白皮书发布:DOCA 简化 DPU 采用,为数据中心部署加速
2021-08-06 14:03
 分享到微信
分享到微信
 分享到微博
分享到微博
“ NVIDIA 希望通过 DOCA 为 DPU 编程提供更高级别的抽象化,从而消除应用开发者采用 DPU 需要自定义底层代码的障碍。通过提供运行时二进制文件和上层 API,DOCA 框架使开发者能够专注于应用代码开发,而无需了解 DPU 硬件的错综复杂之处。尽管 Arm 服务器在早期就被应用于公有云,但许多应用开发者都有一个庞大的 x86 代码库,且尚未为 Arm 移植做好准备。NVIDIA 适用于 x86 的 DOCA Runtime 可为这些客户消除 Arm 移植障碍,使其现在就能够采用 DPU,并在以后进行优化。”
- The Linley Group 首席分析师
Bob Wheeler
半导体行业领先的分析机构 The Linley Group 近日发布了 DOCA 白皮书《DPU 硬件加速之路:软件视角》,从技术角度深入解析了 NVIDIA DOCA 的特点与应用,以及 DOCA 将如何帮助客户简化 DPU 的采用。以下部分内容与观点摘自白皮书。
DPU + GPU 融合之路
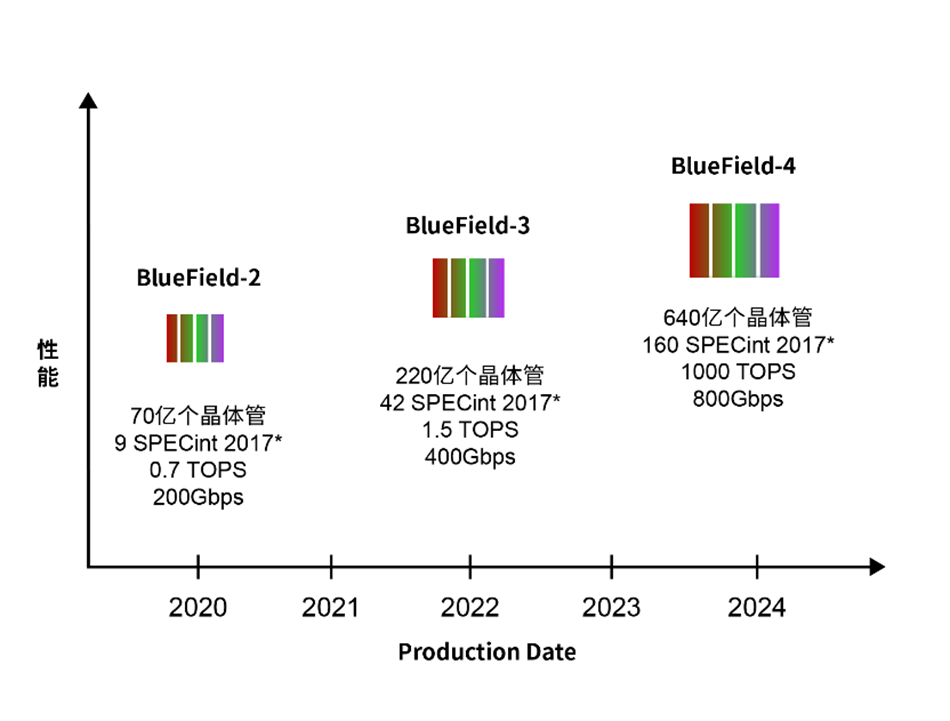
The Linley Group 将 DPU 定义为集成了从网络端口到 PCI Express(PCIe)接口所有主要功能的可编程网络系统级芯片(SoC)。NVIDIA 于 2020 年进入 DPU 领域并推出了 BlueField 系列产品,已发售的 BlueField-2 可用作智能网卡和存储控制器,集成了高达 200Gbps 的以太网端口和高带宽的 PCIe 接口。而 BlueField-3 将于 2022 年上市,BlueField-4 的路线图也已然明晰。
BlueField DPU 路线图:相比前代产品,BlueField-3 将扩展通用计算和网络性能,而 BlueField-4 还将增加一个用于 AI 加速的 GPU。*SPECrate 2017 Integer
