NVIDIA发布 NVIDIA NeMo,加速语音和语言模型开发
2020-05-25 19:30
 分享到微信
分享到微信
 分享到微博
分享到微博
这是一个更新版本的神经模块,可以用于加快语音和语言模型的开发。本文包含了有关NGC中预训练模型的相关更新信息和基于自定义数据集微调模型的部分,以及使用文本语音转换合计升级NeMo图,和使用LibriSpeech数据集替换示例中的AN4数据集。
作为一位研究者,如果想构建最新的语音和语言模型,其必须能够快速地对新型网络架构进行实验。此类实验有可能会侧重于通过修改现有网络架构提高性能,也可能会是通过将语音和语言模型合并,以构建端到端应用的高级实验。
此类工作通常始于研究示例代码和模型库中的预训练模型始。但是通过这种方式来复用代码和预训练模型可能会较为棘手。
这些模型中的输入和输出、编码样式以及数据处理层可能彼此不兼容。更糟糕的情况是,也许用户可以在其代码中连接这些模型,使其在技术上“有效”,但实际情况却是这些模型存在着语义错误。用户需要花费大量的时间、精力和重复的代码,来确保模型可以安全地重复使用。
而随着模型复杂性和模型复用的增加,这种方法将不再有效。
现在我们将这种方法和构建复杂软件应用的方法相对比。复杂软件应用的发展历程是一个抽象层次不断提高的过程:从机器代码到汇编语言,再到到具有编译器和类型系统的结构化编程,面向对象编程。这些高级工具带来了更好的保护和代码重用性。
深度学习库也经历了类似的发展历程,CUDA和cuDNN等底层工具能够提供出色的性能,TensorFlow能为人力成本花销提供高度的灵活性。但Keras和PyTorch等高级存储库的主要对象仍是tensor张量、简易操作和层。
NVIDIA NeMo介绍
NVIDIA NeMo是一个带有PyTorch后端的开源套件,它能够进一步提高抽象层次。NeMo使用户可以使用可重用的组件轻松地建立复杂的神经网络架构。利用神经类型,这些组件之间会自动进行语义兼容性检查。
NeMo能够利用NVIDIA GPU上的Tensor Core核心,通过混合精度计算来获得最高性能。其包括了将训练扩展到多GPU系统和多节点集群的功能。
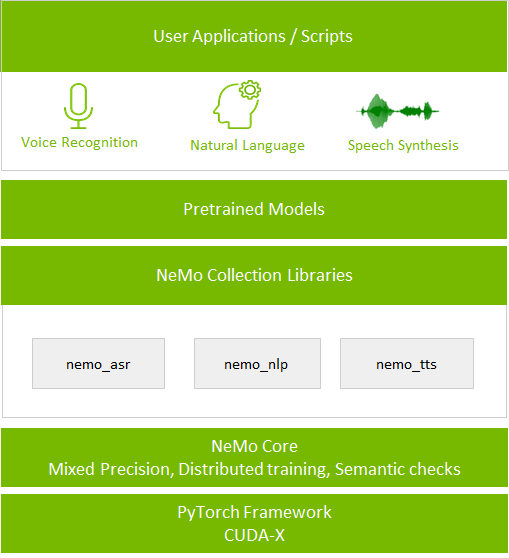
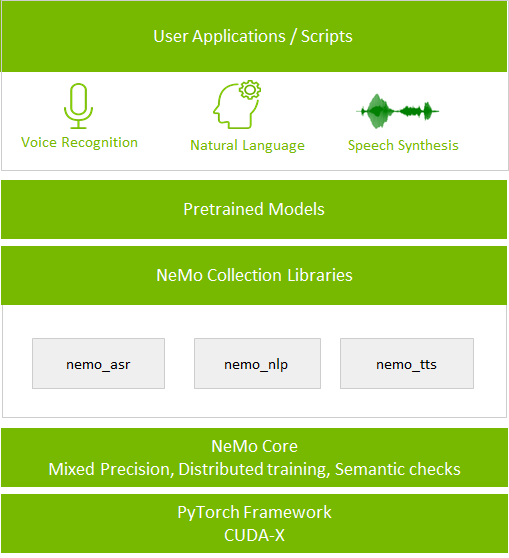
图1:NeMo应用堆栈
该套件的核心是神经模块概念。神经模块会获得一组输入后,计算出一组输出。用户可以将其视为介于层和整个神经网络之间某处的一个抽象。通常一个模块对应神经网络的一个概念部分,例如编码器、解码器或语言模型。
神经模块的输入和输出都具有神经类型,包括语义、Axis次序和输入/输出tensor张量的维数。这一归类使得NeMo可以安全地链接在一起,组成应用,比如在下文中所演示的的自动语音识别(ASR)示例。
NeMo还带有用于ASR、NLP和TTS的可扩展模块集合。此类集合为数据加载、预处理,和训练不同的网络结构(包括Jasper、BERT、Tacotron 2和WaveGlow)提供了API操作。用户还可以基于自定义数据集,使用NVIDIA NGC中的预训练模型进行模型微调。
该套件是为解决NVIDIA应用研究团队所面临的挑战而设计的。NVIDIA希望通过将此项目开源,来和整个语音、NLP和TTS研究者社区分享此项成果,并促进彼此之间的合作。
建立新模型
接下来将通过建立一个简单的ASR模型来说明如何使用NeMo。你将了解神经类型如何提供语义安全检查,以及如何以最轻松的方式将此工具横向扩展到多个GPU。
入门
NVIDIA/NeMo GitHub存储库概括列举了一般性要求和安装说明。该存储库提供了多种NeMo安装方式:
使用1个NGC容器
使用软件包管理器(pip)命令:pip install nemo_toolkit_[all/asr/nlp/tts]。软件包管理器能够让用根据其指定的集合(例如asr、nlp或tts)安装单个NeMo软件包。
使用可用于构建Docker镜像的Dockerfile 并且可以直接运行NeMo安装。
使用端到端自动语音识别介绍:Jupyter笔记本中的Jupyter笔记本示例了解如何在NeMo中使用pip命令设置环境并训练Jasper ASR模型。
