
使用 Magnum IO 加速云原生超级计算
2021-11-22 20:28
 分享到微信
分享到微信
 分享到微博
分享到微博
超级计算机是一项重要的投资,对于研究人员和科学家来说,它们是必不可少的宝贵工具。为了有效和安全地共享这些数据中心的计算能力, NVIDIA 引入了云原生超级计算架构。它结合了裸机性能、多租户和性能隔离统一为超级计算服务。
Magnum IO 是数据中心的 I / O 子系统,它引入了新的增强功能,以加速多租户数据中心的 I / O 和通信。我们将这些增强功能称为 Magnum IO ,用于云原生超级计算架构。
它由 NVIDIA Quantum-2 InfiniBand 平台提供,该平台包括 NVIDIA Quantum-2 交换机系列、BlueField-3 DPU 和 ConnectX-7 网卡。
这种进化环境的挑战是什么?
基于 GPU 的高性能计算已经通过机器学习和模拟计算大幅改变了科学和实验。在GPU 上运行的这些深度学习框架和模拟工具可能会消耗 PB 级的数据,并在整个数据中心内造成拥塞和瓶颈。更复杂的是,这些应用程序的多个实例在共享的超级计算设施上常常同时运行并互相影响,因而造成运行性能的抖动,从而导致无法预测的运行时间。
面向云原生超级计算体系结构设计的 Magnum IO 带来新的增强功能,以减轻最终用户在多租户环境中运行应用带来的性能负面影响。它提供确定性的性能,就好像它们的应用程序是独占网络运行。
第三代 NVIDIA SHARP
(可扩展分层聚合和规约协议)
通过将集合操作从主机 CPU 卸载到交换机网络,SHARP 技术有效消除了端点之间多次发送数据的需求,从而提高了 MPI 操作的性能。这种方法大幅减少了到达聚合节点的网络流量,并显著减少了 MPI 操作时间。
在网络中实现集合通信算法还有其他好处,例如释放宝贵的 CPU 资源用于计算,而不是使用它们来处理通信。
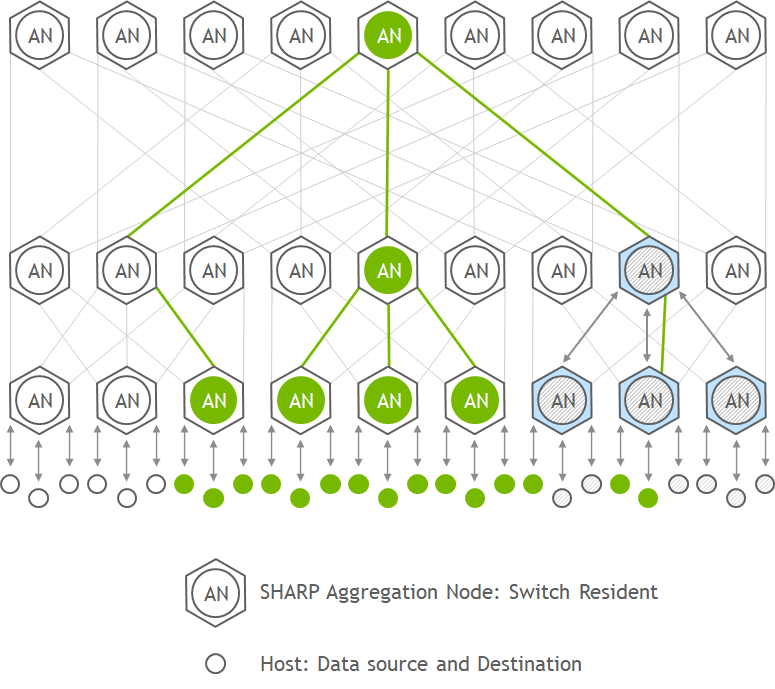
图 1 NVIDIA SHARP 聚合通信架构框图
