Magnum IO架构为现代化数据中心IO提速
2020-11-12 18:58
 分享到微信
分享到微信
 分享到微博
分享到微博
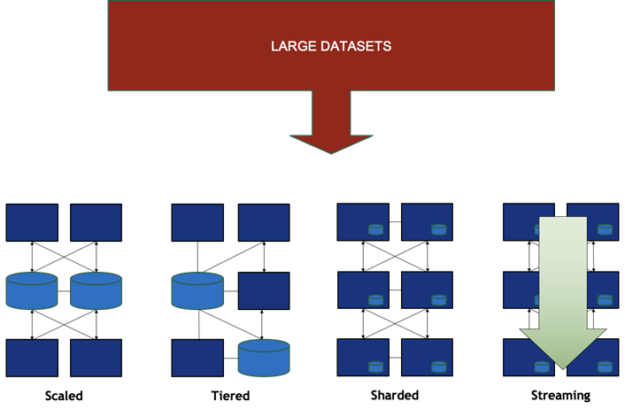
曾经,计算单元的边界就是机箱的金属板。今天,机箱已经不能将用于解决某个问题的资源或数据集完全包含在其中。数据中心成为了新的计算单元,单个机箱不仅需要容纳GPU、CPU和NIC,还需控制海量数据处理所需的大量协作资源。单个机箱可容纳所有计算资源和相关数据的时代已成为过去,资源变得越来越分散。如图1所示,数据集现在能够实现跨节点的增长、以及不同位置间的流动与分享。
图1 数据中心内的各种数据分布形式
为了运行大型协作式计算任务,实现更好的扩展,需要数据中心间高效率“东西向”(横向)通信。日益复杂的工作流也同样分布在节点内和节点之间的资源层次结构中。最新的工作流一般由高性能计算(HPC)、深度学习、数据分析和可视化组合而成,而这些工作都基于数据和计算资源共享上进行。工作流一般由微服务构成。不仅是企业,在HPC(高性能计算)中使用容器和Kubernetes部署微服务的情况也越来越多。各项微服务之间会存在不可预测的数据管道,同时,它们的数量和位置也会随负载动态变化。
遍布整个数据中心的分布式资源集仍需凝聚成一个统一的单元来执行分布式应用和微服务的组合。数据访问和各阶段不可预测的数据移动带来了严峻的挑战。要应对这些挑战,需要更高的带宽、更低的延迟、减少对CPU的干扰和依赖,以及网络内计算。同时,也要求能够在灵活的抽象化过程中有原则地增强通用IO性能,而非依赖仅适用于单一应用场景的特殊情况调整。此外,还需对所有IO流量进行微调,从而提升服务质量、故障预测能力、可靠性及可用性。
NVIDIA Magnum IO是现代数据中心的 IO 子系统。Magnum IO架构可提供有序的功能安排,从而以最佳方式设计应用、框架或基础设施,使它们可在先进的、具备高计算力GPU、存储和高性能互连技术的数据中心中运行。Magnum IO运用抽象化来隐藏底层软件层的复杂性,从而让用户受益于NVIDIA开发人员创新所带来的技术不断发展和突破性性能。这种灵活的抽象化可让使用者直接获取所需数据,从复杂且不可预知的基层数据管理中解脱出来。
Magnum IO 架构
Magnum IO这一名称源自多GPU、多节点输入/输出。在数据中心内,存在必须进行数据管理的资源层次结构。在GPU、节点、子集群和数据中心层面,均有计算、内存和存储资源层次结构。所有NVIDIA GPU与NVIDIA网络的数据访问、移动和管理,都必须通过NVIDIA提供的各种API、库和编程模型进行控制和完成抽象化过程。
上述即为Magnum IO的功能。在抽象化下,实现可优化性能和实用性。例如在数据移动的同时,可在网络中进行计算。通过将数据卸载到DPU(数据处理单元),可以将数据管理与CPU上运行的恶意代码隔离。无论数据中心及其网络配置如何,管理、效率、可维护性和可靠性都可以得到简化。Magnum IO架构规定了可以提供哪些功能及其提供的方式。
架构原则
任何架构都需要通过一组原则来定义。对于CUDA架构和Magnum IO架构来说,有四项通用基本原则:并行性、异步性、层次结构以及工具和遥测。Magnum IO的高级别抽象化添加了第五项原则 ——灵活性。
1
并发性
CUDA:CUDA编程模型通过将并行性与运行在数据网格上的计算内核相结合,从而使程序能利用大规模并行GPU核心。为了应对阿姆达尔定律并消除扩展瓶颈,CUDA版本不断更新发布,以减少CPU-GPU协调导致的延迟和其他消耗。