Jasper
在此ASR示例中,用户将使用到一个名为Jasper的网络。Jasper是一个端到端的ASR模型,它无需任何附加对齐信息就能转录语音样本。更多信息,请参见Jasper:端到端卷积神经声学模型。
该模型的训练处理流程包括以下模块。每个逻辑块都对应一个神经模块。

图2 Jasper语音识别管道
Jupyter笔记本
在Jupyter笔记本中构建模型的步骤如下:
将必要的神经模块实例化。
描述这些神经模块的DAG
调用一个操作,例如训练。
这里的步骤很少,这是因为用户此时所采用的是更高层次的抽象
有关ASR介绍和逐步操作步骤,请参见端对端自动语音识别介绍:Jupyter笔记本。
基于自定义数据集微调模型
在使用预训练模型基于自定义数据构建高精度模型的过程中,微调起到了重要作用。这属于一种迁移学习技术。迁移学习能够将一项任务中所获得的知识迁移,转而应用于另一项类似任务的执行当中。
NGC中有几种预训练模型,用户会在启用NeMo微调用例时用到它们。接下来的部分对此进行更详细的介绍。若要了解如何通过示例微调模型,请参见通过NeMo快速启动不同语言的语音识别模型训练。
NeMo仅需一行代码就可将模型导出至 NVIDIA Jarvis。导出格式有三种:PyTorch、TorchScript或ONNX。Jarvis通过导入模型生成TensorRT 引擎并准备高性能的、生产就绪型推理模型,在Jarvis中使用TensorRT进行推理,在这一过程中可通过将模型量化为INT8来实现吞吐量的最大化。
NGC中的预训练模型
NGC 中有几种预训练模型可用于ASR、NLP和TTS,例如Jasper、QuartzNet、BERT以及Tacotron2和WaveGlow。这些模型经过了数千小时开源数据和专有数据的训练,具有很高的精度,并且需要在 DGX 系统上训练超过10万小时。
这些预训练模型基于多个开源和商业数据集构建,例如LibriSpeech、Mozilla Common Voice、AI-shell2 Mandarin Chinese、Wikipedia、BookCorpus和LJSpeech。这些数据集能够帮助模型更加深入地了解上下文,使它们可以在实时用例中有效运行。
所有预训练模型都可支持下载,并且这些模型的代码都是开源的,因此用户可以使用自己的数据集训练模型,甚至可以在基础架构上构建新的模型。用户还可以使用NGC 中有现成的模型脚本和容器对其用例进行模型微调。
作为一位研究者,如果想构建最新的语音和语言模型,其必须能够快速地对新型网络架构进行实验。此类实验有可能会侧重于通过修改现有网络架构提高性能,也可能会是通过将语音和语言模型合并,以构建端到端应用的高级实验。
此类工作通常始于研究示例代码和模型库中的预训练模型始。但是通过这种方式来复用代码和预训练模型可能会较为棘手。
这些模型中的输入和输出、编码样式以及数据处理层可能彼此不兼容。更糟糕的情况是,也许用户可以在其代码中连接这些模型,使其在技术上“有效”,但实际情况却是这些模型存在着语义错误。用户需要花费大量的时间、精力和重复的代码,来确保模型可以安全地重复使用。
而随着模型复杂性和模型复用的增加,这种方法将不再有效。
现在我们将这种方法和构建复杂软件应用的方法相对比。复杂软件应用的发展历程是一个抽象层次不断提高的过程:从机器代码到汇编语言,再到到具有编译器和类型系统的结构化编程,面向对象编程。这些高级工具带来了更好的保护和代码重用性。
深度学习库也经历了类似的发展历程,CUDA和cuDNN等底层工具能够提供出色的性能,TensorFlow能为人力成本花销提供高度的灵活性。但Keras和PyTorch等高级存储库的主要对象仍是tensor张量、简易操作和层。
NVIDIA NeMo介绍
NVIDIA NeMo是一个带有PyTorch后端的开源套件,它能够进一步提高抽象层次。NeMo使用户可以使用可重用的组件轻松地建立复杂的神经网络架构。利用神经类型,这些组件之间会自动进行语义兼容性检查。
NeMo能够利用NVIDIA GPU上的Tensor Core核心,通过混合精度计算来获得最高性能。其包括了将训练扩展到多GPU系统和多节点集群的功能。
图1:NeMo应用堆栈
