
NVIDIA 大讲堂 “520” 特别篇 | 什么是情感分析?
2022-05-23 20:43
 分享到微信
分享到微信
 分享到微博
分享到微博
情感分析是指根据文本数据(例如书面评论和社交媒体帖子)自动解释和分类情感(通常是积极、消极或中立)的分析过程。
什么是情感分析?
情感分析是一个自然语言处理 (NLP) 的分支,它使用机器学习来分析和分类文本数据的情感基调。基本模型主要专注于积极、消极和中立的分类,但也可能包含发言者的潜在情感(愉悦、生气、侮辱等)以及购买意图。
上下文会增加情感分析的复杂性。例如,感叹句“没什么!” 取决于发言者对产品是否喜欢所做出的评价,其含义可能截然不同。为了理解“我喜欢它”这个短语,机器必须能够理清上下文,并理解“它”指的是什么。讽刺和挖苦也具有挑战性,因为发言者可能会说一些积极的内容,但其表达的是相反的意思。
情感分析有多种类型。基于层面的情感分析将深入一个层次,以确定哪些特定特征或层面正在产生积极、中立或消极的情感。企业可以使用这种见解来找出产品中的缺点,或反之,找出产品中产生意外热情的特征。情感分析是一种变体,可试图确定演讲者围绕主题的情感强度。意图分析决定采取行动的可能性。
为什么要使用情感分析?
企业可以使用来自情感分析的见解来改进其产品、调优营销消息、纠正误解并确定积极的影响因素。
社交媒体革新了人们对于产品和服务的决策方式。在旅游、酒店和消费电子产品等市场中,现在人们通常认为客户评价至少与专业评论家的评估同样重要。TripAdvisor、Google 和 Yelp 上的 Amazon 评分和评价等来源可以切实决定产品的成败。博客、Twitter、Facebook 和 Instagram 等低结构性的渠道还可提供有关客户情感的有用见解,以及激发赞誉或谴责的产品特征和服务的反馈。
手动分析客户或潜在客户所生成的大量文本非常耗时。社交媒体、电子邮件、支持票证、聊天、产品评价和推荐的情感分析已成为几乎所有垂直行业中的重要资源。它非常有助于帮助企业获取见解、了解客户、预测和增强客户体验、定制营销活动,以及帮助决策制定。
情感分析用例
情感分析的示例用例包括以下内容:
产品设计师可使用情感分析,来确定哪些特征会与客户产生共鸣,因此这些功能值得额外投资和关注。反之,他们也可以了解产品或特征何时下降,并对其进行调整以防止库存进入折扣店。
营销组织在很大程度上依靠情感分析来调优消息、发现在线影响因素,以及构建积极的口碑。
零售组织挖掘情感以确定可能销售良好的产品,并相应地调整其库存和促销活动。
投资者可以识别在线对话中出现的新趋势,这些趋势可能预示着市场机遇。
政客可使用它对选民就重要问题的态度进行抽样。
情感分析的工作原理
| 机器学习特征工程
