的理想之选
2022-09-23 09:49
#人工智能 # #GTC22 #GraceHopper
 分享到微信
分享到微信
 分享到微博
分享到微博
作为互联网的经济引擎,推荐系统获得了 NVIDIA Grace Hopper 超级芯片的全新加持。
推荐系统每天向数十亿人提供数万亿的搜索结果、广告、产品、音乐和新闻报道。这些系统在帮助用户从嘈杂的信息中获取有用信息时令人难以置信地高效,因此是我们这个时代最重要的 AI 模型之一。
这些机器学习工作流使用 TB 级数据。推荐系统消耗的数据越多,结果就越准确,所提供的投资回报就越多。
为了应对这些数据海啸,各公司已经开始采用加速计算来为客户提供个性化服务。Grace Hopper 将把加速计算带来的好处提升到一个新的高度。
GPU 可将参与度提高 16%
图片共享社交媒体公司 Pinterest 通过采用 NVIDIA GPU,可以将推荐系统模型的规模提升至原来的 100 倍。直接帮助其 4 亿多用户的参与度提高了 16%。
该公司的一位软件工程师在最近的一篇博客中表示:“通常情况下,能有 2% 的增长我们就已经感到很满意了,而现在,16% 仅仅是个开始。我们看到了额外的收益,它打开了许多机会之门。”
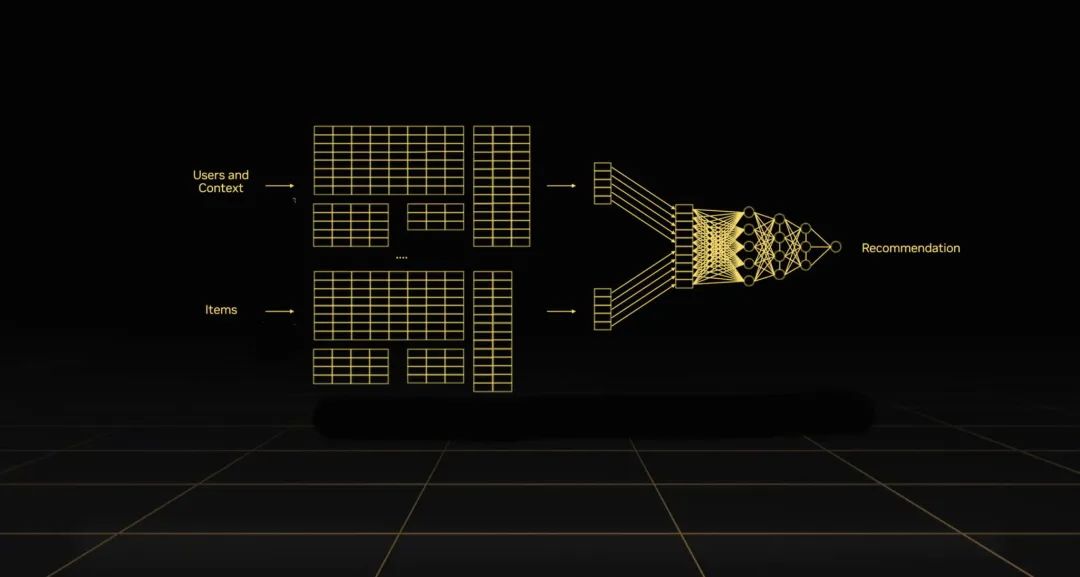
推荐系统会使用数十 TB 的向量表示,这些数据表为准确预测提供了上下文。
新一代 NVIDIA AI 平台有望为使用超大规模推荐系统模型处理大规模数据集的公司带来更大的收益。
由于数据是 AI 的燃料,Grace Hopper 相比地球上任何其他处理器旨在将更多数据输送给推荐系统。
NVLink 加速 Grace Hopper
Grace Hopper 能够实现这一点,是因为它是一种超级芯片,一个单元包含两个芯片,共享高速的芯片到芯片互连。它包括一个基于 ARM 的 NVIDIA Grace CPU 和一个 Hopper GPU,它们之间通过 NVIDIA NVLink-C2C 进行通信。