该套件的核心是神经模块概念。神经模块会获得一组输入后,计算出一组输出。用户可以将其视为介于层和整个神经网络之间某处的一个抽象。通常一个模块对应神经网络的一个概念部分,例如编码器、解码器或语言模型。
神经模块的输入和输出都具有神经类型,包括语义、Axis次序和输入/输出tensor张量的维数。这一归类使得NeMo可以安全地链接在一起,组成应用,比如在下文中所演示的的自动语音识别(ASR)示例。
NeMo还带有用于ASR、NLP和TTS的可扩展模块集合。此类集合为数据加载、预处理,和训练不同的网络结构(包括Jasper、BERT、Tacotron 2和WaveGlow)提供了API操作。用户还可以基于自定义数据集,使用NVIDIA NGC中的预训练模型进行模型微调。
该套件是为解决NVIDIA应用研究团队所面临的挑战而设计的。NVIDIA希望通过将此项目开源,来和整个语音、NLP和TTS研究者社区分享此项成果,并促进彼此之间的合作。
建立新模型
接下来将通过建立一个简单的ASR模型来说明如何使用NeMo。你将了解神经类型如何提供语义安全检查,以及如何以最轻松的方式将此工具横向扩展到多个GPU。
入门
NVIDIA/NeMo GitHub存储库概括列举了一般性要求和安装说明。该存储库提供了多种NeMo安装方式:
使用1个NGC容器
使用软件包管理器(pip)命令:pip install nemo_toolkit_[all/asr/nlp/tts]。软件包管理器能够让用根据其指定的集合(例如asr、nlp或tts)安装单个NeMo软件包。
使用可用于构建Docker镜像的Dockerfile 并且可以直接运行NeMo安装。
使用端到端自动语音识别介绍:Jupyter笔记本中的Jupyter笔记本示例了解如何在NeMo中使用pip命令设置环境并训练Jasper ASR模型。
Jasper
在此ASR示例中,用户将使用到一个名为Jasper的网络。Jasper是一个端到端的ASR模型,它无需任何附加对齐信息就能转录语音样本。更多信息,请参见Jasper:端到端卷积神经声学模型。
该模型的训练处理流程包括以下模块。每个逻辑块都对应一个神经模块。
图2 Jasper语音识别管道
Jupyter笔记本
在Jupyter笔记本中构建模型的步骤如下:
将必要的神经模块实例化。
描述这些神经模块的DAG
调用一个操作,例如训练。
这里的步骤很少,这是因为用户此时所采用的是更高层次的抽象
有关ASR介绍和逐步操作步骤,请参见端对端自动语音识别介绍:Jupyter笔记本。
基于自定义数据集微调模型
在使用预训练模型基于自定义数据构建高精度模型的过程中,微调起到了重要作用。这属于一种迁移学习技术。迁移学习能够将一项任务中所获得的知识迁移,转而应用于另一项类似任务的执行当中。
NGC中有几种预训练模型,用户会在启用NeMo微调用例时用到它们。接下来的部分对此进行更详细的介绍。若要了解如何通过示例微调模型,请参见通过NeMo快速启动不同语言的语音识别模型训练。
NeMo仅需一行代码就可将模型导出至 NVIDIA Jarvis。导出格式有三种:PyTorch、TorchScript或ONNX。Jarvis通过导入模型生成TensorRT 引擎并准备高性能的、生产就绪型推理模型,在Jarvis中使用TensorRT进行推理,在这一过程中可通过将模型量化为INT8来实现吞吐量的最大化。
NGC中的预训练模型
NGC 中有几种预训练模型可用于ASR、NLP和TTS,例如Jasper、QuartzNet、BERT以及Tacotron2和WaveGlow。这些模型经过了数千小时开源数据和专有数据的训练,具有很高的精度,并且需要在 DGX 系统上训练超过10万小时。
这些预训练模型基于多个开源和商业数据集构建,例如LibriSpeech、Mozilla Common Voice、AI-shell2 Mandarin Chinese、Wikipedia、BookCorpus和LJSpeech。这些数据集能够帮助模型更加深入地了解上下文,使它们可以在实时用例中有效运行。
所有预训练模型都可支持下载,并且这些模型的代码都是开源的,因此用户可以使用自己的数据集训练模型,甚至可以在基础架构上构建新的模型。用户还可以使用NGC 中有现成的模型脚本和容器对其用例进行模型微调。











