
黄仁勋介绍基于NVIDIA Ampere架构首支NVIDIA A100 GPU
2020-05-16 08:31
 分享到微信
分享到微信
 分享到微博
分享到微博
就在刚刚,NVIDIA提出了下一代计算的愿景,该愿景将全球信息经济的重心从服务器转移到了新型的强大且灵活的数据中心。
NVIDIA创始人兼首席执行官黄仁勋在其加州住宅的厨房中录制的六集同时发布的主题演讲中,介绍了NVIDIA最近对Mellanox的收购,还有重盼所归的基于NVIDIA Ampere GPU架构的新产品以及重要的最新软件技术。

这场主题演讲原计划于3月底在圣何塞举行的NVIDIA GPU技术大会上现场直播,但因冠状病毒疫情而受到影响。
“我要感谢正前线抗击COVID-19所有勇敢的战士们。”黄仁勋在开场时说到,“NVIDIA正在与研究人员和科学家合作,使用GPU和AI计算来治疗、缓解、控制和追踪这种大规模传染性疾病。”
NVIDIA也宣布了其NVIDIA Clara医疗平台的更新,旨在对抗COVID-19新型冠状病毒。
“研究人员和科学家们正在使用NVIDIA加速计算来挽救生命——这完美地诠释了我们公司的宗旨:通过制造计算机,解决普通计算机不能解决的问题。”黄仁勋说。
演讲主要围绕作为现代全球信息经济机房的数据中心如何变化,以及在上月完成交易的收购案双方NVIDIA和Mellanox如何共同推动这些变化的愿景。

“数据中心是新的计算单元,NVIDIA正在加速从芯片到CPU和GPU的连接方式,再到整个软件堆栈,以及最终跨整个数据中心的性能提升。”
数据中心规模计算的系统优化
首先,NVIDIA为这种新型的数据中心规模计算优化了新的GPU架构,集AI训练和推理于一身,并实现了灵活且弹性的加速。
NVIDIA A100是第一个基于NVIDIA Ampere架构的GPU,提供了在NVIDIA八代GPU里最大的性能提升,它还可用于数据分析,科学计算和云图形,并已全面投产并交付给全球客户。

全球18家领先的服务提供商和系统构建商正在将NVIDIA A100整合到他们的服务和产品中,其中包括阿里云、AWS、百度云、思科、Dell Technologies、Google Cloud、HPE、Microsoft Azure和甲骨文。
相比上一代,NVIDIA Ampere架构的A100将性能提升了20倍。A100的五大关键特性包括:
---- 超过540亿个晶体管,使其成为世界上最大的7纳米处理器
---- 带有TF32的第三代Tensor Core核心,这是一种新的数值格式,可加速开箱即用的单精度AI训练。NVIDIA广泛使用的Tensor Core现在更加灵活,快速,且更易于使用
---- 结构稀疏性(Structural sparsity)加速,这是一种新的高效技术,可以利用AI数学固有的稀疏性来获得更高的性能
--- 多实例GPU(Multi-instance GPU或MIG),允许将一个A100分割为多达七个独立的GPU,每个GPU都有自己的资源
----第三代NVLink技术,使GPU之间的高速联接能力加倍,从而可以使多个A100服务器充当一个巨型GPU
以上这些特性促成了A100性能的提升:与NVIDIA上一代的Volta架构相比,训练性能提高了6倍,推理性能提高了7倍。
NVIDIA DGX A100具备5 Petaflops的性能
NVIDIA还将发售第三代NVIDIA DGX AI系统—基于NVIDIA A100的NVIDIA DGX A100—世界上第一台5 petaflops服务器。每台DGX A100可以分割为多达56个独立运行的实例。

这使得单个服务器可以“纵向扩展”以完成诸如AI训练之类的计算密集型任务,或者“横向扩展”以进行AI部署或推理。
该系统的最初使用者是美国能源部的阿贡国家实验室,该实验室将利用该集群的AI和计算能力更好地理解和对抗COVID-19。此外,还有佛罗里达大学和德国人工智能研究中心。

美国能源部阿贡国家实验室,将使用DGX A100赋能的AI和算力更好地了解并抗击COVID-19
A100也将作为HGX A100提供给云合作伙伴和服务器制造商。
一套由五台DGX A100系统提供动力的数据中心,其成本仅为100万美元,功耗仅为28千瓦,但其性能足以媲美一套典型数据中心(由50台用于AI训练的DGX-1系统和600个总功耗高达630千瓦的CPU系统构成,成本超过1100万美元)。
NVIDIA还宣布了下一代DGX SuperPOD。它由140台DGX A100系统和Mellanox网络技术搭建而成,可提供700 petaflops的AI性能,堪比全球20台最快的计算机中的任何一台。

