
NVIDIA 通过全栈创新推动高性能计算的发展
2022-06-08 20:27
 分享到微信
分享到微信
 分享到微博
分享到微博
本文作者:
Ashraf Eassa NVIDIA 加速计算部门高级产品营销经理
Chris Porter NVIDIA HPC & AI 高级技术营销经理
高性能计算(HPC)已经成为必不可少的科学研究工具。
无论是研发出拯救生命的新药,还是抵御气候变化,或是精确模拟我们的世界,这些解决方案都需要强大的处理能力,而且这一需求正在快速增长,日益超出传统计算方法能够应对的范畴。
因此,业界纷纷采用 NVIDIA 的 GPU 进行加速计算。结合 AI,它能带来数百万倍的性能加速,推动科学的进步。如今,已有 2700 个应用受益于 NVIDIA GPU 加速,而在日益增长的 300 万开发者共同组成的社区支持下,这一数字仍在不断攀升。
HPC 应用性能提升
为将所有 HPC 应用的速度提升数倍,我们需要在堆栈的每个层面进行不断的创新,包括芯片、系统以及应用框架本身。
随着架构和 NVIDIA 软件栈整体上的不断进步, NVIDIA 平台的性能每年都会显著提高。与六年前发布的 P100 相比, H100 Tensor Core GPU 的性能提高 26 倍,比摩尔定律快 3 倍以上。
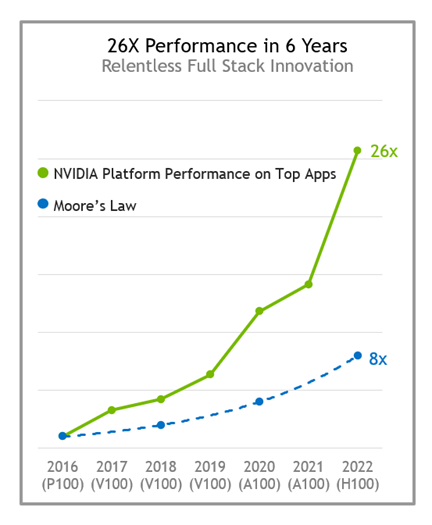
从 P100 到 H100 的 NVIDIA HPC + AI 平台性能
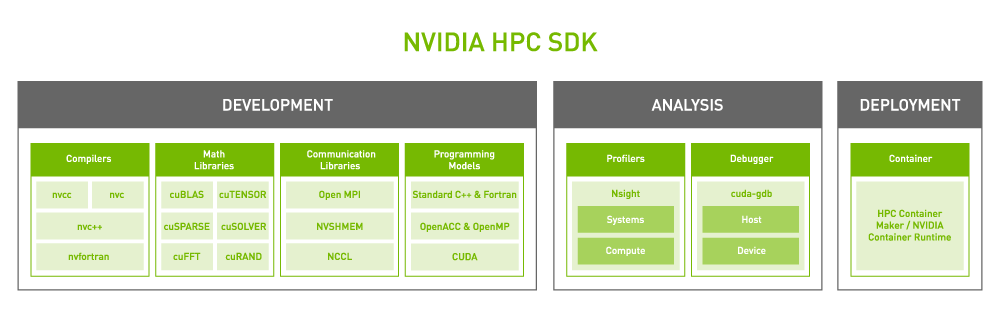
NVIDIA HPC SDK 为每项功能提供开发者资产
NVIDIA 平台的核心是一个功能丰富的高性能软件堆栈。为了方便各种 HPC 应用实现 GPU 加速,该平台加入了 NVIDIA HPC SDK。SDK 使开发者能够使用标准语言、导语指令以及 CUDA 来编写和移植 GPU 加速应用,为开发者带来了无与伦比的灵活性。
NVIDIA HPC SDK 的强大之处在于其庞大且高度优化的 GPU 加速数学库,使用户能够充分发挥 NVIDIA GPU 的性能潜力。为了实现最佳的多 GPU 和多节点扩展性能, NVIDIA HPC SDK 还提供强大的通信库:
NVSHMEM 为跨多个 GPU 内存的数据创建了一个全局地址空间。
NVIDIA 集合通信库(NCCL)优化了 GPU 之间的通信。
总之,该平台提供最高的性能和灵活性,为庞大的、不断增长的 GPU 加速 HPC 应用提供支持。
HPC 的性能和能效
为了展示 NVIDIA 全栈创新如何助力加速 HPC 实现最高性能, 我们将一台配备 4 颗 NVIDIA GPU 的慧与(HPE)服务器与一台配备另一家厂商同等数量加速器模块且配置相似的服务器进行了性能比较。
我们使用多种算例测试了广泛使用的五个 HPC 应用。尽管在各个行业中有约 2700 个应用基于 NVIDIA 平台实现了加速,但由于另一家厂商的加速器只支持部分软件和应用版本,我们在此次比较中所能使用的应用有限。
