GTC21 | NVIDIA 借助超大规模 AI 语言模型为全球企业赋能
2021-11-11 12:20
#人工智能 #深度学习 #GTC21
 分享到微信
分享到微信
 分享到微博
分享到微博
NVIDIA NeMo Megatron 框架; 可定制的大规模语言模型Megatron 530B;多GPU、多节点 Triton推理服务器助力基于语言的AI开发和部署,推动行业和科学发展
NVIDIA今日为全球企业开发和部署大型语言模型打开了一扇新的大门——使这些企业能够建立他们自己的、特定领域的聊天机器人、个人助理和其他AI应用程序,并能够以前所未有的水平理解语言中的微妙和细微差别。
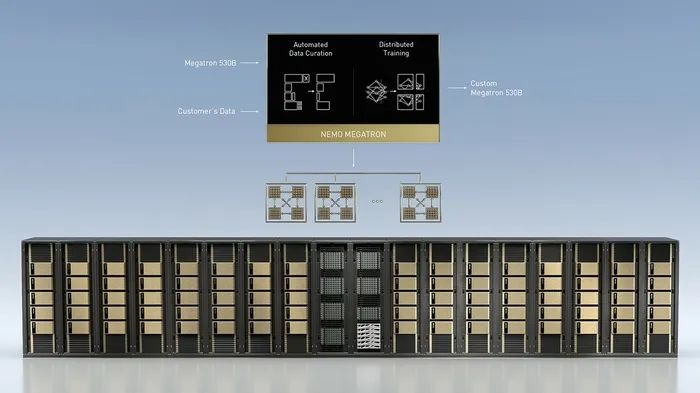
NVIDIA推出了为训练具有数万亿参数的语言模型而优化的NVIDIA NeMo Megatron框架、为新领域和语言进行训练的可定制大型语言模型(LLM)Megatron 530B以及具有多GPU、多节点分布式推理功能的NVIDIA Triton推理服务器。
这些工具与NVIDIA DGX系统相结合,提供了一个可部署到实际生产环境的企业级解决方案,以简化大型语言模型的开发和部署。
"大型语言模型已被证明是灵活且功能强大的,无需专门的培训或监督,即可回答深层次领域问题,翻译语言,理解和总结文件,编写故事和计算程序。" NVIDIA应用深度学习研究副总裁Bryan Catanzaro表示。" 为新的语言和领域建立大型语言模型可能仍然是最大的超级计算的应用,现在这些功能对全球的企业也变得触手可及。"
NVIDIA NeMo Megatron和Megatron 530B
加速大型语言模型开发
NVIDIA NeMo Megatron是在Megatron的基础上发展起来的开源项目,由NVIDIA研究人员主导,研究大型转换语言模型的高效训练。Megatron 530B是世界上最大的可定制语言模型。
NeMo Megatron框架使企业能够克服训练复杂自然语言处理模型的挑战。经过优化,可以在NVIDIA DGX SuperPOD的大规模加速计算基础设施上进行扩展。
NeMo Megatron通过数据处理库自动处理LLM训练的复杂性,这些数据处理库可以摄入、策划、组织和清理数据。利用先进的数据、张量和管道并行化技术,它能使大型语言模型的训练有效地分布在成千上万的GPU上。企业可以通过NeMo Megatron框架进一步训练它以服务新的领域和语言。
NVIDIA Triton推理服务器
助力实时大型语言模型推理
此外,今日发布的最新NVIDIA Triton推理服务器中的多GPU、多节点特性,使大型语言模型推理工作负载能够实时在多个GPU和节点上扩展。这些模型需要的内存比单个GPU甚至是包含多个GPU的大型服务器所能提供的还要多,并且,实际应用对其推理实时性有着极高的要求。
通过Triton推理服务器,Megatron530B能够在两个NVIDIA DGX系统上运行,将处理时间从CPU服务器上的1分钟以上缩短到半秒,令实时应用部署大型语言模型成为可能。
使用NVIDIA DGX SuperPOD构建大型复杂语言模型的早期客户包括SiDi、京东探索研究院和VinBrai。
SiDi是巴西的一家大型AI 研究和开发机构,已经采用三星虚拟助手,供全国 2 亿巴西葡萄牙语者使用。
SiDi 首席执行官John Yi 表示:“SiDi 团队在AI 虚拟助理和聊天机器人开发方面拥有丰富的经验,此类开发既需要强大的 AI 性能,也需要经过训练并适应人类语言不断变化的细微差别的专用软件。NVIDIA DGX SuperPOD 非常适合推动我们团队的先进工作,帮助我们为巴西的葡萄牙语者提供领先的AI 服务。”
京东探索研究院,是以供应链为基础的领先技术和服务提供商京东的研发部门,他们利用 NVIDIA DGX SuperPOD 开发NLP,应用于智能客户服务、智能零售、智能物流、物联网、医疗健康等领域。
VinBrain,越南的医疗健康 AI 公司,他们使用 DGX SuperPOD 为100 家医院的放射科医生和远程医疗医生开发和部署了一种临床语言模型。在这些医院,已有 600 多名医疗健康从业者使用该模型。
企业可以利用今天同期发布的NVIDIA LaunchPad,免费体验开发和部署大型语言模型。行业组织可以申请加入抢先体验计划,了解用于训练大规模语言模型的 NVIDIA NeMo Megatron 加速框架。
NVIDIA Triton可从NVIDIA NGC目录中获得,该目录是GPU优化的AI软件中心,包括框架、工具包、预训练模型和Jupyter Notebooks,并可从Triton GitHub repository中获取开放源代码。
Triton也包含在NVIDIA AI Enterprise软件套件中,该套件由NVIDIA优化、认证和支持。企业可以使用该软件套件,在内部数据中心和私有云的主流加速服务器上运行语言模型推理。
NVIDIA DGX SuperPOD 和NVIDIA DGX 系统通过NVIDIA 的全球经销商提供,这些合作伙伴能够根据要求为符合条件的客户提供询价服务。
分享到微信
分享到微博