
使用 Omniverse Replicator 构建自定义合成数据生成管线
2022-07-06 11:07
 分享到微信
分享到微信
 分享到微博
分享到微博
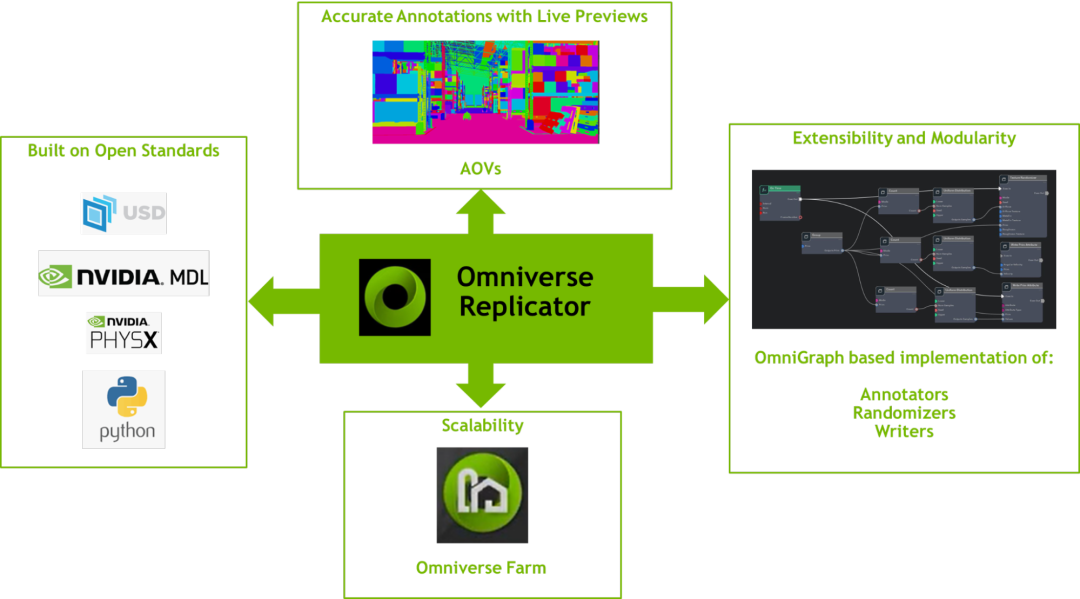
语义模式编辑器:通过对 3D 资产及其 prim 进行语义标记,Replicator 可以在渲染和数据生成过程中对目标对象进行注释。语义模式编辑器提供一种通过用户界面将这些标签应用于 prim 的方式。
可视化器:为分配给 3D 资产的语义标签以及 2D/3D bounding box、法线、深度等注释提供可视化功能。
随机发生器:域随机化是 Replicator 最重要的功能之一。用户可以使用随机发生器创建随机化的场景,从资产、材质、照明和摄像机位置等随机化能力中取样。
Omni.syntheticdata:提供与 Omniverse RTX 渲染器和 OmniGraph 计算图系统的低层次集成,驱动 Replicator 的基准真值数据提取注释器,将任意输出变量(AOV)从渲染器传递到注释器。
注释器:从 Omni.syntheticdata 扩展程序中提取 AOV 和其他输出,生成用于深度神经网络(DNN)训练的精确标记注释。
写入器:处理来自注释器的图像和其他注释,并生成用于训练的 DNN 专用数据格式。
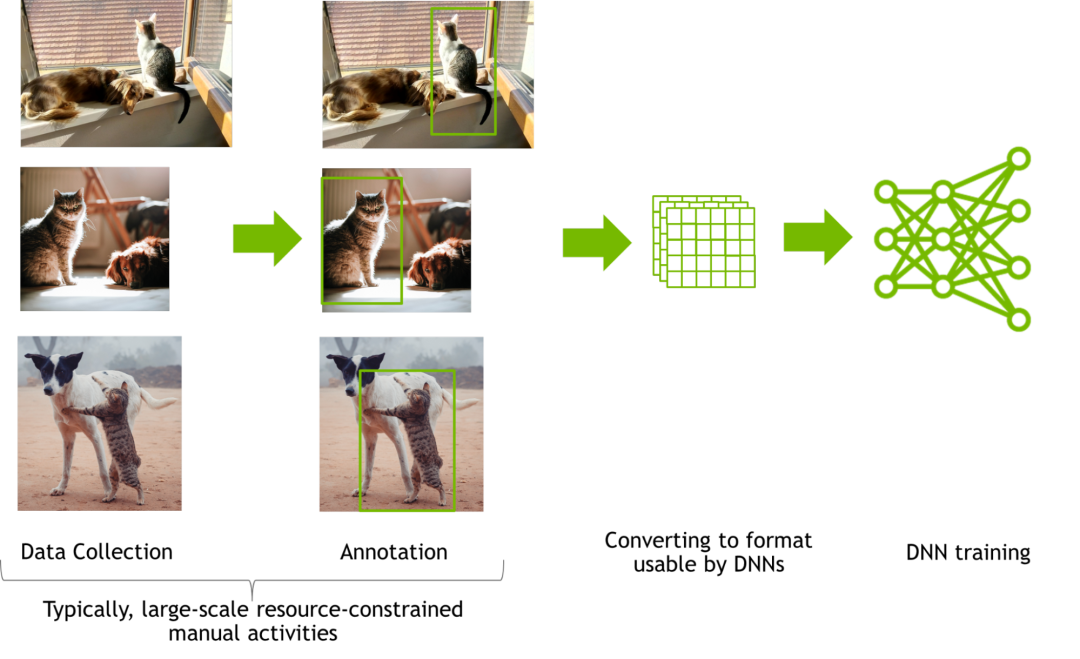

图3:语义分割任务的复杂性
在采集和注释完毕后,数据将被转换成 DNN 可用的格式,然后训练用于感知任务的 DNN。一般情况下,接下来会通过超参数调节或改变网络结构来优化网络性能。在对模型性能进行分析时,可能会导致数据集发生变化,在大多数情况下,还需要进行一轮手动数据采集和注释,这种人工数据采集和注释的迭代循环是昂贵、乏味且缓慢的。
凭借以合成方式生成的数据,团队就能以一种高成本效益的方式启动和加强带有准确注释的大规模训练数据的生成。此外,合成数据生成还有助于解决与长尾异常、缺乏可用训练数据和在线强化学习有关的挑战。不同于人工采集和注释的数据,以合成方式生成的数据具有较低的摊销成本。由于数据采集/注释和模型训练周期一般具有迭代性,因此这一点十分有益。