BlueField-2 和 BlueField-3 依靠其 Arm 核进行 AI 处理,而 BlueField-4 将集成一个用于 AI 加速的 GPU。这将使该芯片的 AI 性能与 NVIDIA 的 A100 等顶尖加速器处于同一级别。同时,NVIDIA 计划在 BlueField-3X 卡采用双芯片的方案,增加一个 75 TOPS 的加速器,在一个 PCIe 槽位上实现了 DPU+GPU 的集成解决方案。随着开发者在网络安全、软件定义网络、云编排和其它应用中添加 AI 功能,可以采用这种 NVIDIA 的 DPU+GPU 硬件和软件来加速AI和网络处理。
BlueField 提供硬件加速
不同于服务器处理器,DPU 专为网络包处理而设计。虽然架构不同,但大多数都包含可编程数据平面,以及用于控制平面和应用代码的 CPU 核。DPU 专用数据路径不仅比使用 CPU 核更高效,而且性能也远高于后者。
如下图所示,BlueField 架构本质上是将网卡子系统(基于 ConnectX)与可编程数据路径、用于加密、压缩和正则表达式的硬件加速器以及用于控制平面的 Arm控制器融为一体。在 BlueField-3 中,可编程包处理器包含 16 个核可处理 256 个线程,实现了 Arm 核上的零负载数据路径处理。在许多应用中,由数据路径自主处理已知的网络流量,由 Arm 核处理新流量等例外情况及控制平面功能。
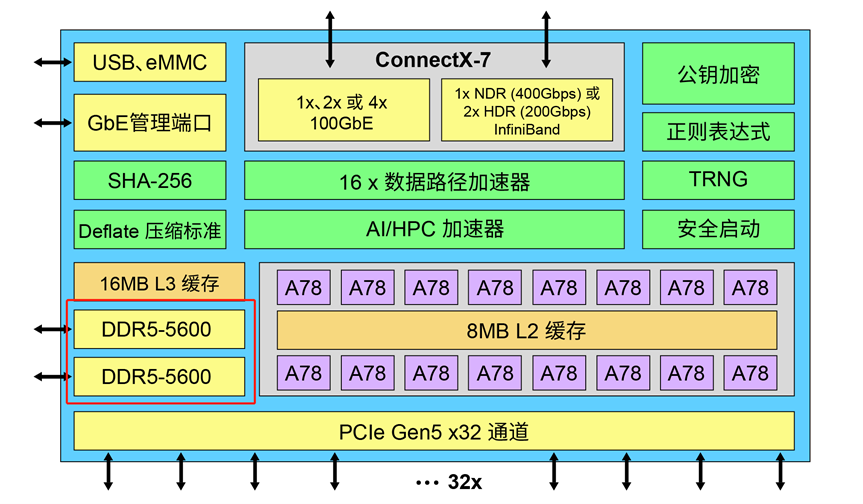
BlueField-3 DPU:可编程数据路径与硬件加速单元相结合,实现了线速处理,且无需访问 Arm 控制器
在网络方面,DPU 可以加速先进的数据中心 SDN 和网络功能虚拟化(NFV),包括 Open vSwitch、Overlay 协议(如VXLAN)、网络地址转换(NAT)、负载均衡和精细化流量管理。在存储方面,DPU 可加速 RoCE(RDMA)、NVMe-oF、静态数据加密、数据去重、分布式纠错和数据压缩。