特征工程是将原始数据转换为机器学习算法输入的过程。为了在机器学习算法中应用该过程,必须将特征输入到特征向量中,而特征向量是代表每个特征值的数字向量。情感分析需要将文本数据输入到词向量中,这些词向量是代表每个单词值的数字向量。可以使用计数技术(如 Bag of Words (BoW)、bag-of-ngrams 或 Term Frequency/Inverse Document Frequency (TF-IDF))将输入文本编码为词向量。
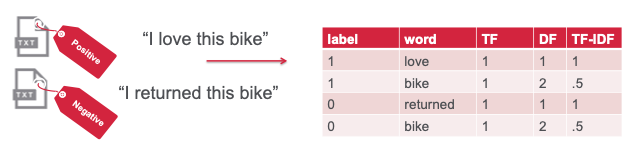
| 使用监督式机器学习进行情感分类。
将输入文本转换为词向量后,分类机器学习算法可用于情感分类。分类是一系列监督式机器学习算法,基于已标记的数据(例如标记为积极或消极的文本)来识别物品所属的类别(例如文本是消极还是积极)。
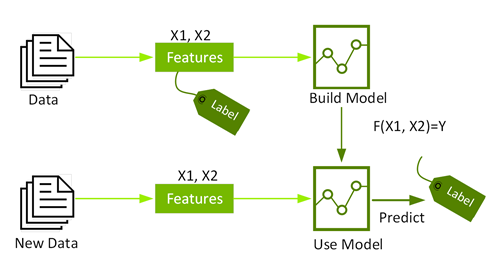
以下分类机器学习算法可用于情感分析:
Naïve Bayes 是一系列概率算法,用于确定输入数据类别的条件概率。
支持向量机在 N 维空间(N 为特征数)中查找对数据点进行明显分类的超平面。
逻辑回归使用逻辑函数对特定类别的概率进行建模。
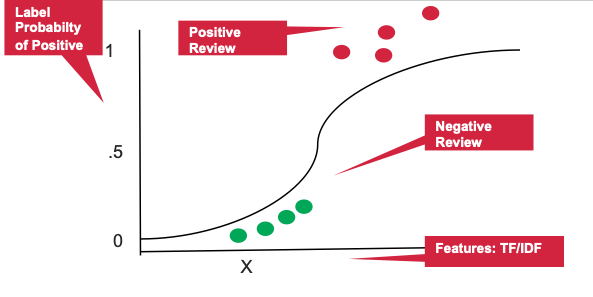
| 使用深度学习进行情感分析
深度学习 (DL) 是机器学习 (ML) 的一个分支,其使用多层人工神经网络精准完成 NLP 和其他任务。DL 词嵌入技术(例如 Word2Vec)通过学习词关联、含义、语义和语法,以有意义地对词进行编码。DL 算法还支持 NLP 模型的端到端训练,而无需手动从原始输入数据中设计特征。

深度学习算法有许多不同的变体。时间递归神经网络是解析语言模式和序列数据的数学工具。这些自然语言处理大脑,可为 Amazon Alexa 提供听力和语音,也可用于语言翻译、股票预测和算法交易。Transformer 深度学习模型,如 BERT (Bidirectional Encoder Representations from Transformers),是时间递归神经网络的一个替代方案,它应用了一种注意力技术 – 通过将注意力集中在前后最相关的词上来解析一个句子。BERT 通过在意图识别、情感分析等基准上提供与人类基准相媲美的准确性,彻底改变了 NLP 的进展。它具有深度双向的优势,相比于其他文本编码机制,它能够更好地理解和保留上下文。训练语言模型时,遭遇的一个关键挑战是缺少标记数据。BERT 在无监督任务上接受训练,通常使用书籍语料库、英语维基百科等的非结构化数据集。

GPU:加速 NLP 和情感分析
自然语言处理中近年来不断取得的进步和突破是驱动 NLP 增长的一个因素,其中重要的是部署 GPU 来处理日渐庞大且高度复杂的语言模型。
一个由数百个核心组成的 GPU,可以并行处理数千个线程。GPU 已成为训练 ML 和 DL 模型及执行推理的首选平台,因为它们的性能比纯 CPU 平台高 10 倍。

