
如何使用 NVIDIA Jetson 和 Amazon SageMaker 结合打造智能边缘
2020-05-21 18:22
 分享到微信
分享到微信
 分享到微博
分享到微博
随着物联网和 AI 芯片的发展,未来将会有越来越多的数据在边缘侧处理。很多业务场景已经对边缘智能提出了明确的需求,比如自动驾驶的汽车每天会产生 5TB 的数据,而智能工厂每天产生的数据高达 1PB ,其中包含视频和传感器的数据。如果不能借助边缘智能技术而依靠 Internet 网络把数据传输至云端处理,会造成网络延迟和拥塞,影响推理结果的实时性,造成生产事故甚至于安全事故。
利用 NVIDIA Jetson 和 Amazon SageMaker 平台通过使用云+端结合的方式,我们将打造一个边缘智能的方案(整体方案架构如下)。
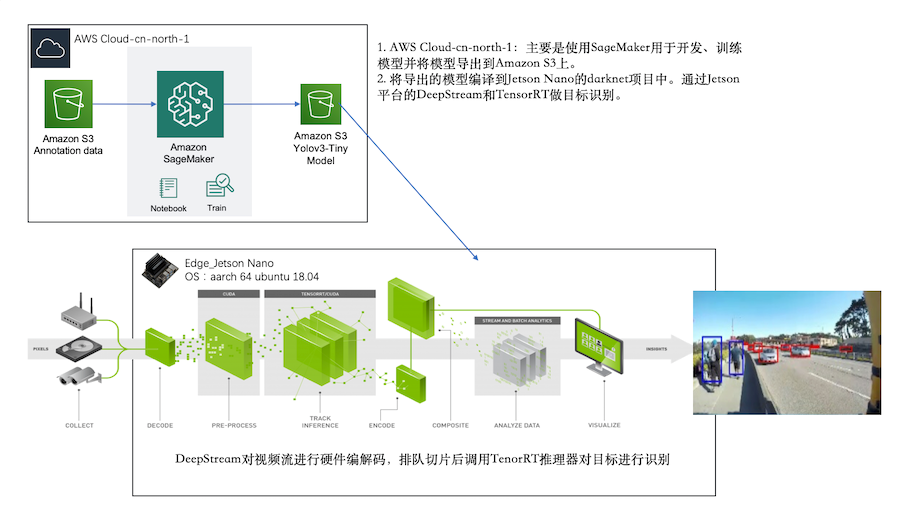
在正式了解 Amazon SageMaker 和 NVIDIA Jetson 和平台前,我们先了解一下什么是目标检测和 YOLO 。
目标检测与 YOLO
(You Only Look Once)
目标检测是计算机视觉中的一个重要分支,但由于在边缘设备或移动端中部署神经网络模型需要很大的算力或 GPU 处理能力。近年来由于边缘 AI 芯片的算力增强,再加上边缘智能有着更广泛的应用场景,围绕机器学习模型在边缘设备上的高效应用等研究课题逐步火热。
目前在目标检测领域的深度学习方法主要分为两类:一类是 two stage 的目标检测算法;另外一类是 one stage的目标检测算法。
前者是先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类;后者 one stage 则不用产生候选框,直接将目标边框定位的问题转化为回归问题处理。正是由于两种方法的差异,在性能表现上也有不同,前者在检测准确率和定位精度上占优,而后者在算法推理速度上占优。最近很多 AI 公司都在做是否戴口罩的识别,实际上也是基于这两类方法。精度与速度往往在目标检测中是零和博弈,我们通过实践将两者平衡,以获得最大收益。
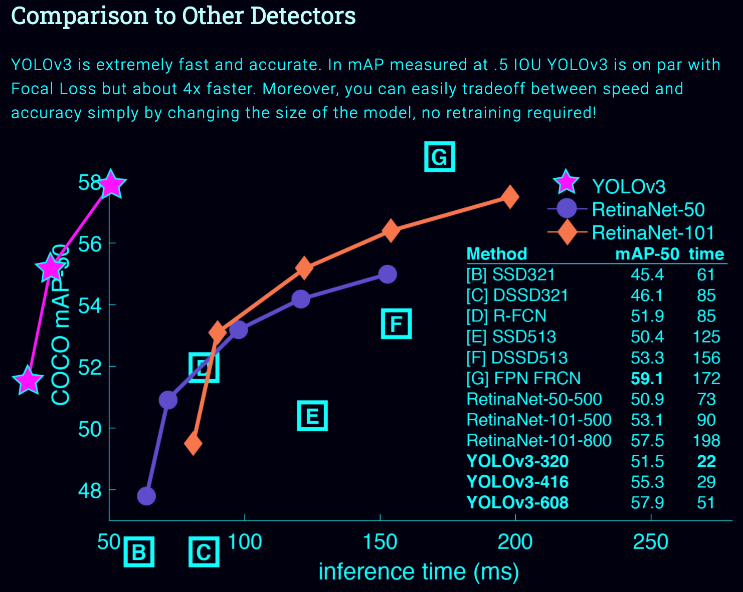
YOLO v3 是目标检测经典模型 YOLO 的第三代版本,因其目标识别的速度很快,被业内称为边缘的目标检测之光,它由目标检测领域的经典论文 YOLO (You Only Look Once)的两位作者——华盛顿大学的Joseph Redmon和Ali Farhadi创作。2018 年 9 月,YOLO v3 正式发布,下图是从 Focal Loss 论文中可以看出 YOLOv3 的运行速度明显快于其他性能相似的检测方法。而 Yolo V3 Tiny,是为满足嵌入式应用的场景而发布,现已成为很流行的目标检测算法,目前在主流 AI 芯片公司的产品中均有应用。在工业场景中做缺陷检测或在大众消费领域中的新零售、智能驾驶等均得到广泛的推广。关于 YOLO 的具体介绍和说明请参考:https://pjreddie.com/darknet/yolo/
Amazon SageMaker
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 (ML) 模型。SageMaker 完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。传统的 ML 开发是一个复杂、昂贵、迭代的过程,而且没有任何集成工具可用于整个机器学习工作流程,这让它难上加难。我们需要将工具和工作流程拼接在一起,这既耗时又容易出错。SageMaker 在单个工具集中提供了用于机器学习的所有组件,让这一难题迎刃而解,因此模型将可以通过更少的工作量和更低的成本更快地投入生产。

