Jetson Nano 2GB 文章(25): Hello AI World图像分类的模型训练
2021-06-18 18:12
 分享到微信
分享到微信
 分享到微博
分享到微博
前面的所有内容与实验,全部都是关于“推理识别(inference)”的部分,主要是为了让用户先体会到“最终结果”,包括需要花费的精力、以及最后得到的效率。由于项目提供非常多的预训练模型文件,因此我们可以很轻松地调用这些资源,去进行推理计算,并且得到相当惊人的性能。
然而,真正要完成一个深度学习的项目,还是必须完成前面阶段的模型训练部分,本文的重点就是带着大家,利用 Hello AI World 所提供的资源,开始进行简单的图像分类应用的模型训练。
所有深度学习的模型训练,都必须具备以下的几个元素,缺一不可:
1. 数据集(dataset):
事实上数据集的质量,直接关系到训练出来的模型质量,就如同做菜一样,如果食材不够好,再厉害的厨师也没办法做出真正的好菜。
数据集的来源主要有三个:
网上已有的开源资源:包括ImageNet、MS COCO、OpenImages 等等,都是数量级在百万张图片以上的数据集,而且分类十分清楚,是个非常重要的资源,必须学会如何从这些数据集中,萃取自己所需要的的数据。
自行收集:通过在网上根据关键字去搜索下载,也可以利用自己的摄像设备去拍摄收集。
自行转换:可以将已有的图像数据,经过灰度处理、镜像映射等方式,再生成 2x~4x 数据量。
2. 深度神经网络模型(算法):
这个部分是深度学习的精髓,目前在几个主流神经网络模型之间,很难去评孰优孰劣,就像大餐厅的名厨一样,各有侧重点与风格。在这里,为了要能在 Jetson 设备上进行训练,因此我们挑选 ResNet-18 这个网络。
3. 框架(framework)工具:
这个就是作为深度学习的模型训练与推理识别的很重要工具,目前最主流的应该是 Tensorflow,不过这里为了配合迁移学习(transfer learning)的特性,因此选择用 pytorch 这个轻量级的框架工具
4. 训练用的设备:
事实上训练用的设备,会直接影响到网络模型与框架工具的选择。这里我们使用 NVIDIA Jetson 系列设备进行训练,就必须选择轻量级的网络模型与框架工具。
现在就开始我们的图像分类模型训练实验,在开始实验之前,还是有以下几个准备动作需要确认:
1. 是否已经安装好 pytorch 这个工具?如果前面没有装好,现在还可以执行以下指令进行安装:

2. 是否为系统添加 SWAP 空间?如果是正常用 Jetack 4.4 以上版本的话,都应该已经设定好 SWAP 空间,如果确认未设定 SWAP 的话,请执行以下指令:

3. 关闭 jetson 设备的图像桌面,可以腾出更多内存,有利于训练作业。

接下来就正式进入模型训练的环节,项目作者已经为我们提供基于 pytorch 的图像分类的 Python 训练代码,为了便于操作,先将工作目录移到代码的位置:

里面的 train.py 与 onnx_export.py 是这个训练过程会用到的两只程序,至于代码内容则不作说明。
接下去的任务就是获取数据集。项目作者提供了两个现成的数据集 “cat_dog” 与 “PlantCLEF_Subset”,除了数据集本身的内容(含类别)不一样之外,其余操作过程是完全一样的,因此这里我们只演示 “cat_dog” 这个数据集的完整过程,将 “PlantCLEF_Subset” 的实验留给读者去比照办理。
为了保持指令参数的一致性,建议将数据下载到 data 目录下,并且将生成的模型文件制定到 models 路径,现在就开始执行完整的步骤:

检查看看 cat_dog 与 PlantCLEF_Subset 下面,是否都存在
在 cat_dog 下面的 test、train、val 目录下,应该都有 cat 与 dog 子目录,这个子目录名称会与 labels.txt 内容对应上。根据这样的原则,请检视一下 PlantCLEF_Subset 数据集,是否也具备相同的特性?这里应该有 20 种植物名称分类。
接下去回到 train.py 与 onnx_export.py 工作目录下,准备开始执行模型训练任务:

由于训练程序使用了迁移学习的技巧,因此在第一次开始训练之前,会先下载合适的预训练模型,然后让这些数据在这个模型基础上进行叠加训练,一方面提高精准度,另一方面也会减少训练时间,这就是“迁移学习”的迷人之处。

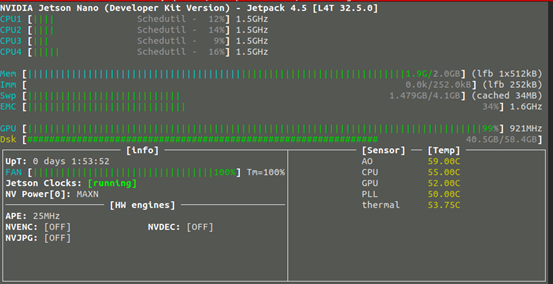
系统预设使用 resnet-18 这个网络,这是比较适合 Jetson Nano(含2GB)的轻量级模型,我们也可以使用 --arch= 去指定使用其他网络模型。如果这时候打开 jetson-stats 监控工具,可以看到 GPU 持续处于满载状态。
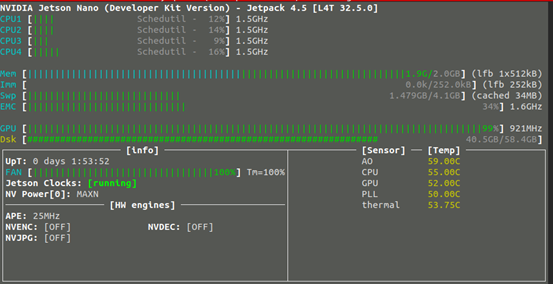
这个 cat_dog 数据集共有 6200 张图片,其中训练集 5,000 张、验证集 1,000 张、测试集 200 张,系统预设的 epoch 数为 35,可使用--epoch=去改变 epoch 数。epoch 数量设为多少比较合适?这个没有一定的答案,我们需要观察训练过程中 Loss 值的变化。
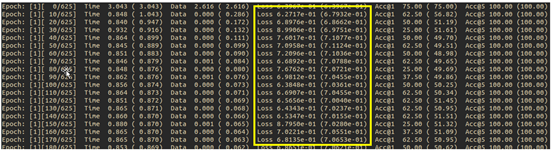
如此的数据量在 Jetson Nano 2GB 上的训练时间,总共花了 285 分钟(4 小时 45 分钟)

现在训练完成之后,下一步就是要把这个训练的模型,使用 onnx_import.py 将 pytorch 模型文件转换成 ONNX 格式,以便在后面使用时很轻松地转换成 TensorRT 加速引擎。

会在 models/cat_dog 目录下生成 “resnet18.onnx” 文件,最后以这个文件为基础,调用前面所熟悉的 imagenet 图像分类指令,来进行推理计算任务,请执行以下代码:

现在使用自己训练的模型来执行 imagenet.py,因此需要个别给定--model、--labels 的路径,以及--input_blob、--output_blob 的内容,其他部分与前面讲解过的用法是一致的,可以用视频、摄像头、文件夹作为输入源,检测一下识别的效果如何?
请自行尝试 PlantCLEF_Subset 这个关于植物类别的数据集,按照上面完全一样的做法,自行走过一遍,这会让你更加熟悉与掌握整个“图像分类”的应用,从数据集收集、模型训练,到推理识别这三个阶段。
最后,如果您需要建立自己专属的数据集的话,这个 Hello AI World 项目还提供一个 camera-capture 这个现场抓图的工具,开启之后会出现一个控制面板(如下图左),可选择 Classification 或 Detection 功能,同时还会启动一个摄像头画面市场(如下图右),可以自行调整所需要的的分类与指定路径。
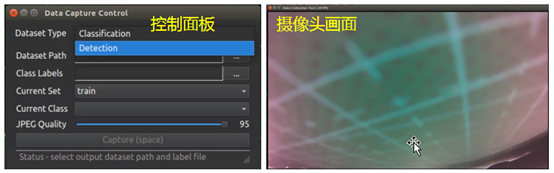
收集完足够的图像数据之后,再按照前面的步骤进行模型训练,就能建立自己专属的模型文件,给自己的 Jetson 设备进行图像分类的推理识别应用。