此外,NVLink 还将许多超级芯片连接成一个超级系统,是专为运行 TB 级推荐系统而构建的计算集群。
NVLink 以高达每秒 900 GB 的速度传输数据,是 PCIe 5.0 带宽的 7 倍,后者是即将推出的前沿系统将使用的互联带宽。
这意味着 Grace Hopper 向推荐系统提供 7 倍以上的向量表示(包含上下文),满足用户对个性化结果的需求。
内存越大,效率越高
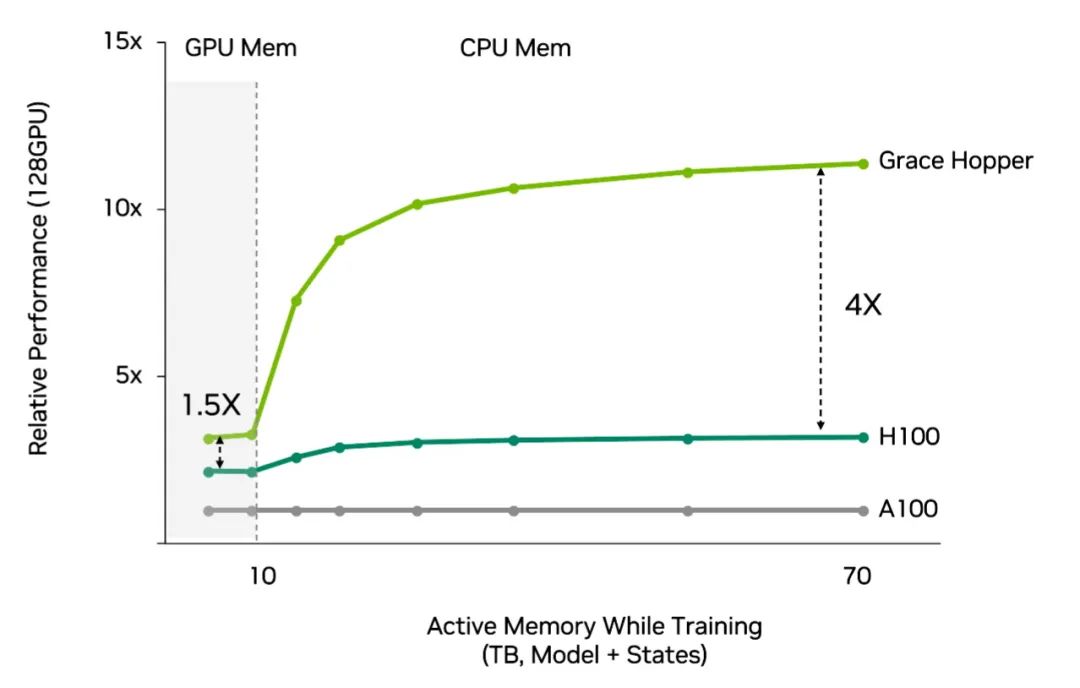
Grace CPU 使用 LPDDR5X,这种内存在用于推荐系统和其他要求苛刻的工作负载时,能够在带宽、能效、容量和成本之间达到最佳平衡。它提供的带宽增加 50%,而每 GB 的功耗仅为传统 DDR5 内存子系统的八分之一。
集群中的任何 Hopper GPU 都可以通过 NVLink 访问 Grace 的内存。这是 Grace Hopper 的一项功能,可提供之前没有的庞大的 GPU 显存池。
此外,NVLink-C2C 每传输一位数据仅需 1.3 皮焦,其能效是 PCIe 5.0 的 5 倍以上。
总体效果上,与采用传统 CPU 的 Hopper 相比,推荐系统在使用 Grace Hopper 时的性能和效率提升高达 4 倍(请参阅下图)。
您需要的所有软件
Grace Hopper 超级芯片使用全堆栈的 NVIDIA AI 软件,这些软件被用于当今世界最大的推荐系统之中。
NVIDIA Merlin 是推荐系统的强大动力,它包含构建 AI 系统的模型、方法和库的集合,可以提供更好的预测并增加点击率。
NVIDIA Merlin HugeCTR 是一种推荐系统框架,可在 NVIDIA 集合通信库的帮助下,帮助用户在分布式 GPU 集群下快速处理大量数据集。