做训练最重要的是数据集,需要注意 darknet 的数据集的标注格式是 txt,我们要按照 PASCAL VOC 的目录结构去做图像标注,通过脚本将 xml 格式转换为txt格式的标签,结构与注释如下:

训练结束后我们会得到一个模型文件 weight,下一步就是如何将模型文件部署到边缘智能的开发板 NVIDIA Jetson Nano,并且通过 NVIDIA 的 TensorRT 和 DeepStream 来进行推理加速。
下面这一部分主要完成的就是设备端的工作,主要的步骤是:
Jetson Nano 环境部署
将 Sagemaker 训练的模型部署到 Jetson Nano 上
测试
Jetson 的环境部署
这里会使用到 NIVIDA 的硬件与平台相关的组件主要有:
Jetson Nano
Jetson Nano Developer Kit SD Card image
JetPack SDK
NVIDIA TensorRT
DeepStream
Run Sample Code
由于博客篇幅原因,我们先概况了解一下,具体可以参考后面的链接。
Jetson Nano
首先就是我们需要一个边缘智能的开发板 NVIDIA Jetson Nano,虽然是入门级,但是足以应对大部分要求算力不高的场景。Jetson Nano 介绍参考:
https://developer.nvidia.com/embedded/jetson-nano-developer-kit

Jetson Nano Developer Kit SD Card image
因为Jetson Nano的系统是内核是tegra-ubuntu 4.9.140-tegra aarch64架构,所以NVIDIA给了我们一个microSD card的镜像来烧录到板子上,但由于推理框架、库、软件、驱动等等都要遵循其架构。就导致了如果没有一个好的工具,构建一个边缘推理的环境极其复杂。所以就有了JetPack和SDK Manager。镜像烧录参考:
https://developer.nvidia.com/embedded/learn/get-started-jetson-nano-devkit#write
JetPack SDK
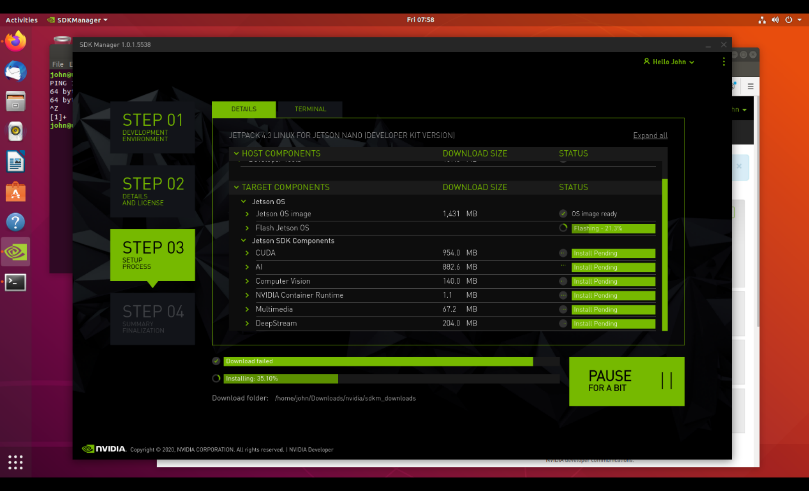
NIVIDA JetPack 可以实现在 Jetson 平台上快速构建机器学习环境,JetPack 包括系统镜像、TensorRT、CUDA、各种库和 API、开发工具、和示例代码。我们可以利用 SDK Manager 来安装Jetson的软件环境,SDK Manager 要需要安装到一台 Ubuntu Host 主机上,然后由它来打包和推送环境到 Jetson Nano 上。
在使用 SDK Manager 部署环境之前,我们要确认完成以下工作:
--- Jetson Nano 必须先通过 MicroSD 卡成功启动进入 Ubuntu 界面
--- 采用 Micro USB 链接 Nano 到 Ubuntu Host (这里需要注意的是 Host 主机如果使用虚拟机,一定要添加 USB 控制器,如果你启用 USB2.0 就链接 HOST 主机的时候使用 2.0,同理 3.0 也是一样)
--- Nano 连接网线到外网,且与 Ubuntu Host机器在一局域网内(Host主机如果使用虚拟机,请使用桥接模式。)