新一代DGX SuperPOD实现了强达每秒70 petaflops的AI算力
NVIDIA正在用四个DGX SuperPOD来扩展自己的数据中心,为其内部超级计算机SATURNV,增加了2.8 exaflops的AI计算能力(总计4.6 exaflops),使其成为世界上最快的AI超级计算机。
NVIDIA同时也发布了NVIDIA EGX A100,将强大的实时云计算功能带到了边缘。其NVIDIA Ampere架构GPU提供了第三代Tensor Core和新的安全功能。得益于其NVIDIA Mellanox ConnectX-6 SmartNIC,它还具有安全且快速的联网功能。

当今世界上最重要的应用软件
NVIDIA GPU将为主要软件应用程序提供动力,以加速三个关键用途:管理大数据,创建推荐系统和构建实时会话式AI。
随着机器学习的有效性推动公司收集了越来越多的数据,这些新工具应运而生。积极的反馈使我们体验到的数据收集量呈指数级增长。
为了帮助各类组织顺应潮流,NVIDIA宣布在Spark 3.0上支持NVIDIA GPU加速,大数据分析将成为当今世界上最重要的应用程序之一。
基于RAPIDS的Spark 3.0,打破了提取,转换和加载数据的性能基准。它已经帮助Adobe Intelligent Services将计算成本降低了90%。
关键的云分析平台(包括Amazon SageMaker,Azure Machine Learning,Databricks,Google Cloud AI和Google Cloud Dataproc)都将借助NVIDIA加速。
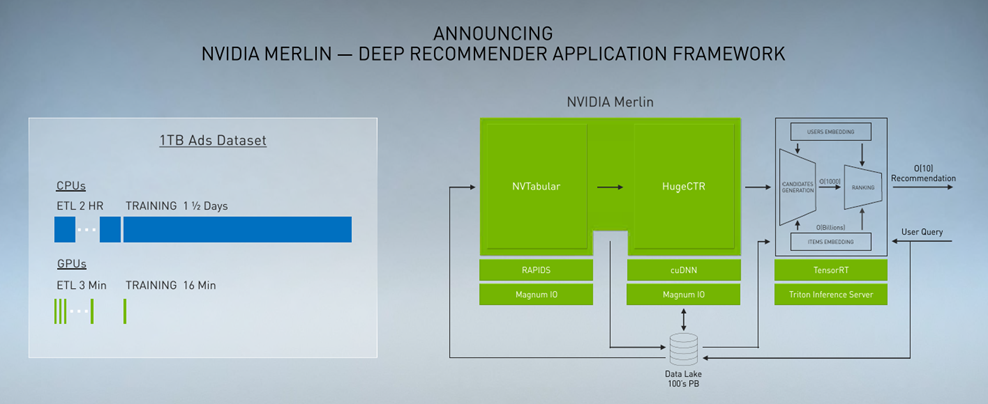
黄仁勋还宣布推出了NVIDIA Merlin,这是一个用于构建下一代推荐系统的端到端框架,该系统正迅速成为更加个性化互联网的引擎。Merlin将创建一个100 TB数据集推荐系统所需的时间从四天减少到20分钟。
他还详细介绍了NVIDIA Jarvis,这是一个新的端到端平台,可以充分发挥NVIDIA AI平台的强大功能,创建实时多模态对话式AI。

他通过一个演示来展示了与名为Misty的AI进行交互的过程,Misty可实时理解并回答一系列有关天气的复杂问题。
自2018年在SIGGRAPH上发布NVIDIA RTX以来,NVIDIA在实时光线追踪方面取得了迅猛发展,当时宣布的NVIDIA Omniverse可以让位于不同地方使用不同工具的设计师,在同个设计的不同部分同时工作。现在已经可供抢先体验客户使用。
自动驾驶汽车
自动驾驶汽车是我们这个时代最大的计算挑战之一,NVIDIA将持续通过NVIDIA DRIVE推动整个行业发展。

NVIDIA DRIVE将使用全新Orin SoC和NVIDIA Ampere GPU,以实现能效和性能,入门级ADAS系统开发所需功率仅需5瓦,并为L5级别robotaxi系统提供2,000 TOPS的性能。
现在,汽车制造商仅需单一计算架构和软件堆栈,即可将AI集成到每一辆车中。汽车制造商可以利用一种架构来开发整个车队,并利用整个车队来进行软件开发。
NVIDIA DRIVE生态系统现已覆盖汽车、卡车、一级汽车供应商、下一代出行服务、初创公司、地图服务和仿真。NVIDIA将在NVIDIA DRIVE技术套件中增加用于管理整个自动驾驶车队的NVIDIA DRIVE RC。
机器人技术
NVIDIA还将继续推进其NVIDIA Isaac软件定义的机器人平台,宣布宝马集团已选择NVIDIA Isaac机器人技术为其下一代工厂提供动力。