Magnum IO:同样,IO可跨线程并行运行(例如使用NVSHMEM)、在节点内跨GPU并行运行和跨节点扩展。全连接网络避免了结构瓶颈。RDMA(Remote Direct Memory Access)对于减少开销,避免CPU带宽和吞吐瓶颈至关重要。
2
异步性
CUDA:对并发性来说,避免拥塞操作至关重要。CUDA流和图形支持延迟执行,因此工作可被迅速排入队列,并在提交后运行时解决依赖关系。
Magnum IO:Magnum IO的许多编程接口都提供面向流的API,例如NCCL、NVSHMEM和cuFile。
3
层次结构
CUDA:CUDA编程模型规定,用户必须以多块分层网格形式显示数据集,每块包含多个线程,可以轻松将其映射到对称的多处理器上。这一规定可帮助更有效地利用计算资源、数据路径和硬件同步分层结构,进行数据收集和位置控制,从而更高效地进行扩展。CUDA还提供共享GPU和在同一节点内进行跨进程通信的机制。
Magnum IO:Magnum IO可以在整个层次结构的各个部分,充分利用内存和存储(包括节点、子集群、数据中心)中。
4
工具和遥测
CUDA:开发人员工具可以深入了解CUDA应用程序内部发生的情况,以及所使用到的GPU资源信息。
Magnum IO:Magnum IO扩展该范围,它涵盖了数据中心的操作。结合了实时遥测、性能分析和故障检测功能,让你能够深入了解系统的运行时性能。
5
灵活性
Magnum IO:Magnum IO既具备可控的底层接口,又具备可自动管理位置、路由和性能折衷的能够提升产能的高级别抽象。在这些抽象化下,Magnum IO的部署可免费使用CUDA平台,以及其他NVIDIA技术和开源技术的最新软硬件功能。这些实现还可以在更高级别的接口下,自由选择在哪里完成工作以及如何管理数据。
受众
Magnum IO架构面向以下受众:
终端用户。通用框架和接口启用了Magnum IO后,具有较低层的性能优势,这些层针对每个平台和拓扑进行了高度优化
应用开发者。该架构定义了空间和功能,它可以指导设计人员高效创建持久化软件架构和框架。Magnum IO提供实现性能最简单的途径。
中间件开发者。提供Magnum IO技术的SDK为底层开发者提供完成工作所需的所有工具。
管理员。IO管理(包括服务开通、遥测和分析)可帮助管理员对数据中心结构进行监控、预防性故障排除并使其保持在最佳状态。
层
图2所示为Magnum IO架构中的多个层。上层基本依赖于以下数据相关的抽象化。
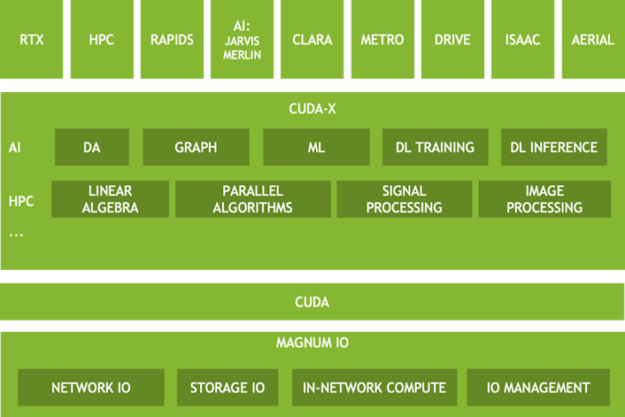
图2 Magnum IO架构是数据中心软件堆栈内一些较高级别CUDA-X和特定领域产品的基础
VerTicals — 这些组件专用于各种应用领域。Magnum IO的某些方面可能对于特定领域行业而言是唯一的。
CUDA-X — 基于CUDA的一组高度优化、特定领域函数库。这里所示的是多个子类别中的两个:HPC和AI。这些功能集在很大程度上取决于数据中心的IO子系统。
CUDA — 许多Magnum IO功能都位于CUDA驱动程序和工具包之上或与之重叠。部分垂直领域和CUDA-X依赖于Magnum IO,另外的部分仅依赖CUDA本身。
Magnum IO — 与数据相关的技术可以分为四类:网络IO、存储IO、网络内计算和IO管理。
该架构提供了一种思维模式,供使用者在为数据中心开发应用、框架以及基础设施时参考。
