NVIDIA 推出迁移学习 Toolkit 2.0 和 DeepStream SDK 5.0
2020-08-13 11:11
 分享到微信
分享到微信
 分享到微博
分享到微博
许多行业都对先进视频分析解决方案有着巨大需求。目前常见用例包括零售行业了解客户对品牌的喜好、公共交通站点人流量管理及分析、根据社交距离规定优化城市、医院和购物中心的交通运营以及工厂中的缺陷检测等。
构建和部署这些解决方案需要完成大量技术工作,例如收集和采集相关数据集,以及为实现高精度、大规模部署时的实时性能和可管理性而对AI模型进行大量训练等。
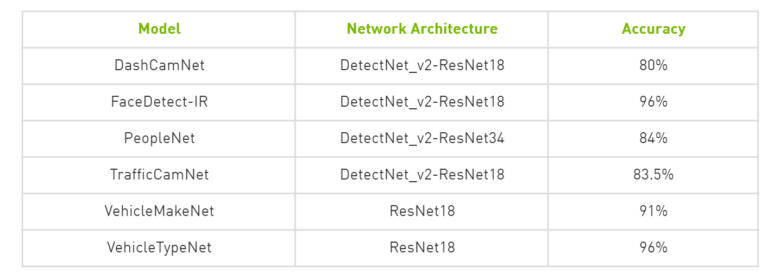
迁移学习 Toolkit 能够通过提供各种预训练 AI 模型和内置功能(例如迁移学习、裁剪、微调和量化感知训练)帮助 AI 应用开发者和软件开发者加速 AI 训练。开发者可以使用 PeopleNet、VehicleMakeNet、TrafficCamNet、DashCamNet 等专用模型为几种流行用例构建高精度 AI。
NVIDIA DeepStream SDK 可帮助开发者和企业,构建可以通过 Kubernetes 和 Helm Charts 大规模部署和轻松管理的高性能视觉 AI 应用程序与服务。
我们已在 Vision AI 软件套件迁移学习 Toolkit 2.0 和 DeepStream SDK 5.0 中添加了开发者社区中呼声较高的主要增强功能,具体如下。
主要增强功能
已全面上市:迁移学习 Toolkit 2.0
迁移学习 Toolkit(TLT)无需重新开始训练,避免了这一耗时过程。借助该软件套件,AI 专业知识有限的开发者也可以创建高精度 AI 模型进行部署。为提高推理吞吐量,此版本增加了对几个常见和最新网络的训练支持。可以从 NGC 免费下载预训练模型和 TLT 容器。主要亮点包括:
--- 全新 NVIDIA 专用模型:使用高精度专用模型部署人数统计、车辆追踪和热图生成等常见用例的 AI 应用。
--- 量化感知训练:使用 INT8 精度实现 2 倍推理速度,同时通过量化感知训练保持与 FP16 / FP32 相近的性能。进一步了解 QAT
--- 通过在 NVIDIA Volta 和 Turing GPU Tensor 核心上运行的自动混合精度(AMP)加速训练并减少存储带宽
--- 使用 MaskRCNN 网络架构通过实例分割获得像素级精度。可以参考我们的 MaskRCNN 开发者教程
--- 扩展对象检测模型支持,例如 YOLO-V3、SSD和 FasterRCNN、RetinaNet、DSSD 以及DetectNet_v2
--- 端到端视觉 AI 性能:凭借与 DeepStream SDK 5.0 的开箱即用兼容性,您可以更轻松地获得更大的吞吐量并快速部署 TLT 中的模型。在我们的产品页面上可以查看使用 TLT 和 DeepStream 实现的端到端吞吐量结果,包括在 NVIDIA T4、Jetson Nano、AGX Xavier 和 Xavier NX 上测试的产品级模型最高精度和帧率
--- 通过多 GPU 支持加速 AI 模型训练
通过我们的开发者教程、示例应用和网络研讨会可以了解更多有关 TLT 功能的信息。
已全面上市:DeepStream SDK 5.0
DeepStream 是一款用于 AI 图像和视频解析的流分析工具包。您可以使用 DeepStream 构建高效边缘应用,从而获取实时见解。该产品级软件能够为 AI 应用开发者、软件合作伙伴和原设备制造商(OEM)提供各种增强功能,帮助他们为众多行业构建视觉 AI 或先进视频分析应用与服务,包括智慧城市、零售分析、健康与安全、体育运动分析、机器人技术、制造、物流等。其主要亮点包括:
--- 通过 DeepStream 在本地运行流行的深度学习框架:Triton Inference Server(之前的TensorRT Inference Server)的新推理功能使开发者可以在DeepStream Pipeline中的 TensorFlow、TensorFlow-TensorRT、PyTorch 或 ONNX 本地部署模型
--- 基于 Python 的开发:您可以从 C/C ++ 或 Python 应用中选择,构建 DeepStream Pipeline。两种开发选项的性能相近
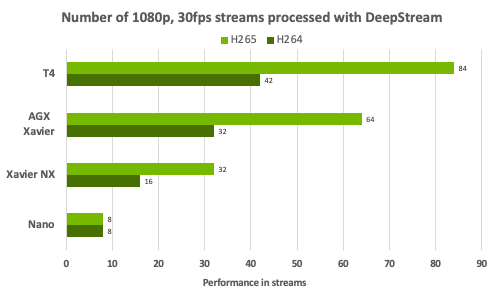
--- 实时性能:DeepStream 加速框架为复杂的视觉 AI Pipeline 提供了最高的流处理密度。该图汇总了在 1080p /30 FPS 条件下, DeepStream SDK 支持的各 NVIDIA 平台所实现的流密度
--- 在 Red Hat Enterprise Linux(RHEL)中本地构建和部署 DeepStream 应用程序
--- 边缘智能记录:通过选择性记录节省边缘宝贵磁盘空间,以加快搜索速度。通过云到边缘消息传递,控制来自云的记录
--- 物联网功能
通过边缘/云双向物联网消息传递,在云端管理和控制 DeepStream 应用程序
通过 OTA AI 模型更新,实现应用零停机时间
使用基于 SASL/Plain 的身份验证和 TLS 身份验证,确保边缘与云之间的通信安全
--- 与迁移学习 Toolkit 2.0 的互操作性更加紧密,通过 DeepStream 实现开箱即用的模型部署。请在 DeepStream 产品页面上查阅使用 TLT 和 DeepStream 的端到端吞吐量结果,包括在 NVIDIA T4、Jetson Nano、AGX Xavier 和 Xavier NX 上测试的产品级模型的最高精度和 FPS 结果
--- 引入 Jetson Xavier NX 支持:在全球最小的边缘 AI 超级计算机上部署 AI 应用。所提供的参考应用程序适用于所有受支持的 NVIDIA 平台
构建和部署这些解决方案需要完成大量技术工作,例如收集和采集相关数据集,以及为实现高精度、大规模部署时的实时性能和可管理性而对AI模型进行大量训练等。
迁移学习 Toolkit 能够通过提供各种预训练 AI 模型和内置功能(例如迁移学习、裁剪、微调和量化感知训练)帮助 AI 应用开发者和软件开发者加速 AI 训练。开发者可以使用 PeopleNet、VehicleMakeNet、TrafficCamNet、DashCamNet 等专用模型为几种流行用例构建高精度 AI。
NVIDIA DeepStream SDK 可帮助开发者和企业,构建可以通过 Kubernetes 和 Helm Charts 大规模部署和轻松管理的高性能视觉 AI 应用程序与服务。
我们已在 Vision AI 软件套件迁移学习 Toolkit 2.0 和 DeepStream SDK 5.0 中添加了开发者社区中呼声较高的主要增强功能,具体如下。
主要增强功能
已全面上市:迁移学习 Toolkit 2.0
迁移学习 Toolkit(TLT)无需重新开始训练,避免了这一耗时过程。借助该软件套件,AI 专业知识有限的开发者也可以创建高精度 AI 模型进行部署。为提高推理吞吐量,此版本增加了对几个常见和最新网络的训练支持。可以从 NGC 免费下载预训练模型和 TLT 容器。主要亮点包括:
--- 全新 NVIDIA 专用模型:使用高精度专用模型部署人数统计、车辆追踪和热图生成等常见用例的 AI 应用。