DOCA 简化 DPU 的应用
The Linley Group 在白皮书中表示,尽管 DPU 具备显著的优点,但要求用户编写底层代码,这限制了其早期应用仅限于一小群用户。为了使 ISV、服务提供商和学术界能够采用 DPU,NVIDIA 开发了 DOCA(Data Center On A Chip Architecture)。
DOCA 是一个由库文件、运行时组件和服务组成的框架,建立在一套经过验证的驱动程序之上。其中的一些库与开源项目有关,而另一些则是 NVIDIA 独有的。与 CUDA 实现 GPU 编程的抽象化一样,DOCA 实现了更高级别的 DPU 编程抽象化。
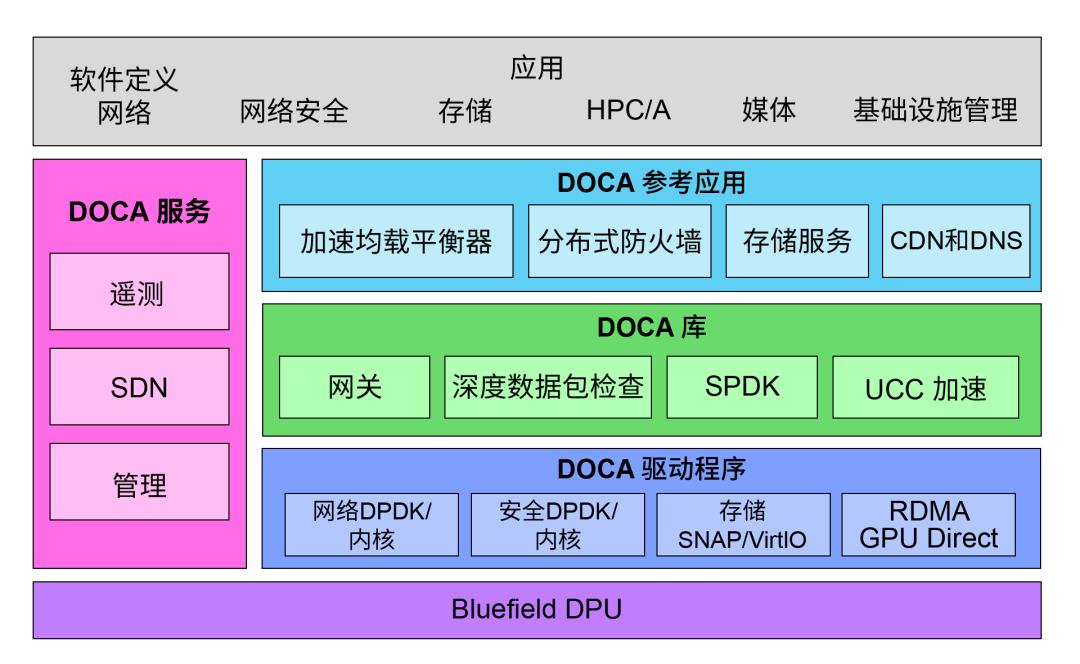
DOCA 1.1软件栈:DOCA 库为应用开发者提供上层 API,从而无需底层编程
如上图所示,DOCA 1.1 软件栈包括驱动程序、库、服务代理和参考应用。NVIDIA 提供的软件栈包含两部分内容,一部分是面向开发者的 DOCA SDK,另一部分是用于实现开箱即用部署的 DOCA Runtime 软件。
从软件栈上部看,流量网关库能够实现一个建立在数据路径 SFT 上的硬件加速网关,为过滤和分发网络流量的网关应用提供了更高级别的抽象化。在存储方面,DOCA 支持用户态库开源 SPDK。在 HPC 和 AI 方面,DOCA 初期加入了作为运行时组件的统一集合通信(UCC)库,在未来版本中还将加入 SDK 支持。
DOCA 用例分享
一个早期的 DPU 在网络上的用例是卸载服务器 CPU 上的虚拟交换功能。根据红帽的测试结果,相较用 8 个 CPU 核来运行 OVS,使用 BlueField DPU 加速 OVS 使性能提高了 53 倍。
另一个应用是将 DPU 作为一个 Lookaside 加速器并使用它来卸载数据路径。Palo Alto Networks 将基于 DPU 的卸载添加到了其 VM 系列 NGFW 中,同时将应用保留在 x86 主机上,观察到吞吐量提升了 4-6 倍,实现对于 100G 以太网支持。
