
H100 Transformer 引擎大幅加速 AI 训练 性能提高达6倍
2022-03-30 20:42
#人工智能 #深度学习 #GTC22
 分享到微信
分享到微信
 分享到微博
分享到微博
在当今计算平台上,大型 AI 模型可能需要数月来完成训练。而这样的速度对于企业来说太慢了。
随着一些模型(例如大型语言模型)达到数万亿参数,AI、高性能计算和数据分析变得日益复杂。
NVIDIA Hopper 架构从头开始构建,凭借强大的算力和快速的内存来加速这些新一代 AI 工作负载,从而处理日益增长的网络和数据集。
Transformer 引擎是全新 Hopper 架构的一部分,将显著提升 AI 性能和功能,并助力在几天或几小时内训练大型模型。
使用 Transformer 引擎训练 AI 模型
Transformer 模型是当今广泛使用的语言模型(例如 asBERT 和 GPT-3)的支柱。Transformer 模型最初针对自然语言处理用例而开发,但因其通用性,现在逐步应用于计算机视觉、药物研发等领域。
与此同时,模型大小不断呈指数级增长,现在已达到数万亿个参数。由于计算量巨大,训练时间不得不延长到数月,而这样就无法满足业务需求。
Transformer 引擎采用 16 位浮点精度和新增的 8 位浮点数据格式,并整合先进的软件算法,将进一步提升 AI 性能和功能。
AI 训练依赖浮点数,浮点数是小数,例如 3.14。TensorFloat32 (TF32) 浮点格式是随 NVIDIA Ampere 架构而面世的,现已成为 TensorFlow 和 PyTorch 框架中的默认 32 位格式。
大多数 AI 浮点运算采用 16 位“半”精度 (FP16)、32 位“单”精度 (FP32),以及面向专业运算的 64 位“双”精度 (FP64)。Transformer 引擎将运算缩短为 8 位,能以更快的速度训练更大的网络。
与 Hopper 架构中的其他新功能(例如,在节点之间提供直接高速互连的 NVLink Switch 系统)结合使用时,H100 加速服务器集群能够训练庞大网络,而这些网络此前几乎无法以企业所需的速度进行训练。
更深入地研究 Transformer 引擎
Transformer 引擎采用软件和自定义 NVIDIA Hopper Tensor Core 技术,该技术旨在加速训练基于常见 AI 模型构建模块(即 Transformer)构建的模型。这些 Tensor Core 能够应用 FP8 和 FP16 混合精度,以大幅加速 Transformer 模型的 AI 计算。采用 FP8 的 Tensor Core 运算在吞吐量方面是 16 位运算的两倍。