对于除 NAMD (用于分子动力学模拟的软件)以外的所有应用,我们首先获得多个算例的结果,然后使用它们的几何平均值作为计算结果,这样可以将异常值的影响最小化并反映客户的体验。
我们还在多 GPU 和单 GPU 场景下测试了这些应用。
在多 GPU 场景中,测试系统中的所有加速器都被用来运行一个模拟,基于 A100 Tensor Core GPU 的服务器所提供的性能比起另一台服务器高出 2.1 倍。

NVIDIA A100 4x GPU 性能对比
得益于计算性能的持续进步,分子动力学领域正朝着模拟更大的原子体系和更长的时间的方向发展。这使研究者能够模拟越来越多的生物化学机制,例如光合电子传递和视觉信号转导。对于此类过程,由于模拟这一主要验证方式耗时过长,之前无法通过模拟来对其进行验证,导致这类过程也一直引发科学界的争论。
但我们认识到,并非所有用户都会在每次模拟时使用多个 GPU 运行。为了获得最佳吞吐量,最好的方法往往是为每次模拟分配一个 GPU。
当在单一加速器模块( NVIDIA A100 上一个的完整 GPU 和另一款产品上的两个计算芯片)上运行这些应用时,基于 NVIDIA A100 的系统提供了高达 1.9 倍的性能。
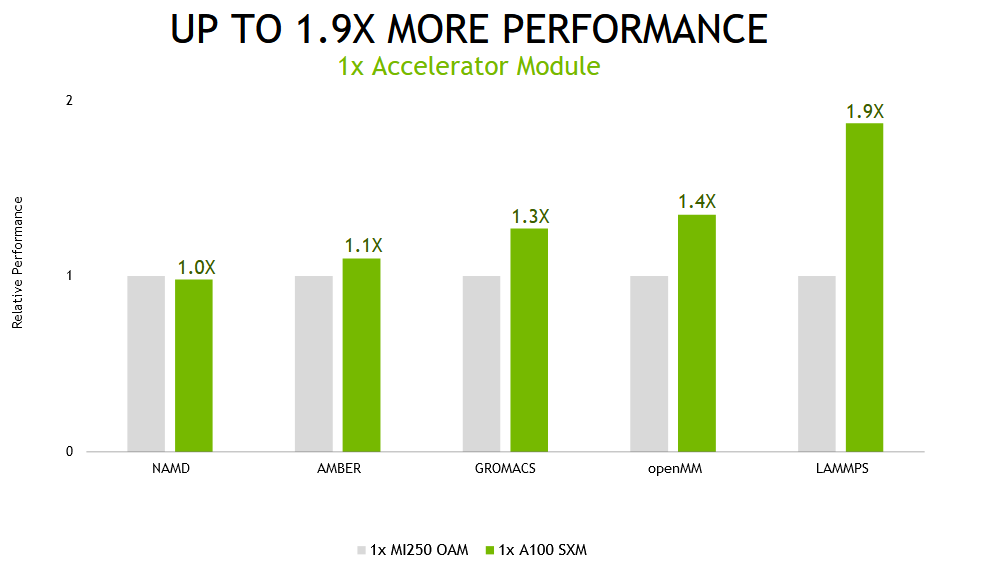
NVIDIA A100 1x GPU 性能对比
电力成本占据了数据中心和超级计算中心总拥有成本(TCO)中的很大一部分,这突出了高能效计算平台的重要性。根据我们的测试, NVIDIA 平台的每瓦吞吐量比其他产品高 2.8 倍。

NVIDIA A100 能效对比
图中所示的是 A100 与 MI250 的效率比,这个比值越高越好。每个应用在多个算例上的几何平均值。效率指 GPU 性能/功耗(瓦),使用 NVIDIA SMI 和 ROCm 中的同等功能命令测量。
AMD MI250 在技嘉 M262-HD5-00 上使用(2个) AMD EPYC 7763 和 4x AMD Instinct™ MI250 OAM (128 GB HBM2e)500W GPU 以及 AMD Infinity Fabric™ 技术测得。NVIDIA 在 ProLiant XL645d Gen10 Plus 上使用双 EPYC 7713 CPU 和 4x A100 (80 GB) SXM4 测试。
LAMMPS develop_db00b49(AMD) develop_2a35ec2(NVIDIA) datasets ReaxFF/c, Tersoff, Leonard-Jones, SNAP | NAMD 3.0alpha9 dataset STMV_NVE | OpenMM 7.7.0 Ensemble runs for datasets: amber20-stmv, amber20-cellulose, apoa1pme, pme|?
