多实例GPU将AI工作效率“驶上快车道”
2020-06-05 18:36
 分享到微信
分享到微信
 分享到微博
分享到微博
还记得大学期间,中午在食堂打饭窗口排长队的景象吗?如果同时开放多个打饭窗口,那么所有人就能同时打到午饭。
这就是在NVIDIA Ampere 架构中所实现的多实例GPU(Multi-Instance GPU ,MIG)的本质。
MIG能够将单个NVIDIA A100 GPU分割为多达七个独立GPU实例。它们能够同时运行,而且每个实例都拥有其独立的内存、缓存和流式多处理器。相比之前的GPU,A100 GPU能够以高达7倍的利用率提供有保证的服务质量(QoS)。
在MIG模式下,A100可以同时运行多达七个不同规模的AI或HPC工作负载。该功能特别适用于通常不会用到现代GPU全部性能的AI推理工作。
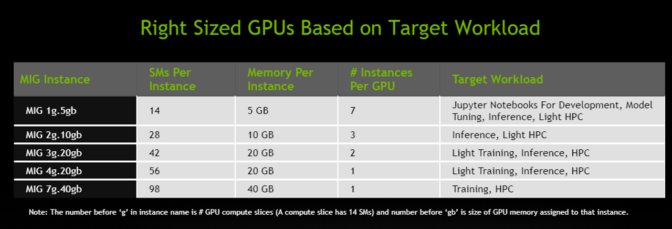
用户可以根据其处理任务的需求创建实例组合,如:创建两个20 GB内存的实例、三个10 GB内存的实例或七个5 GB内存的实例。
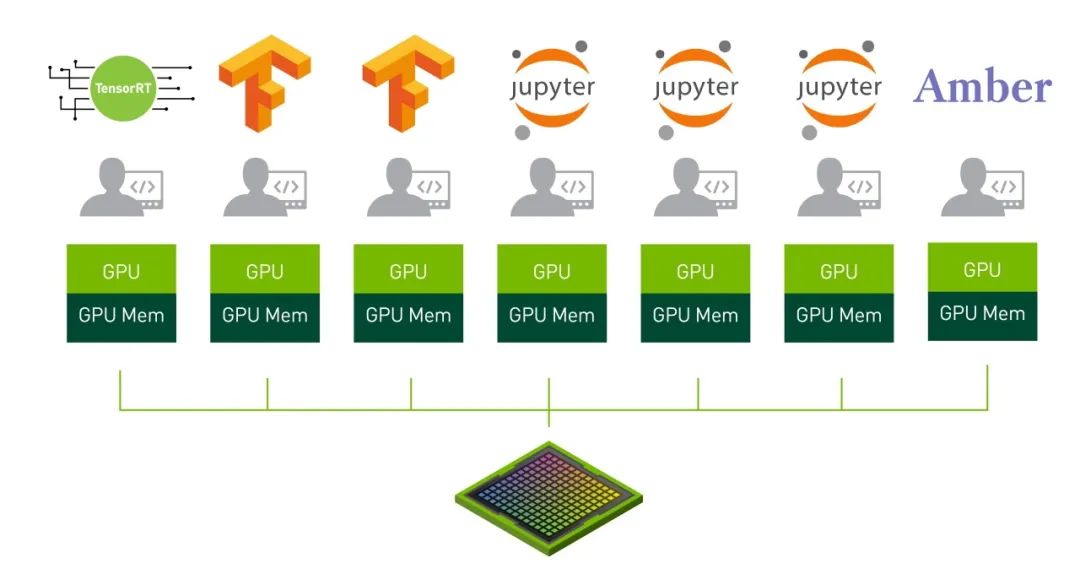
系统管理员可以设置实例组合,在单个A100 GPU上同时运行推理、训练和HPC处理任务。
由于MIG将各个GPU实例相互隔离,因此能够提供故障隔离功能,这使得一个实例中的问题不会影响同一物理GPU上运行的其他实例。每个实例都能提供有保证的QoS,确保用户的处理任务的延迟和吞吐量能够符合预期。
云服务供应商和其他企业可以使用MIG来提高其GPU服务器的利用率,从而为用户提供多达7倍的GPU实例。
Google Cloud首席软件工程师Tim Hockin表示:“NVIDIA是Google Cloud的战略合作伙伴,我们很高兴他们能够为客户提供创新技术。”
Hockin还表示:“MIG能够共享Kubernetes集群中的GPU,将效率和利用率提升到新高度。我们期待着与NVIDIA和Kubernetes社区合作,实现GPU用例共享,并通过Google Kubernetes Engine提供给用户们。”
MIG赋予企业飞速推理能力
MIG能够帮助企业用户加速AI模型开发和部署。
MIG可以让多达七名数据科学家同时访问专用GPU,让他们能够并行微调深度学习模型,从而获得最佳的精度和性能。这项工作十分耗时,但通常又不需要太高的计算力,因此这正是MIG的绝佳应用场景。
在模型做好运行准备后,MIG可使单个GPU一次性处理多达七个推理作业。这非常适用于小型、低延迟模型的单批次推理工作负载,这类模型不需要全部GPU性能。
Postmates人工智能总监Zhenyu Guo表示:“NVIDIA技术对于我们的送货机器人平台Serve而言至关重要。”
“MIG让我们能够随时重新配置计算资源,因此我们能够充分利用我们所部署的每个GPU来满足不断变化的工作负载需求、优化基于云的基础架构,实现效率和成本节省的最大化。”
专为IT / 开发运营设计
用户无需更改CUDA编程模型即可从专为 AI和HPC开发的MIG中获益。MIG可与现有的Linux操作系统以及Kubernetes和容器一起使用。
借助于NVIDIA为A100提供的软件,用户能够充分发挥MIG的优势。这些软件包括了GPU驱动程序、NVIDIA的CUDA 11(即将推出)、经过更新的NVIDIA容器运行时以及通过NVIDIA 设备插件为Kubernetes提供的新资源类型。
同时使用MIG和NVIDIA虚拟计算服务器(vComputeServer)将能够实现Red Hat Virtualization和VMware vSphere等虚拟机管理程序的管理和监控优势。这一组合将支持多种流行的功能,例如实时迁移和多租户等。
红帽公司营销总监Chuck Dubuque表示:“我们的客户越来越需要管理在虚拟机上运行的多租户工作流,同时还要提供隔离和安全优势。”
