
NVIDIA 分享关于 Grace CPU、Hopper GPU、NVLink Switch 最新细节
2022-09-05 14:38
 分享到微信
分享到微信
 分享到微博
分享到微博

在为期两天的四场演讲中,NVIDIA 高级工程师介绍了现代数据中心和网络边缘系统在加速计算方面的创新。
虚拟 Hot Chips 大会是处理器和系统架构师的年度聚会。NVIDIA 高级工程师在演讲中披露了 NVIDIA 首款服务器 CPU、Hopper GPU、新版 NVSwitch 互连芯片和 NVIDIA Jetson Orin 系统模块 (SoM) 的性能数据和其他技术细节。
这些演讲就 NVIDIA 平台如何在性能、效率、规模和安全性方面达到更高水平提供了新见解。
具体来说,演讲展示了某种设计理念,即在 GPU、 CPU 和 DPU 充当对等处理器的整个芯片、系统和软件堆栈中进行创新。他们共同创建的平台已经在云服务提供商、超级计算中心、企业数据中心和自主系统内运行 AI、数据分析和高性能计算工作。
了解 NVIDIA 首款服务器 CPU
数据中心需要灵活的 CPU、GPU 和其他加速器集群共享海量内存池,以提供当今工作负载所需的高效性能。
为满足这一需求,NVIDIA 的杰出工程师兼 15 年资深员工 Jonathon Evans 介绍了 NVIDIA NVLink-C2C。它以每秒 900 GB 的速度连接 CPU 和 GPU,归功于每比特仅消耗 1.3 皮焦耳的数据传输,其能效是现有 PCIe 5.0 标准的 5 倍。
NVLink-C2C 连接两个 CPU 芯片,可创建具有 144 个 Arm Neoverse 核心和 512 GB 内存的 NVIDIA Grace CPU——用于解决全球大型计算问题的处理器。
为更大限度地提高效率,Grace CPU 使用 LPDDR5X 内存。它可实现每秒 1 TB 的内存带宽,同时将整个复合体的功耗保持在 500 瓦。
一个链接,多种用途
NVLink-C2C 还在 NVIDIA Grace Hopper 超级芯片中将 Grace CPU 和 Hopper GPU 芯片作为内存共享对等体关联,更大限度地加速像 AI 训练这样对性能要求很高的作业。
任何人都可以使用 NVLink-C2C 构建定制小芯片,以协调地连接 NVIDIA GPU、CPU、DPU 和 SoC,扩展这一新的集成产品类别。互连将支持 Arm 和 x86 处理器各自使用的 AMBA CHI 和 CXL 协议。
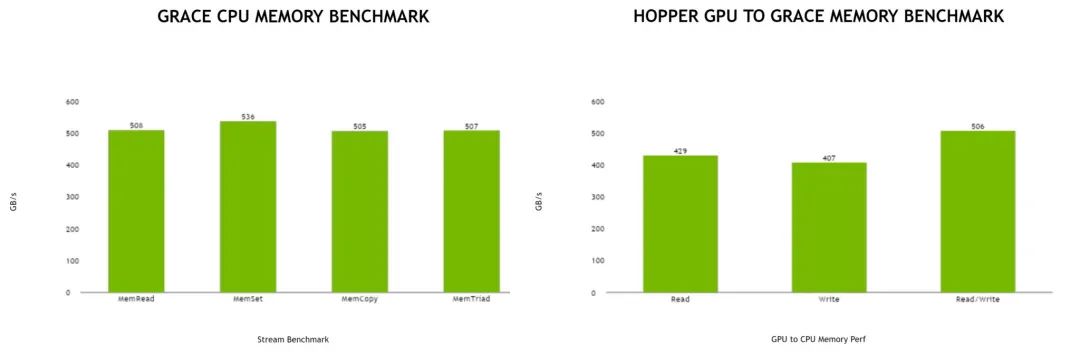
Grace 和 Grace Hopper 的首个内存基准测试
为了在系统层面进行扩展,新的 NVIDIA NVSwitch 将多台服务器连接到一台 AI 超级计算机。它使用 NVLink,互联速度为每秒 900 GB,是 PCIe 5.0 带宽的 7 倍以上。
NVSwitch 使用户能够将 32 个 NVIDIA DGX H100 系统连接到一台 AI 超级计算机中,这台超级计算机可以提供百亿亿次级峰值 AI 性能。