每56秒钟,宝马集团在全球的30家工厂就会生产一辆汽车:40种不同型号的汽车,每种都有数百种不同的选择,3000万个零件来自全球近2,000家供应商。

宝马集团加入了一个庞大的NVIDIA机器人技术全球生态系统,该生态系统涵盖配送、零售、自主移动机器人、农业、服务业、物流、制造和医疗保健。
未来,工厂实际上将成为巨大的机器人。“里面的所有运动部件都会由AI驱动。”黄仁勋说。“将来,每个批量生产的产品都将被逐一量身定制。”
NVIDIA创始人兼首席执行官黄仁勋在其加州住宅的厨房中录制的六集同时发布的主题演讲中,介绍了NVIDIA最近对Mellanox的收购,还有重盼所归的基于NVIDIA Ampere GPU架构的新产品以及重要的最新软件技术。
这场主题演讲原计划于3月底在圣何塞举行的NVIDIA GPU技术大会上现场直播,但因冠状病毒疫情而受到影响。
“我要感谢正前线抗击COVID-19所有勇敢的战士们。”黄仁勋在开场时说到,“NVIDIA正在与研究人员和科学家合作,使用GPU和AI计算来治疗、缓解、控制和追踪这种大规模传染性疾病。”
NVIDIA也宣布了其NVIDIA Clara医疗平台的更新,旨在对抗COVID-19新型冠状病毒。
“研究人员和科学家们正在使用NVIDIA加速计算来挽救生命——这完美地诠释了我们公司的宗旨:通过制造计算机,解决普通计算机不能解决的问题。”黄仁勋说。
演讲主要围绕作为现代全球信息经济机房的数据中心如何变化,以及在上月完成交易的收购案双方NVIDIA和Mellanox如何共同推动这些变化的愿景。
“数据中心是新的计算单元,NVIDIA正在加速从芯片到CPU和GPU的连接方式,再到整个软件堆栈,以及最终跨整个数据中心的性能提升。”
数据中心规模计算的系统优化
首先,NVIDIA为这种新型的数据中心规模计算优化了新的GPU架构,集AI训练和推理于一身,并实现了灵活且弹性的加速。
NVIDIA A100是第一个基于NVIDIA Ampere架构的GPU,提供了在NVIDIA八代GPU里最大的性能提升,它还可用于数据分析,科学计算和云图形,并已全面投产并交付给全球客户。
全球18家领先的服务提供商和系统构建商正在将NVIDIA A100整合到他们的服务和产品中,其中包括阿里云、AWS、百度云、思科、Dell Technologies、Google Cloud、HPE、Microsoft Azure和甲骨文。
相比上一代,NVIDIA Ampere架构的A100将性能提升了20倍。A100的五大关键特性包括:
---- 超过540亿个晶体管,使其成为世界上最大的7纳米处理器
---- 带有TF32的第三代Tensor Core核心,这是一种新的数值格式,可加速开箱即用的单精度AI训练。NVIDIA广泛使用的Tensor Core现在更加灵活,快速,且更易于使用
---- 结构稀疏性(Structural sparsity)加速,这是一种新的高效技术,可以利用AI数学固有的稀疏性来获得更高的性能
--- 多实例GPU(Multi-instance GPU或MIG),允许将一个A100分割为多达七个独立的GPU,每个GPU都有自己的资源
----第三代NVLink技术,使GPU之间的高速联接能力加倍,从而可以使多个A100服务器充当一个巨型GPU
以上这些特性促成了A100性能的提升:与NVIDIA上一代的Volta架构相比,训练性能提高了6倍,推理性能提高了7倍。
NVIDIA DGX A100具备5 Petaflops的性能
NVIDIA还将发售第三代NVIDIA DGX AI系统—基于NVIDIA A100的NVIDIA DGX A100—世界上第一台5 petaflops服务器。每台DGX A100可以分割为多达56个独立运行的实例。
这使得单个服务器可以“纵向扩展”以完成诸如AI训练之类的计算密集型任务,或者“横向扩展”以进行AI部署或推理。
该系统的最初使用者是美国能源部的阿贡国家实验室,该实验室将利用该集群的AI和计算能力更好地理解和对抗COVID-19。此外,还有佛罗里达大学和德国人工智能研究中心。
美国能源部阿贡国家实验室,将使用DGX A100赋能的AI和算力更好地了解并抗击COVID-19
A100也将作为HGX A100提供给云合作伙伴和服务器制造商。