Magnum IO组件
图3所示为与数据中心IO子系统的静态数据、移动数据和工作数据相关的技术。

图3 当前的Magnum IO组件,包含数据移动、数据访问和数据管理的所有领域的新旧产品
以下是关于这些功能的常见主题:
灵活的抽象化,可在高级接口和标准下进行创新和优化。
硬件特性和底层技术通过易于使用的持久化接口公开。
CPU卸载既可避免主机CPU成为瓶颈,又使服务与主机CPU上运行的恶意代理隔离。
通过简单的入口实现性能优化,而选择性控制则可实现专家调优。
管理提供可见性、可维护性和控制工具,使数据中心解决方案可以长期维护。
行动号召
我们诚邀您参加并观看GTC秋季大会分会Magnum IO:适合现代化加速数据中心的IO子系统(链接:https://www.nvidia.com/en-us/gtc/session-catalog/?search=a22370&tab.catalogtabfields=1600209910618001TWM3)。您可以试用几项新技术:
GPUDirect Storage公测版本v0.8,可以通过跳过CPU缓冲区中的多余副本并减少较小传输延迟来实现多倍带宽的性能提升。它可以在目前的硬件上运行,但需要安装内核驱动程序和用户级函数库。更多信息,参见以下资源:
GTC 2020年秋季大会:使用Magnum IO和GPUDirect Storage为存储提速
(https://www.nvidia.com/en-us/gtc/session-catalog/?search=A21209&tab.catalogtabfields=1600209910618001TWM3)
GPUDirect Storage下载页面
(https://developer.nvidia.com/gpudirect-storage)
GPUDirect用户指南
(http://docs.nvidia.com/gpudirect-storage)
观看即将发布的RAPIDS版本,该版本支持GPUDirect Storage。因此,可使用cuDF在Parquet等文件格式上试用。
(http://rapids.ai/)
NVSHMEM 1.1.3于2020年9月发布,为GPU间单侧数据传输带来新的信令功能。点击链接,马上试用!
(https://developer.nvidia.com/nvshmem-downloads)
于2020年7月更新的NCCL 2.7.8加入了对于点对点传输的支持,这也支持了更多的通信集合,如all_gatherv和all_scatterv。
(https://github.com/NVIDIA/nccl)
更多有关这些技术性能优势的信息,请观看GTC 2020秋季站视频回放:网络内计算:加速科学计算和深度学习应用。
(https://www.nvidia.com/en-us/gtc/session-catalog/?tab.catalogtabfields=1600209910618001TWM3&search=a21241)
NVIDIA致力于通过创新的解决方案解决端到端的问题。为了攻克难题,NVIDIA的CUDA平台开发者不断与应用开发者进行有效沟通,应用开发者提出需求和高质量的复制程序,以解决具有挑战性的问题。NVIDIA还开发出各项新技术并对路线图进行改良,以此推进合作。NVIDIA诚邀您与我们开展更密切的合作,一同帮助科学界取得新的成就!