NVIDIA 的两位资深工程师 Alexander Ishii 和 Ryan Wells 介绍该交换机如何助力用户构建可支持多达 256 个 GPU 的系统,以处理要求严苛的工作负载,例如训练具有超过 1 万亿参数的 AI 模型。
该交换机包括使用 NVIDIA SHARP™ 技术加速数据传输的引擎。SHARP 是网络计算功能,最初在 NVIDIA Quantum InfiniBand 网络上使用。它可以使通信密集型 AI 应用的数据吞吐量翻倍。

NVSwitch 系统支持百亿亿次级 AI 超级计算机
Jack Choquette 是在 NVIDIA 任职 14 年的杰出高级工程师,他详细介绍了 NVIDIA H100 Tensor Core GPU(也称为 Hopper)。
除使用新的互连技术扩展到新的高度外,它还包括许多先进功能,可提升加速器的性能、效率和安全性。
与上一代相比,Hopper 的新 Transformer 引擎和升级版 Tensor Core 可在使用全球大型神经网络模型进行 AI 推理时,将速度提升 30 倍。此外,它采用全球首款 HBM3 内存系统,可提供高达 3 TB 的内存带宽,这是 NVIDIA 有史以来幅度超大的代际提升。
其他新功能包括:
Hopper 添加了针对多租户、多用户配置的虚拟化支持。
新的 DPX 指令集可加快选定映射、DNA 和蛋白质分析应用的递归循环速度。
Hopper 还支持通过机密计算增强安全性。
Choquette 在职业生涯早期曾是任天堂 64 游戏机的首席芯片设计师,他还介绍了一些 Hopper 进步背后的并行计算技术。
Michael Ditty 是 Orin 的首席架构师并在 NVIDIA 任职 17 年,他讲解了 NVIDIA Jetson AGX Orin(适用于边缘 AI、机器人开发和高级自主机器的引擎)的新性能规格。
NVIDIA Jetson AGX Orin 集成了 12 个 Arm Cortex-A78 核心和一个 NVIDIA Ampere 架构 GPU,可为 AI 推理作业提供每秒高达 275 万亿次运算。相较上一代,能效提升 2.3 倍,性能提升高达 8 倍。
新的生产模块包含高达 32 GB 的内存,是兼容系列的一部分,可缩小至口袋大小的 5W Jetson Nano 开发者套件。
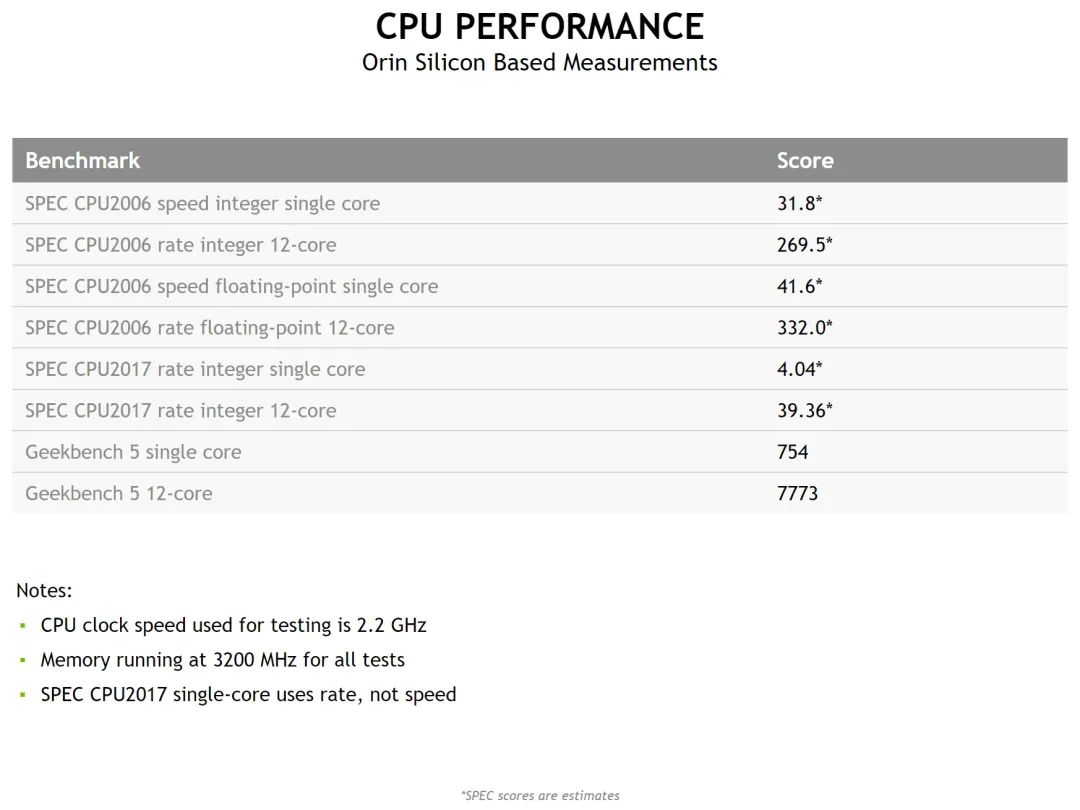
NVIDIA Orin 的性能基准测试
所有新芯片都支持 NVIDIA 软件堆栈,该堆栈可加速 700 多个应用,为 250 万名开发者所用。
它基于 CUDA 编程模型,包含数十个面向垂直市场的 NVIDIA SDK,例如汽车 (DRIVE) 和医疗健康 (Clara),以及推荐系统 (Merlin) 和对话式 AI (Riva) 等技术。
各大云服务和系统制造商均提供 NVIDIA AI 平台。