一套由五台DGX A100系统提供动力的数据中心,其成本仅为100万美元,功耗仅为28千瓦,但其性能足以媲美一套典型数据中心(由50台用于AI训练的DGX-1系统和600个总功耗高达630千瓦的CPU系统构成,成本超过1100万美元)。
NVIDIA还宣布了下一代DGX SuperPOD。它由140台DGX A100系统和Mellanox网络技术搭建而成,可提供700 petaflops的AI性能,堪比全球20台最快的计算机中的任何一台。
新一代DGX SuperPOD实现了强达每秒70 petaflops的AI算力
NVIDIA正在用四个DGX SuperPOD来扩展自己的数据中心,为其内部超级计算机SATURNV,增加了2.8 exaflops的AI计算能力(总计4.6 exaflops),使其成为世界上最快的AI超级计算机。
NVIDIA同时也发布了NVIDIA EGX A100,将强大的实时云计算功能带到了边缘。其NVIDIA Ampere架构GPU提供了第三代Tensor Core和新的安全功能。得益于其NVIDIA Mellanox ConnectX-6 SmartNIC,它还具有安全且快速的联网功能。
当今世界上最重要的应用软件
NVIDIA GPU将为主要软件应用程序提供动力,以加速三个关键用途:管理大数据,创建推荐系统和构建实时会话式AI。
随着机器学习的有效性推动公司收集了越来越多的数据,这些新工具应运而生。积极的反馈使我们体验到的数据收集量呈指数级增长。
为了帮助各类组织顺应潮流,NVIDIA宣布在Spark 3.0上支持NVIDIA GPU加速,大数据分析将成为当今世界上最重要的应用程序之一。
基于RAPIDS的Spark 3.0,打破了提取,转换和加载数据的性能基准。它已经帮助Adobe Intelligent Services将计算成本降低了90%。
关键的云分析平台(包括Amazon SageMaker,Azure Machine Learning,Databricks,Google Cloud AI和Google Cloud Dataproc)都将借助NVIDIA加速。
黄仁勋还宣布推出了NVIDIA Merlin,这是一个用于构建下一代推荐系统的端到端框架,该系统正迅速成为更加个性化互联网的引擎。Merlin将创建一个100 TB数据集推荐系统所需的时间从四天减少到20分钟。
他还详细介绍了NVIDIA Jarvis,这是一个新的端到端平台,可以充分发挥NVIDIA AI平台的强大功能,创建实时多模态对话式AI。
他通过一个演示来展示了与名为Misty的AI进行交互的过程,Misty可实时理解并回答一系列有关天气的复杂问题。
自2018年在SIGGRAPH上发布NVIDIA RTX以来,NVIDIA在实时光线追踪方面取得了迅猛发展,当时宣布的NVIDIA Omniverse可以让位于不同地方使用不同工具的设计师,在同个设计的不同部分同时工作。现在已经可供抢先体验客户使用。
自动驾驶汽车
自动驾驶汽车是我们这个时代最大的计算挑战之一,NVIDIA将持续通过NVIDIA DRIVE推动整个行业发展。
NVIDIA DRIVE将使用全新Orin SoC和NVIDIA Ampere GPU,以实现能效和性能,入门级ADAS系统开发所需功率仅需5瓦,并为L5级别robotaxi系统提供2,000 TOPS的性能。
现在,汽车制造商仅需单一计算架构和软件堆栈,即可将AI集成到每一辆车中。汽车制造商可以利用一种架构来开发整个车队,并利用整个车队来进行软件开发。
NVIDIA DRIVE生态系统现已覆盖汽车、卡车、一级汽车供应商、下一代出行服务、初创公司、地图服务和仿真。NVIDIA将在NVIDIA DRIVE技术套件中增加用于管理整个自动驾驶车队的NVIDIA DRIVE RC。
机器人技术
NVIDIA还将继续推进其NVIDIA Isaac软件定义的机器人平台,宣布宝马集团已选择NVIDIA Isaac机器人技术为其下一代工厂提供动力。
每56秒钟,宝马集团在全球的30家工厂就会生产一辆汽车:40种不同型号的汽车,每种都有数百种不同的选择,3000万个零件来自全球近2,000家供应商。
宝马集团加入了一个庞大的NVIDIA机器人技术全球生态系统,该生态系统涵盖配送、零售、自主移动机器人、农业、服务业、物流、制造和医疗保健。
未来,工厂实际上将成为巨大的机器人。“里面的所有运动部件都会由AI驱动。”黄仁勋说。“将来,每个批量生产的产品都将被逐一量身定制。”