模型面临的挑战是智能管理精度以保持准确性,同时获得更小、更快数值格式所能实现的性能。Transformer 引擎利用定制的、经NVIDIA调优的启发式算法来解决上述挑战,该算法可在 FP8 与 FP16 计算之间动态选择,并自动处理每层中这些精度之间的重新投射和缩放。

Transformer Engine 使用每层统计分析来确定模型每一层的最佳精度(FP16 或 FP8),在保持模型精度的同时实现最佳性能。
与上一代 TF32、FP64、FP16 和 INT8 精度相比,NVIDIA Hopper 架构还将每秒浮点运算次数提高了三倍,从而在第四代 Tensor Core 的基础上实现了进一步提升。Hopper Tensor Core 与 Transformer 引擎和第四代 NVLink 相结合,可使 HPC 和 AI 工作负载的加速实现数量级提升。
加速 Transformer 引擎
AI 领域的大部分前沿工作都围绕 Megatron 530B 等大型语言模型展开。下图显示了近年来模型大小的增长趋势,业界普遍认为这一趋势将持续发展。许多研究人员已经在研究用于自然语言理解和其他应用的超万亿参数模型,这表明对 AI 计算能力的需求有增无减。
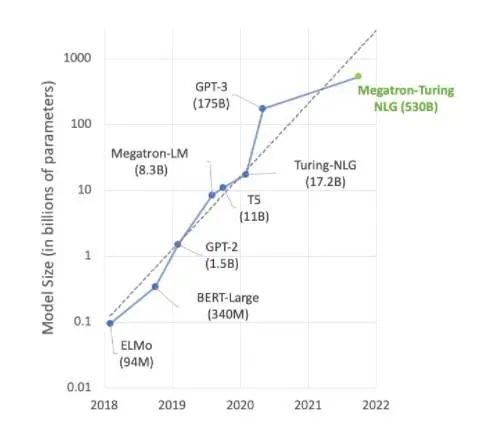
自然语言理解模型仍在快速增长。
为满足这些持续增长的模型的需求,高算力和大量高速内存缺一不可。NVIDIA H100 Tensor Core GPU 两者兼备,再加上 Transformer 引擎实现的加速,可助力 AI 训练更上一层楼。
通过上述方面的创新,就能够提高吞吐量,将训练时间缩短 9 倍——从 7 天缩短到仅 20 个小时:
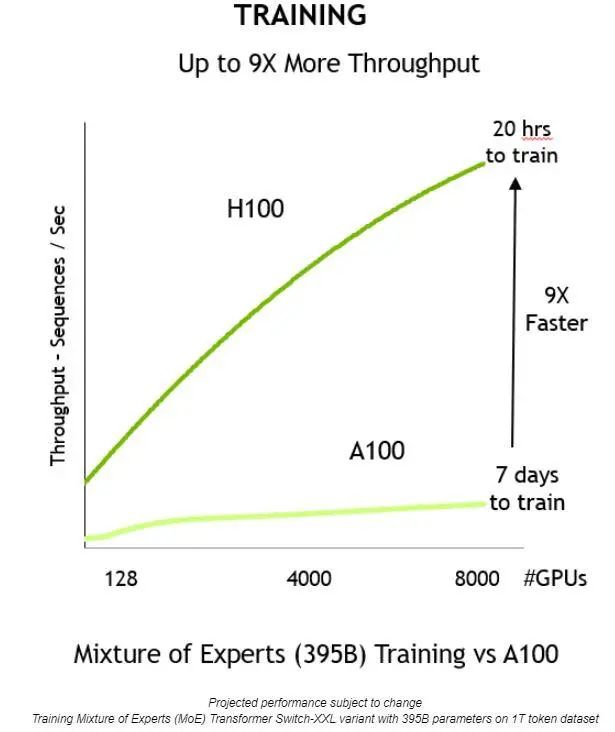
与上一代相比,NVIDIA H100 Tensor Core GPU 提供 9 倍的训练吞吐量,从而可在合理的时间内训练大型模型。
Transformer 引擎还可用于推理,无需进行任何数据格式转换。以前,INT8 是实现出色推理性能的首选精度。但是,它要求经训练的网络转换为 INT8,这是优化流程的一部分,而 NVIDIA TensorRT 推理优化器可轻松实现这一点。
使用以 FP8 精度训练的模型时,开发者可以完全跳过此转换步骤,并使用相同的精度执行推理操作。与 INT8 格式的网络一样,使用 Transformer 引擎的部署能以更小的内存占用空间运行。
在 Megatron 530B 上,NVIDIA H100 的每 GPU 推理吞吐量比 NVIDIA A100 高 30 倍,响应延迟为 1 秒,这表明它是适用于 AI 部署的上佳平台:
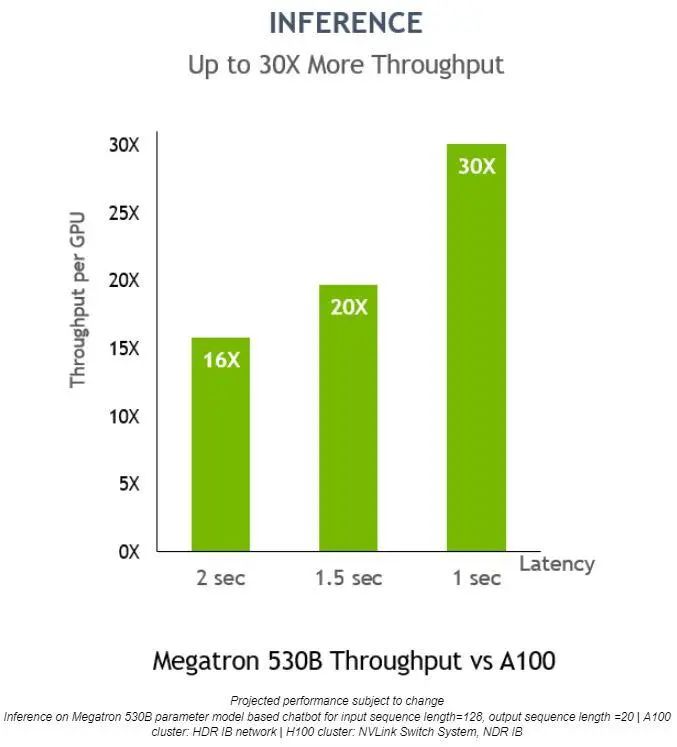
对于低延迟应用,Transformer 引擎还可将推理吞吐量提高 30 倍。