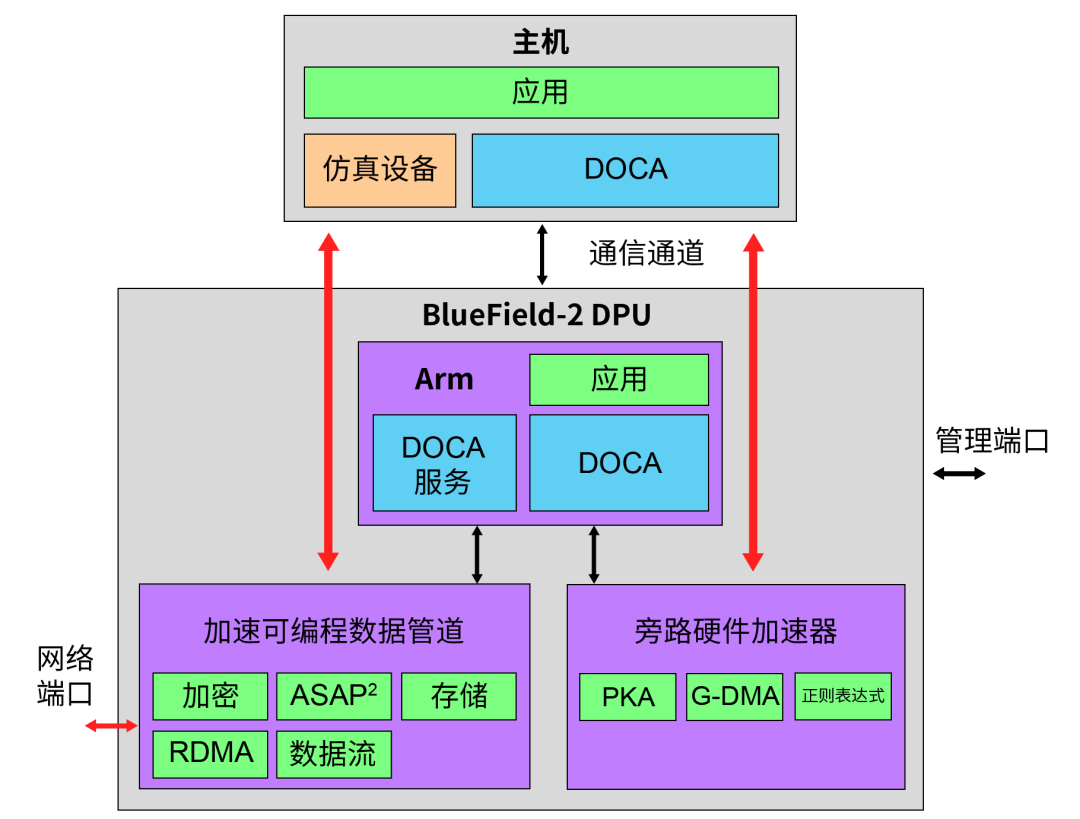
DPU 卸载应用实例:通过 DOCA,在主机上运行的基于 x86 的应用和在 DPU 上运行的基于 Arm 的应用都可以访问加速数据路径和 Lookaside 加速器
另一个网络安全示例是 NVIDIA 的 Morpheus AI 框架。该框架使用自然语言处理(NLP)模型来识别数据泄露。虽然该框架在 GPU 加速的服务器上运行,但它使用 BlueField DPU 分布到整个网络作为传感器。DPU 向 Morpheus 服务器发送实时遥测数据,该框架可通过向 DPU 推送安全策略来应对威胁。通过在每台服务器中放置一个 DPU,客户可实现与服务器操作系统隔离的微分段安全并且不会增加服务器 CPU 负载。
正如 CUDA 支持向后和向前兼容各代 GPU 一样,DOCA 使开发者现在就能开始使用目前的 BlueField-2 DPU,并且知道其代码将能够在即将发布的 BlueField-3 上无缝运行。同样,开发者现在已经采用了 NVIDIA GPU,例如 A100 PCIe 卡,这些代码已经知道可以在将来的 BlueField-4 上运行。NVIDIA 的愿景是让 DPU 继 CPU 和 GPU 之后成为异构计算的第三大支柱。而 DOCA 是在各种应用中实现这一愿景的关键。
以上内容与图片均摘自白皮书《DPU 硬件加速之路:软件视角》
白皮书作者 Bob Wheeler 是 The Linley Group 首席分析师兼《微处理器报告》高级编辑。The Linley Group 专注于全面的微处理器和系统级芯片设计分析,包括商业战略及内部技术。白皮书《DPU 硬件加速之路:软件视角》深度探析 DOCA 如何简化 DPU 的应用以提高数据中心效率,同时讲述了一些典型的 DOCA 用例。











