
NVIDIA Jetson Nano 2GB 系列文章(12):人脸定位
2021-03-17 20:21
 分享到微信
分享到微信
 分享到微博
分享到微博
在本系列上一篇文章中,我们带领大家了解了 OpenCV。在本篇文章中,我们将带领大家利用 Jetson Nano 2GB 制作一个简单的人脸识别打卡机。
事实上,这是个入门级的 AI 应用,完全利用 Jetson Nano 2GB 上提供的 OpenCV 库与 Python3 开发环境,就能实现人脸身份识别,达到打卡的功能。除了可以用在办公环境,还可以作为老师上课时的点名系统,实用性非常高。
本项目利用 face_recognition 这个目前最容易上手的 Python 人脸识别库,这是基于知名的 dlib 机器学习开源算法库进行二次开发的接口,调用方式比原生 dlib 更加简单,因此本项目就是以 face_recognition 这个人脸识别库为主。
本项目第一部分,就是带着大家用 face_recognition 库里的 face_locations() 函数,轻松实现“人脸定位”的功能。要知道“定位”是“身份识别”的前提要素,必须先确认人脸的位置(location)之后,才能进一步执行比对。
接下来就开始本项目的内容。
安装 face_recognition 库
这里只需要执行 Python 版本,因此安装 face_recognition 库非常简单,只需执行以下一道指令,Python 的 pip3 就会将其他所需要的依赖库一并安装,包括 dlib、pillow、click、numpy 等,十分方便。

安装的时间会比较久,大概需要 30 分钟左右,安装过程会将 face_recognition 所依赖的 dlib、pillow、click、numpy 等库一并安装,安装好之后,就可以直接调用。
整个 face_recognition 库只有 7 个 API 接口,功能如下:
load_image_file:将img文件加载到numpy 数组中
face_locations:查找图像中所有面部和所有面部特征的位置
batch_face_locations:批次人脸定位函数(GPU)
face_landmarks:人脸特征提取函数
face_encodings:图像编码转为特征向量
compare_faces:特征向量比对
face_distance:计算特征向量差值
详细的使用说明,请访问以下官网进一步查看:
https://face-recognition.readthedocs.io/en/latest/face_recognition.html
用照片与视频准备识别
本处为避免牵涉到个人肖像权问题,因此以 NVIDIA GAN 对抗网络技术的 YouTube 公开宣传视频(https://www.youtube.com/watch?v=kSLJriaOumA)
为基础,提取部分视频与照片来作为本实验的测试数据。以下照片全部为 NVIDIA GAN 技术合成人像,如有雷同,纯属巧合。

接下来看看 face_recognition 能做什么事情?
图像中的人脸定位(location)
Face_recognition 第一个最基本功能,就是能自行找到人脸的位置(location),下面的代码可在任何一张带有人脸的图像中,找出每张人脸的位置。Face_recognition 库里提供以下两个函数来处理本次任务,以下简单说明代码原理:
face_recognition.load_image_file:读入图像文件。
face_recognition.face_locations:直接找出图像内(多张)人脸的位置。
由于读入的图像颜色空间为 RGB 格式,需要用 cv2.cvtColor 转换成 BGR 格式。
然后将 face_location 找出的位置,用 cv2.rectangle 将框全部画到原图上。
最后用 cv2.imshow 显示结果。
完整代码如下:

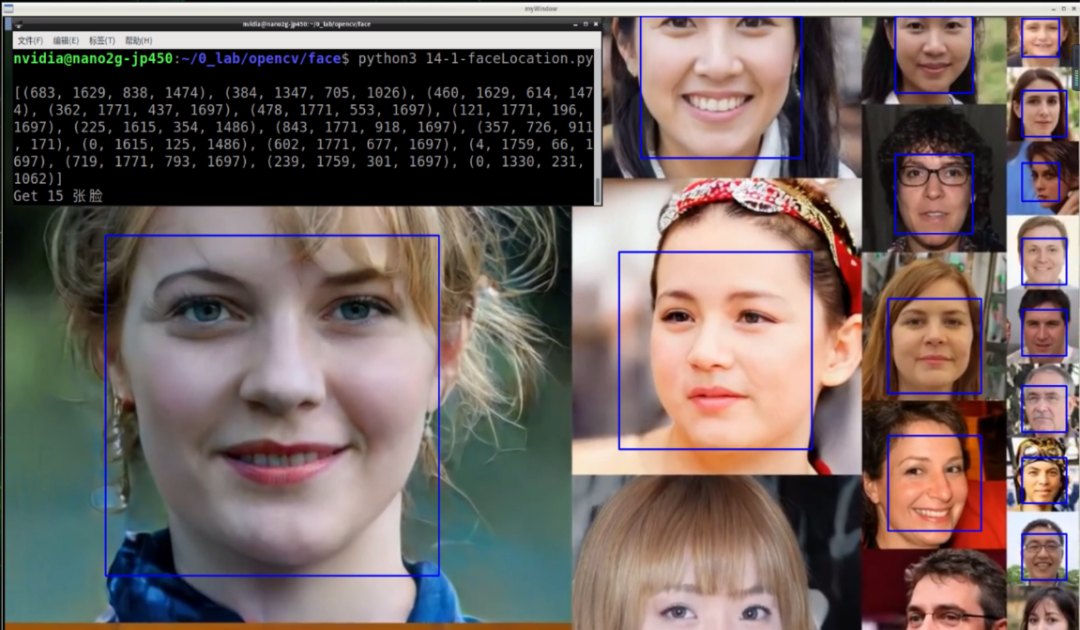
这里可以看到下方终端上显示 15 组位置数据,分别对应至上方的 15 张脸的位置,不过顺序不一定完全对应。
事实上在上述代码中读入图像的函数,可以直接调用 OpenCV 的 cv2.imread(),这样读入的图像就是 BRG 格式,还可以节省一次 cv2.cvtColor 转换的过程,因此将上面代码修改成下方代码,会得到相同的结果。

如果想要知道本次检测能定位出几张人脸?只要在 “for 循环”前面给定一个参数i,设定起始值为 0,然后在“for 循环”里面执行递增计算,就能算出有多少张脸。
视频中的人脸定位
一旦图像的处理能够顺利,视频的处理就是重复读入、按帧处理。因此只要将前面的代码外面再套一层“while 循环”来读取视频,大致上就能应用在视频中寻找人脸的位置与数量。修改后的代码如下:

这样就能在视频中定位人脸的位置!不过实际执行的时候,会发现识别的性能很慢,大约只能到 1~2FPS 的性能,这是因为 face_locations() 这个函数会消耗比较多的计算资源,导致性能不好。
性能优化的策略
这里提供一个性能改善的方式,就是将给予 face_locations() 的图像先进行缩小,找到定位之后再将定位点按原比例还原,在原图上画出框线。
使用变量 rate 来调整给 face_locations() 的长宽比例,然后用 small_frame 存放 cv2.resize 后的图像,再以 small_frame 提供给 face_locations() 进行抓脸的任务。修改后的完整代码如下:

当自行调整 rate 比例之后,就能明显感受到识别性能与人脸定位数量的差异。在本范例中,
rate=1(原始比例),性能约 1.5FPS,能定位12~17张脸
rate=2(1/4)时,性能约3~4 FPS,能定位6~9张脸
rate=3(1/9)时,性能约6~7 FPS,能定位5~8张脸
rate=4(1/16)时,性能约12~13FPS,能定位3~5张脸
如果想要用摄像头进行以上的实验,只需将函数 cv2.VideoCapture() 里面的来源改成摄像头就可以。
以上就是很简单地调用 face_recognition 库里面的 face_locations() 函数,就能轻松实现在图像、视频中定位出人脸的功能,是不是非常简单?