Omniverse Replicator 通过利用 Omniverse 平台的众多核心功能和最佳实践来解决这些挑战,包括但不限于物理级精确、逼真的数据集和对超大数据集的访问。
为了生成物理级精确的逼真数据集,需要使用各种 RTX 技术、基于物理学的材质和物理引擎等 Omniverse 平台的所有核心技术进行准确的光线追踪和路径追踪。
图5:使用 Omniverse Replicator 增强仓库场景中的传感器注释
使用 Omniverse Replicator 和 TAO 工具套件加速现有的工作流程
开发者、工程师和研究人员可以将 Omniverse Replicator 与现有的工具进行整合,来加快 AI 模型的训练速度。例如,在生成合成数据后,开发者可以利用 NVIDIA TAO 工具套件快速训练他们的 AI 模型。TAO 工具套件利用迁移学习让开发者无需事先掌握 AI 专业知识,就能根据其用例来训练、调整和优化模型。
图6:用于合成数据生成和模型训练的 Omniverse Replicator 和 TAO 工具套件工作流程
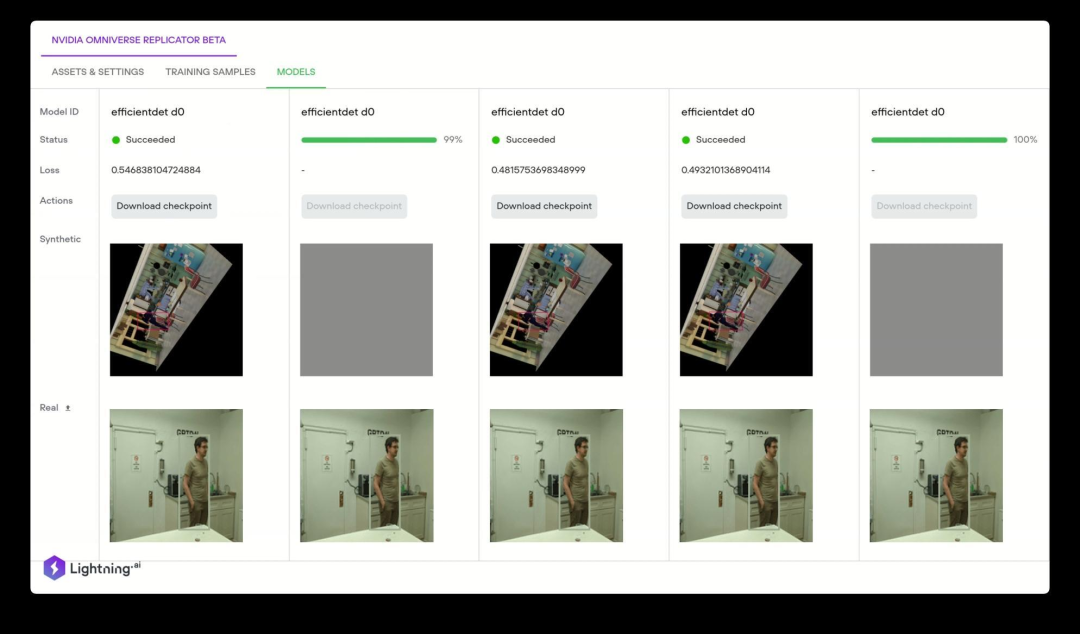
NVIDIA Isaac Sim 和 DRIVE Sim 团队使用 Omniverse Replicator SDK 构建特定领域的合成数据生成工具——用于机器人的 Isaac Replicator 和用于自动驾驶汽车训练的 DRIVE Replicator。Omniverse Replicator SDK 为开发者提供一套核心功能,方便开发者利用 Omniverse 平台所提供的所有优势建立任何特定领域的合成数据生成管线。Replicator 通过将 Omniverse 作为 3D 模拟、渲染和 AI 开发能力的开发平台,提供自定义合成数据生成管线。
图8:使用 Omniverse Replicator 构建的 NVIDIA Isaac Sim(左)和 DRIVE Sim(右)合成数据生成能力
使用 Omniverse Replicator
现在可以在 Omniverse Code 中使用 Omniverse Replicator SDK。用户可从 Omniverse Launcher 下载 Omniverse Code。