--- 量化感知训练:使用 INT8 精度实现 2 倍推理速度,同时通过量化感知训练保持与 FP16 / FP32 相近的性能。进一步了解 QAT
--- 通过在 NVIDIA Volta 和 Turing GPU Tensor 核心上运行的自动混合精度(AMP)加速训练并减少存储带宽
--- 使用 MaskRCNN 网络架构通过实例分割获得像素级精度。可以参考我们的 MaskRCNN 开发者教程
--- 扩展对象检测模型支持,例如 YOLO-V3、SSD和 FasterRCNN、RetinaNet、DSSD 以及DetectNet_v2
--- 端到端视觉 AI 性能:凭借与 DeepStream SDK 5.0 的开箱即用兼容性,您可以更轻松地获得更大的吞吐量并快速部署 TLT 中的模型。在我们的产品页面上可以查看使用 TLT 和 DeepStream 实现的端到端吞吐量结果,包括在 NVIDIA T4、Jetson Nano、AGX Xavier 和 Xavier NX 上测试的产品级模型最高精度和帧率
--- 通过多 GPU 支持加速 AI 模型训练
通过我们的开发者教程、示例应用和网络研讨会可以了解更多有关 TLT 功能的信息。
已全面上市:DeepStream SDK 5.0
DeepStream 是一款用于 AI 图像和视频解析的流分析工具包。您可以使用 DeepStream 构建高效边缘应用,从而获取实时见解。该产品级软件能够为 AI 应用开发者、软件合作伙伴和原设备制造商(OEM)提供各种增强功能,帮助他们为众多行业构建视觉 AI 或先进视频分析应用与服务,包括智慧城市、零售分析、健康与安全、体育运动分析、机器人技术、制造、物流等。其主要亮点包括:
--- 通过 DeepStream 在本地运行流行的深度学习框架:Triton Inference Server(之前的TensorRT Inference Server)的新推理功能使开发者可以在DeepStream Pipeline中的 TensorFlow、TensorFlow-TensorRT、PyTorch 或 ONNX 本地部署模型
--- 基于 Python 的开发:您可以从 C/C ++ 或 Python 应用中选择,构建 DeepStream Pipeline。两种开发选项的性能相近
--- 实时性能:DeepStream 加速框架为复杂的视觉 AI Pipeline 提供了最高的流处理密度。该图汇总了在 1080p /30 FPS 条件下, DeepStream SDK 支持的各 NVIDIA 平台所实现的流密度
--- 在 Red Hat Enterprise Linux(RHEL)中本地构建和部署 DeepStream 应用程序
--- 边缘智能记录:通过选择性记录节省边缘宝贵磁盘空间,以加快搜索速度。通过云到边缘消息传递,控制来自云的记录
--- 物联网功能
通过边缘/云双向物联网消息传递,在云端管理和控制 DeepStream 应用程序
通过 OTA AI 模型更新,实现应用零停机时间
使用基于 SASL/Plain 的身份验证和 TLS 身份验证,确保边缘与云之间的通信安全
--- 与迁移学习 Toolkit 2.0 的互操作性更加紧密,通过 DeepStream 实现开箱即用的模型部署。请在 DeepStream 产品页面上查阅使用 TLT 和 DeepStream 的端到端吞吐量结果,包括在 NVIDIA T4、Jetson Nano、AGX Xavier 和 Xavier NX 上测试的产品级模型的最高精度和 FPS 结果
--- 引入 Jetson Xavier NX 支持:在全球最小的边缘 AI 超级计算机上部署 AI 应用。所提供的参考应用程序适用于所有受支持的 NVIDIA 平台