然后部署安装,部署时间取决于你 Host 主机的配置和网络情况,烧录过程中会弹出 Jetson nano 的 root 认证。具体步骤参考:
https://docs.nvidia.com/sdk-manager/install-with-sdkm-jetson/index.html#install-with-sdkm-jetson
NVIDIA TensorRT
NVIDIA TensorRT 是 NVIDIA 推出的深度学习推理的框架,也可以理解为一个优化器。它能够以更低延迟、高吞吐率来部署推理模型到嵌入式平台。这个框架可以将 Caffe,TensorFlow 的网络模型解析,然后与 TensorRT 中对应的层进行一一映射,把其他框架的模型统一全部转换到 TensorRT 中,然后在 TensorRT 中可以针对NVIDIA 自家的 GPU 实施优化策略,并进行部署加速。TensorRT 已经能够支持 TensorFlow、Caffe、Mxnet、Pytorch、Darknet 等深度学习框架,这里我们用到的正是基于Darknet的Yolo。TensorRT可以直接解析他们的网络模型;对于caffe2,pytorch,mxnet等框架则是首先要将模型转为 ONNX 的通用深度学习模型,然后对 ONNX模型做解析。而 Tensorflow 和 MATLAB 已经将 TensorRT 集成到框架中去了。具体参考:
https://developer.nvidia.com/tensorrt

DeepStream
NVIDIA DeepStream SDK 提供了完整的流分析工具包,可用于基于 AI 的视频和图像分析。实时分析来自摄像头或传感器或物联网网关的数据。底层基于 GStreamer 实现低延迟和高吞吐量。还可以将消息代理如 Kafka 和 MQTT 将边缘集成到云中。在 NVIDIA 平台上的设备上可以加速 H.264 和 H.265 视频解码 ,来构建端到端 AI 驱动的应用程序比如:零售分析,停车管理,物流管理,光学检查和缺陷检测等。具体参考:
https://developer.nvidia.com/deepstream-sdk
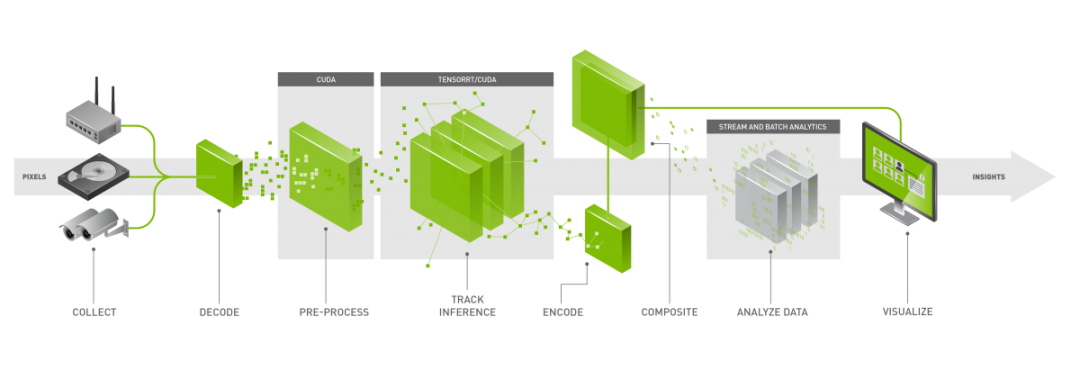
Jetson Nano 可实时处理多达 8 个高清全运动视频流,可作为用于网络录像机 (NVR)、智能摄像机和 IoT 网关的低功耗边缘智能视频分析平台进行部署。NVIDIA 的 DeepStream SDK 使用 ZeroCopy 和 TensorRT 优化端到端推断管道,以实现边缘和本地服务器的终极性能。下图就是我跑的示例代码,显示 Jetson Nano 在 8 个 1080p 流上执行物体检测,同时基于 ResNet 的模型以全分辨率运行,吞吐量为 500MP/s,解码率为 500 MP/s (H.264/H.265)和视频编码率(250 MP/s)H.264/H.265. 具体请参考链接:
https://devblogs.nvidia.com/jetson-nano-ai-computing/

Run Sample Code
这一点很重要,我们要先把示例代码跑通。
当我们通过 SDK Manager 将 DeepStream 成功烧录系统后,在路径在opt:/opt/nvidia/deepstream/deepstream-4.0/samples/configs/deepstream-app/ 运行nano.txt 的Demo code,如果运行成功,那么 Jetson Nano 平台的推理环境就部署成功了。步骤 5 就是我们通过 DeepStream 的 Demo code 运行成功的截图。