他还补充说:“NVIDIA A100 GPU上的全新多实例GPU功能支持从云到边缘的众多新AI加速工作负载,这些工作负载都在红帽平台上运行。”
通过NVIDIA A100及其软件,用户将能够如同在物理GPU上一样,在其新的GPU实例上查看和安排作业。
这就是在NVIDIA Ampere 架构中所实现的多实例GPU(Multi-Instance GPU ,MIG)的本质。
MIG能够将单个NVIDIA A100 GPU分割为多达七个独立GPU实例。它们能够同时运行,而且每个实例都拥有其独立的内存、缓存和流式多处理器。相比之前的GPU,A100 GPU能够以高达7倍的利用率提供有保证的服务质量(QoS)。
在MIG模式下,A100可以同时运行多达七个不同规模的AI或HPC工作负载。该功能特别适用于通常不会用到现代GPU全部性能的AI推理工作。
用户可以根据其处理任务的需求创建实例组合,如:创建两个20 GB内存的实例、三个10 GB内存的实例或七个5 GB内存的实例。
系统管理员可以设置实例组合,在单个A100 GPU上同时运行推理、训练和HPC处理任务。
由于MIG将各个GPU实例相互隔离,因此能够提供故障隔离功能,这使得一个实例中的问题不会影响同一物理GPU上运行的其他实例。每个实例都能提供有保证的QoS,确保用户的处理任务的延迟和吞吐量能够符合预期。
云服务供应商和其他企业可以使用MIG来提高其GPU服务器的利用率,从而为用户提供多达7倍的GPU实例。
Google Cloud首席软件工程师Tim Hockin表示:“NVIDIA是Google Cloud的战略合作伙伴,我们很高兴他们能够为客户提供创新技术。”
Hockin还表示:“MIG能够共享Kubernetes集群中的GPU,将效率和利用率提升到新高度。我们期待着与NVIDIA和Kubernetes社区合作,实现GPU用例共享,并通过Google Kubernetes Engine提供给用户们。”
MIG赋予企业飞速推理能力
MIG能够帮助企业用户加速AI模型开发和部署。
MIG可以让多达七名数据科学家同时访问专用GPU,让他们能够并行微调深度学习模型,从而获得最佳的精度和性能。这项工作十分耗时,但通常又不需要太高的计算力,因此这正是MIG的绝佳应用场景。
在模型做好运行准备后,MIG可使单个GPU一次性处理多达七个推理作业。这非常适用于小型、低延迟模型的单批次推理工作负载,这类模型不需要全部GPU性能。
Postmates人工智能总监Zhenyu Guo表示:“NVIDIA技术对于我们的送货机器人平台Serve而言至关重要。”
“MIG让我们能够随时重新配置计算资源,因此我们能够充分利用我们所部署的每个GPU来满足不断变化的工作负载需求、优化基于云的基础架构,实现效率和成本节省的最大化。”
专为IT / 开发运营设计
用户无需更改CUDA编程模型即可从专为 AI和HPC开发的MIG中获益。MIG可与现有的Linux操作系统以及Kubernetes和容器一起使用。
借助于NVIDIA为A100提供的软件,用户能够充分发挥MIG的优势。这些软件包括了GPU驱动程序、NVIDIA的CUDA 11(即将推出)、经过更新的NVIDIA容器运行时以及通过NVIDIA 设备插件为Kubernetes提供的新资源类型。
同时使用MIG和NVIDIA虚拟计算服务器(vComputeServer)将能够实现Red Hat Virtualization和VMware vSphere等虚拟机管理程序的管理和监控优势。这一组合将支持多种流行的功能,例如实时迁移和多租户等。
红帽公司营销总监Chuck Dubuque表示:“我们的客户越来越需要管理在虚拟机上运行的多租户工作流,同时还要提供隔离和安全优势。”
他还补充说:“NVIDIA A100 GPU上的全新多实例GPU功能支持从云到边缘的众多新AI加速工作负载,这些工作负载都在红帽平台上运行。”
通过NVIDIA A100及其软件,用户将能够如同在物理GPU上一样,在其新的GPU实例上查看和安排作业。