先进的深度学习神经网络可能有数百万乃至十亿以上的参数需要通过反向传播进行调整。此外,它们需要大量的训练数据才能实现较高的准确度,这意味着成千上万乃至数百万的输入样本必须同时进行向前和向后传输。由于神经网络由大量相同的神经元构建而成,因此本质上具有高度并行性。这种并行性会自然映射到 GPU,因此相比仅依赖 CPU 的训练,计算速度会大幅提高。因此,GPU 已成为训练基于神经网络的大型复杂系统的首选平台,推理运算的并行性质也有助于在 GPU 上执行。此外,像 BERT 这样基于 Transformer 的深度学习模型不需要按顺序处理连续数据,与 RNN 相比,可以在 GPU 上实现更多的并行化,并减少训练时间。
借助 NVIDIA GPU 和 CUDA-X AI™ 库,可快速训练和优化大量的先进语言模型,从而在几毫秒或几千分之一秒内运行推理。这是一项重大进步,可以结束快速 AI 模型与大型复杂 AI 模型之间的权衡。在与复杂语言模型协作时,NVIDIA GPU 的并行处理能力和 Tensor Core 架构可实现更高的吞吐量和可扩展性,从而为 BERT 的训练和推理提供优异的性能。
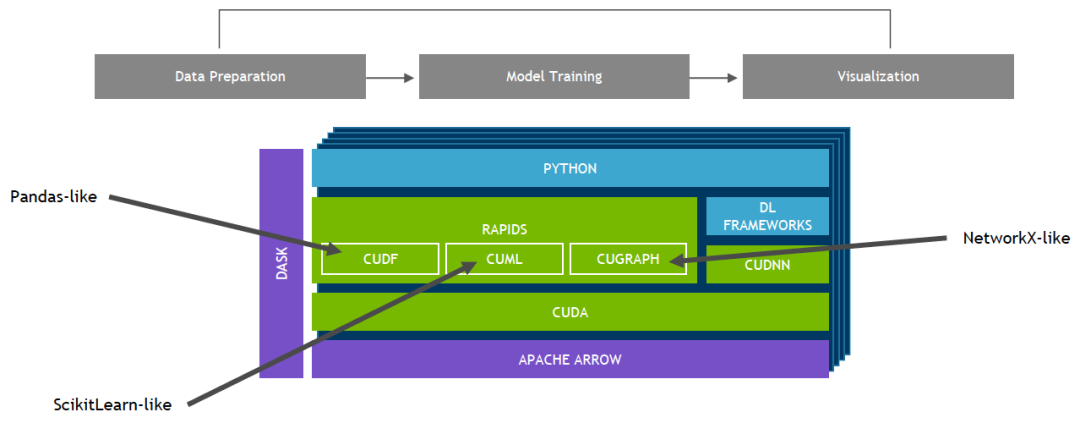
NVIDIA GPU 加速的端到端数据科学
基于 CUDA-X AI 构建的 NVIDIA RAPIDS™ 软件库套件使您能够自由地在 GPU 上执行端到端数据科学和分析流程。此套件依靠 NVIDIA® CUDA® 基元进行低级别计算优化,但通过用户友好型 Python 接口能够实现 GPU 并行化和高带宽显存速度。
NVIDIA GPU 加速的深度学习框架
GPU 加速 DL 框架为设计和训练自定义深度神经网络带来灵活性,并为 Python 和 C/C++ 等常用编程语言提供编程接口。MXNet、PyTorch、TensorFlow 等广泛使用的深度学习框架依赖于 NVIDIA GPU 加速库,能够提供高性能的多 GPU 加速训练。

后续步骤
NVIDIA 提供经过优化的软件堆栈,可加速深度学习工作流程的训练和推理阶段。如需详细了解相关信息,请访问 NVIDIA 深度学习主页。
开发者、研究人员和数据科学家可以通过深度学习示例轻松访问 NVIDIA 优化深度学习框架容器化,这些示例针对 NVIDIA GPU 进行了性能调整和测试。这能够消除对软件包和依赖项的管理需要,或根据源头构建深度学习框架的需要。请访问 NVIDIA NGC 了解详情并开始使用。
NVIDIA Volta™ 和 Turing™ GPU 上的 Tensor Core 专门为深度学习而设计,能够显著提高训练和推理性能。了解有关获取参考实现的更多内容。
NVIDIA 深度学习培训中心 (DLI) 能够为开发者、数据科学家和研究人员提供有关 AI 和加速计算的实战培训。