将 Sagemaker 训练好的模型部署到
Jetson Nano 上
首先找到在 Sagemaker 上定义好的 output_path,将 S3 上的模型文件导出到 Jetson Nano 上。解压后的模型文件比如 yolov3-tiny-xxx.weights。

这个时候把模型导入到 Jetson Nano 上是不能直接运行的。即使直接运行也没有通过 TensorRT 和 DeepStream 做优化和加速,Jetson Nano 上如果不使用 TensorRT 加速,则会大大降低 yolo 的推理速度,例如yolo v3<1fps,yolov3 tiny<8fps,所以需要以下三步操作:
1、跑通 deepstream_reference_apps的yolov3-tiny应用
2、交叉编译
3、参数修改
测试
最终,测试我们的程序即可。
其实整个实验过程还是比较久的,由于篇幅原因我们不会扩展开每一个步骤的实现方法,这里先抛个最终实现的效果图。这个就是通过云端的 Sagemaker 服务做训练然后通过 NVIDIA 的 TensorRT 和 DeepStream 实现实时的目标检测。

边缘智能随着低功耗和低成本的 AI 芯片普及,越来越多的企业关注智联网这个领域。边缘智能正在促成人工智能(AI)与物联网(IoT)的融合,AI 与 IoT 相辅相成:如果没有 AI ,IoT 只是收集数据的 sensor,如果没有 IoT,AI 也不会应用到边缘。AIoT 项目确实比其他单纯的一个软件或硬件的研发更加复杂,它是多学科或技术栈的融合。比如,数据的采集、分析、展现需要大数据相关的技术,边缘逻辑的推理、判断需要应用机器学习的模型,对数据加工后又要与大数据结合去 ETL 。云端的逻辑编写、OTA 升级、安全设计、设备管理也要与终端集成。另外,如果是视频流交互还涉及到编解码、流媒体等技术。
正是因为它的复杂性,我们在云端训练,在边缘推理,既利用云计算提供的服务和接口来快速原型和开发,又利用 NVIDIA 提供的 Jetson 平台,在边缘侧加速推理,提高边缘侧算力的利用率。
利用 NVIDIA Jetson 和 Amazon SageMaker 平台通过使用云+端结合的方式,我们将打造一个边缘智能的方案(整体方案架构如下)。
在正式了解 Amazon SageMaker 和 NVIDIA Jetson 和平台前,我们先了解一下什么是目标检测和 YOLO 。
目标检测与 YOLO
(You Only Look Once)
目标检测是计算机视觉中的一个重要分支,但由于在边缘设备或移动端中部署神经网络模型需要很大的算力或 GPU 处理能力。近年来由于边缘 AI 芯片的算力增强,再加上边缘智能有着更广泛的应用场景,围绕机器学习模型在边缘设备上的高效应用等研究课题逐步火热。
目前在目标检测领域的深度学习方法主要分为两类:一类是 two stage 的目标检测算法;另外一类是 one stage的目标检测算法。
前者是先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类;后者 one stage 则不用产生候选框,直接将目标边框定位的问题转化为回归问题处理。正是由于两种方法的差异,在性能表现上也有不同,前者在检测准确率和定位精度上占优,而后者在算法推理速度上占优。最近很多 AI 公司都在做是否戴口罩的识别,实际上也是基于这两类方法。精度与速度往往在目标检测中是零和博弈,我们通过实践将两者平衡,以获得最大收益。