最近发布的 NVIDIA Quantum-2 InfiniBand 交换机为大型数据聚合提供了强大的可扩展性。由于每个交换机支持几乎无限的小消息聚合和多个大消息聚合流,在共享系统上运行多租户应用程序可以充分利用 SHARP 的优势。
性能隔离
多租户超级计算实现在共享资源上运行很多用户的应用程序,可能造成物理服务器、存储、网络以及I / O流量模型的复用 。
NVIDIA Quantum InfiniBand 一直以来支持拥塞控制管理,当检测到网络拥塞时在源端实施控制以缓解拥塞。但在多租户场景,用户应用可能无意识地与相邻用户流量产生干扰,因此需要隔离以提供可预期的性能级别。
借助最新的 NVIDIA Quantum-2 InfiniBand 平台和 Magnum IO ,创新的主动监控和拥塞管理提供了良好的流量隔离。这几乎完全消除了性能抖动,并确保了预期的性能,就像应用程序运行在专用系统上一样。
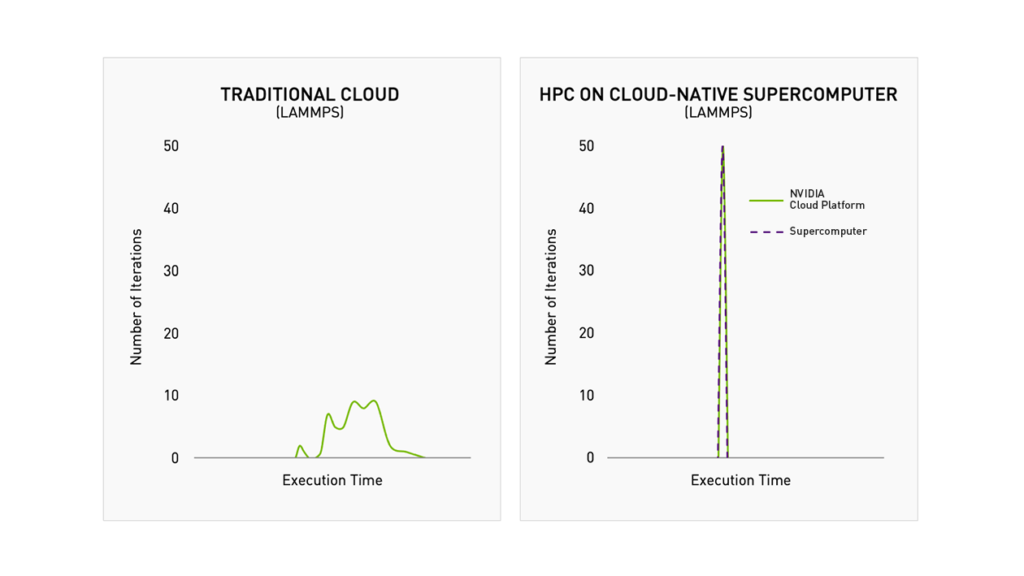
图 2 性能隔离的好处
专为安全、多租户、裸机性能而打造
NVIDIA Cloud-Native Supercomputing 体系结构使用 Magnum IO 在多租户环境中实现最高的性能、安全性和编排。
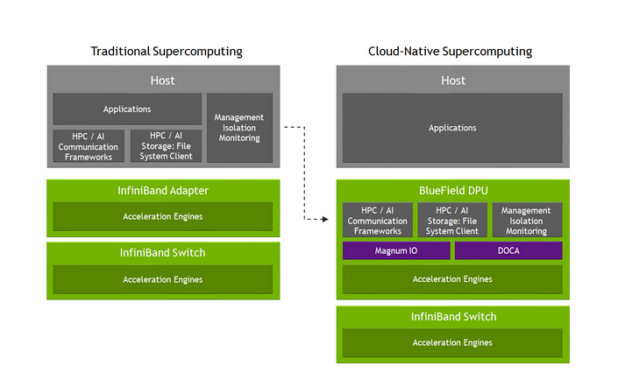
图 3 使用 DPU 迁移到云原生超级计算体系结构.
此外,实现这种架构转换的另一个核心元素是数据处理器( DPU ),也即 BlueField 。作为一个完全集成的片上数据中心平台, BlueField 从主机处理器卸载和管理数据中心基础设施,实现超级计算机的安全和编排。
它还能够提供额外的通信框架卸载,可达到 100% 的通信计算重叠,实现 MPI _ Alltoall 44% 的性能提升和 MPI _ iAllgather 36% 的性能提升。当结合最新的 NVIDIA Quantum-2 平台时,该体系结构在安全的多节点体系结构中展示性能隔离实现裸金属性能。
Magnum IO 消除了 I / O 瓶颈,拓展了硬件级加速引擎、网络计算和拥塞控制等最新技术,成为支持当今高性能裸金属多租户数据中心的必备利器。