GROMACS 2021.1(AMD) 2022(NVIDIA) datasets ADH-Dodec (h-bond), STMV (h-bond) | AMBER 20.xx_rocm_mr_202108(AMD) and 20.12-AT_21.12 (NVIDIA) datasets Cellulose_NVE, STMV_NVE | 1x MI250 has 2x GCD
多年来, 我们为了最大限度地提高应用性能和效率而坚持不懈地进行软硬件协同优化,最终打造出具有卓越性能和能效的 NVIDIA A100 GPU。欲进一步了解 NVIDIA Ampere 架构,请参见 NVIDIA A100 Tensor Core GPU 白皮书。
A100 在操作系统中也表现为一个单一的处理器,只需要启动一个 MPI 线程就可以充分发挥它的性能。而且由于一个节点中所有 GPU 之间都采用 600-GB/s NVLink 互联,因此 A100 可以提供出色的扩展性能。
AI 与 HPC 的融合
正如加速计算将模拟和仿真应用的速度提高了数倍, AI 和 HPC 的结合也将进一步提升性能,推动下一波科学研究的发展。
从我们首次提交 MLPerf 训练结果到最近一次提交,已有三年的时间。在这三年里, NVIDIA 平台在这套由同行评审的行业标准基准测试中将深度学习性能提高了 20 倍。这些成果来自于芯片、软件和规模上的全面提高。
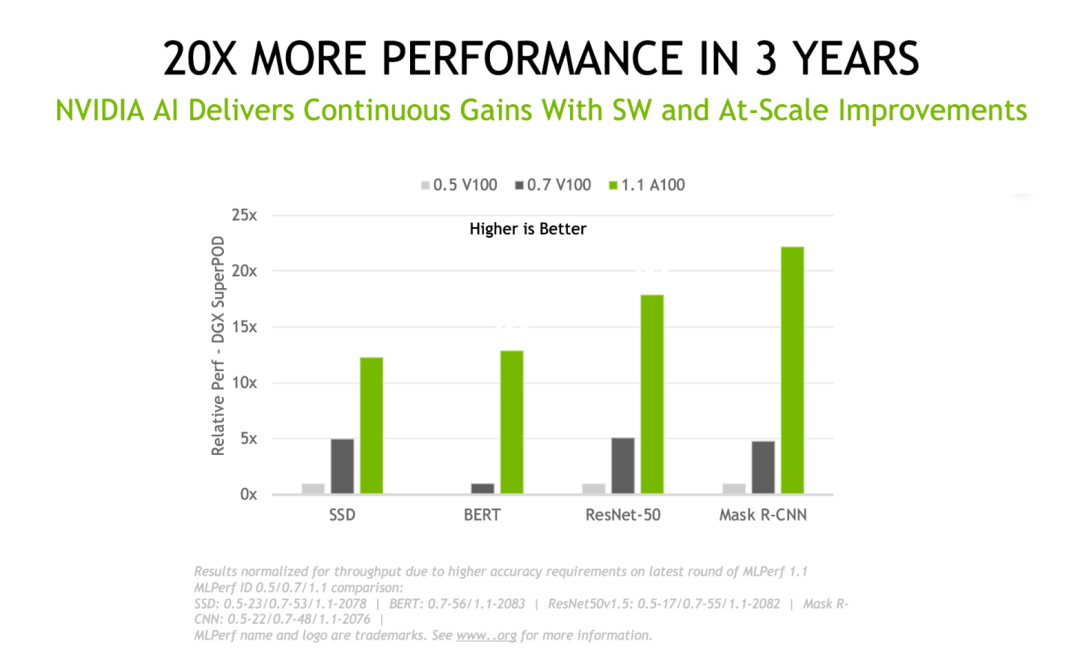
NVIDIA 三年以来的性能提升
科学家和研究者已在使用 AI 大幅提升性能,加快科学研究的速度。
使识别引力波所需的时间减少为原来 10 万分之一。
对呼吸道飞沫中的 Delta SARS-CoV-2 病毒(原子数超过 10 亿)进行模拟的速度提高 1000 倍。
加速清洁聚变能源的发展。
为余热锅炉(HRSG)工厂创建预测性数字孪生。
世界各地的超级计算中心都在持续使用加速 AI 超级计算机。
阿贡领导力计算设施(ALCF)的 Polaris 超级计算机、美国国家能源研究科学计算中心(NERSC)的 Perlmutter、意大利多所大学组建的 CINECA 联盟建设的 Leonardo,均采用 A100 Tensor Core GPU 加速。
即将在 2023 年上线的 Alps 超级计算机基于 NVIDIA 的 Grace Hopper 超级芯片打造而成。
计划于 2023 年交付的洛斯阿拉莫斯国家实验室的 Venado 系统,将包含 Grace Hopper 超级芯片以及 Grace CPU 超级芯片节点。