YOLO v3 是目标检测经典模型 YOLO 的第三代版本,因其目标识别的速度很快,被业内称为边缘的目标检测之光,它由目标检测领域的经典论文 YOLO (You Only Look Once)的两位作者——华盛顿大学的Joseph Redmon和Ali Farhadi创作。2018 年 9 月,YOLO v3 正式发布,下图是从 Focal Loss 论文中可以看出 YOLOv3 的运行速度明显快于其他性能相似的检测方法。而 Yolo V3 Tiny,是为满足嵌入式应用的场景而发布,现已成为很流行的目标检测算法,目前在主流 AI 芯片公司的产品中均有应用。在工业场景中做缺陷检测或在大众消费领域中的新零售、智能驾驶等均得到广泛的推广。关于 YOLO 的具体介绍和说明请参考:https://pjreddie.com/darknet/yolo/
Amazon SageMaker
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 (ML) 模型。SageMaker 完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。传统的 ML 开发是一个复杂、昂贵、迭代的过程,而且没有任何集成工具可用于整个机器学习工作流程,这让它难上加难。我们需要将工具和工作流程拼接在一起,这既耗时又容易出错。SageMaker 在单个工具集中提供了用于机器学习的所有组件,让这一难题迎刃而解,因此模型将可以通过更少的工作量和更低的成本更快地投入生产。
做训练最重要的是数据集,需要注意 darknet 的数据集的标注格式是 txt,我们要按照 PASCAL VOC 的目录结构去做图像标注,通过脚本将 xml 格式转换为txt格式的标签,结构与注释如下:
训练结束后我们会得到一个模型文件 weight,下一步就是如何将模型文件部署到边缘智能的开发板 NVIDIA Jetson Nano,并且通过 NVIDIA 的 TensorRT 和 DeepStream 来进行推理加速。
下面这一部分主要完成的就是设备端的工作,主要的步骤是:
Jetson Nano 环境部署
将 Sagemaker 训练的模型部署到 Jetson Nano 上
测试
Jetson 的环境部署
这里会使用到 NIVIDA 的硬件与平台相关的组件主要有:
Jetson Nano
Jetson Nano Developer Kit SD Card image
JetPack SDK
NVIDIA TensorRT
DeepStream
Run Sample Code
由于博客篇幅原因,我们先概况了解一下,具体可以参考后面的链接。
Jetson Nano
首先就是我们需要一个边缘智能的开发板 NVIDIA Jetson Nano,虽然是入门级,但是足以应对大部分要求算力不高的场景。Jetson Nano 介绍参考:
https://developer.nvidia.com/embedded/jetson-nano-developer-kit
Jetson Nano Developer Kit SD Card image
因为Jetson Nano的系统是内核是tegra-ubuntu 4.9.140-tegra aarch64架构,所以NVIDIA给了我们一个microSD card的镜像来烧录到板子上,但由于推理框架、库、软件、驱动等等都要遵循其架构。就导致了如果没有一个好的工具,构建一个边缘推理的环境极其复杂。所以就有了JetPack和SDK Manager。镜像烧录参考:
https://developer.nvidia.com/embedded/learn/get-started-jetson-nano-devkit#write
JetPack SDK
NIVIDA JetPack 可以实现在 Jetson 平台上快速构建机器学习环境,JetPack 包括系统镜像、TensorRT、CUDA、各种库和 API、开发工具、和示例代码。我们可以利用 SDK Manager 来安装Jetson的软件环境,SDK Manager 要需要安装到一台 Ubuntu Host 主机上,然后由它来打包和推送环境到 Jetson Nano 上。
在使用 SDK Manager 部署环境之前,我们要确认完成以下工作:
--- Jetson Nano 必须先通过 MicroSD 卡成功启动进入 Ubuntu 界面
--- 采用 Micro USB 链接 Nano 到 Ubuntu Host (这里需要注意的是 Host 主机如果使用虚拟机,一定要添加 USB 控制器,如果你启用 USB2.0 就链接 HOST 主机的时候使用 2.0,同理 3.0 也是一样)
--- Nano 连接网线到外网,且与 Ubuntu Host机器在一局域网内(Host主机如果使用虚拟机,请使用桥接模式。)
然后部署安装,部署时间取决于你 Host 主机的配置和网络情况,烧录过程中会弹出 Jetson nano 的 root 认证。具体步骤参考:
https://docs.nvidia.com/sdk-manager/install-with-sdkm-jetson/index.html#install-with-sdkm-jetson
NVIDIA TensorRT
NVIDIA TensorRT 是 NVIDIA 推出的深度学习推理的框架,也可以理解为一个优化器。它能够以更低延迟、高吞吐率来部署推理模型到嵌入式平台。这个框架可以将 Caffe,TensorFlow 的网络模型解析,然后与 TensorRT 中对应的层进行一一映射,把其他框架的模型统一全部转换到 TensorRT 中,然后在 TensorRT 中可以针对NVIDIA 自家的 GPU 实施优化策略,并进行部署加速。TensorRT 已经能够支持 TensorFlow、Caffe、Mxnet、Pytorch、Darknet 等深度学习框架,这里我们用到的正是基于Darknet的Yolo。TensorRT可以直接解析他们的网络模型;对于caffe2,pytorch,mxnet等框架则是首先要将模型转为 ONNX 的通用深度学习模型,然后对 ONNX模型做解析。而 Tensorflow 和 MATLAB 已经将 TensorRT 集成到框架中去了。具体参考:
https://developer.nvidia.com/tensorrt
DeepStream
NVIDIA DeepStream SDK 提供了完整的流分析工具包,可用于基于 AI 的视频和图像分析。实时分析来自摄像头或传感器或物联网网关的数据。底层基于 GStreamer 实现低延迟和高吞吐量。还可以将消息代理如 Kafka 和 MQTT 将边缘集成到云中。在 NVIDIA 平台上的设备上可以加速 H.264 和 H.265 视频解码 ,来构建端到端 AI 驱动的应用程序比如:零售分析,停车管理,物流管理,光学检查和缺陷检测等。具体参考:
https://developer.nvidia.com/deepstream-sdk
Jetson Nano 可实时处理多达 8 个高清全运动视频流,可作为用于网络录像机 (NVR)、智能摄像机和 IoT 网关的低功耗边缘智能视频分析平台进行部署。NVIDIA 的 DeepStream SDK 使用 ZeroCopy 和 TensorRT 优化端到端推断管道,以实现边缘和本地服务器的终极性能。下图就是我跑的示例代码,显示 Jetson Nano 在 8 个 1080p 流上执行物体检测,同时基于 ResNet 的模型以全分辨率运行,吞吐量为 500MP/s,解码率为 500 MP/s (H.264/H.265)和视频编码率(250 MP/s)H.264/H.265. 具体请参考链接:
https://devblogs.nvidia.com/jetson-nano-ai-computing/
Run Sample Code
这一点很重要,我们要先把示例代码跑通。
当我们通过 SDK Manager 将 DeepStream 成功烧录系统后,在路径在opt:/opt/nvidia/deepstream/deepstream-4.0/samples/configs/deepstream-app/ 运行nano.txt 的Demo code,如果运行成功,那么 Jetson Nano 平台的推理环境就部署成功了。步骤 5 就是我们通过 DeepStream 的 Demo code 运行成功的截图。
将 Sagemaker 训练好的模型部署到
Jetson Nano 上
首先找到在 Sagemaker 上定义好的 output_path,将 S3 上的模型文件导出到 Jetson Nano 上。解压后的模型文件比如 yolov3-tiny-xxx.weights。
这个时候把模型导入到 Jetson Nano 上是不能直接运行的。即使直接运行也没有通过 TensorRT 和 DeepStream 做优化和加速,Jetson Nano 上如果不使用 TensorRT 加速,则会大大降低 yolo 的推理速度,例如yolo v3<1fps,yolov3 tiny<8fps,所以需要以下三步操作:
1、跑通 deepstream_reference_apps的yolov3-tiny应用
2、交叉编译
3、参数修改
测试
最终,测试我们的程序即可。
其实整个实验过程还是比较久的,由于篇幅原因我们不会扩展开每一个步骤的实现方法,这里先抛个最终实现的效果图。这个就是通过云端的 Sagemaker 服务做训练然后通过 NVIDIA 的 TensorRT 和 DeepStream 实现实时的目标检测。
边缘智能随着低功耗和低成本的 AI 芯片普及,越来越多的企业关注智联网这个领域。边缘智能正在促成人工智能(AI)与物联网(IoT)的融合,AI 与 IoT 相辅相成:如果没有 AI ,IoT 只是收集数据的 sensor,如果没有 IoT,AI 也不会应用到边缘。AIoT 项目确实比其他单纯的一个软件或硬件的研发更加复杂,它是多学科或技术栈的融合。比如,数据的采集、分析、展现需要大数据相关的技术,边缘逻辑的推理、判断需要应用机器学习的模型,对数据加工后又要与大数据结合去 ETL 。云端的逻辑编写、OTA 升级、安全设计、设备管理也要与终端集成。另外,如果是视频流交互还涉及到编解码、流媒体等技术。
正是因为它的复杂性,我们在云端训练,在边缘推理,既利用云计算提供的服务和接口来快速原型和开发,又利用 NVIDIA 提供的 Jetson 平台,在边缘侧加速推理,提高边缘侧算力的利用率。











