阿里巴巴双11流量洪峰背后的推荐模型性能
2019-12-16 15:22
 分享到微信
分享到微信
 分享到微博
分享到微博
随着阿里巴巴集团各项搜索推荐业务的用户量和商品量的大幅提升,搜索推荐各个场景下的算法模型计算量也逐步提升。同时新的更加复杂的模型算法具有更好的搜索推荐效果,这对搜索推荐平台的硬件计算力进一步提出了挑战。例如今年双11,最典型流量最高的搜索模型的计算量达到了去年搜索模型近十倍。虽然搜索平台采用大量异构硬件来满足算法迭代以及搜索对象增长的需求,但是仅通过硬件堆叠所带来的性能提升是低效的,巨大的硬件资源成本已无法承受业务日益增长的计算需求。因此,对硬件资源的使用效率进行优化已经迫在眉睫。GPU在支撑算力需求起到很大作用,但相比常见的CPU系统,CPU-GPU异构系统存在着不同的特性,例如数据存储、数据传输、并行计算特征等,因此原生的算法模型在CPU-GPU异构系统中并不能完全发挥出计算性能。
针对CPU-GPU异构系统中的计算特点,阿里巴巴采用资源分配、量化和图变换三种优化策略,从根本上对CPU-GPU异构系统的性能问题进行分析和优化,这些优化策略最终应用在搜索和推荐等多个主要场景,取得了2~3倍的性能提升,使得淘宝搜索平台的硬件资源能够支撑双11的流量洪峰。
优化策略
资源分配
对于一个CPU-GPU异构系统,一个最基本的问题就是如何分配资源,模型中哪些计算节点应该放到CPU上执行,哪些在GPU上执行。GPU的计算力远超CPU,那么理论上是尽可能多地将计算节点交给GPU执行。但是,要充分发挥GPU的计算力需要保证数据和计算程序都已经在GPU上了,而这两部分开销是发挥GPU算力的最关键部分。因此阿里巴巴根据算法模型中每个OP的计算特征来完成资源分配:
对于高计算访存比的OP,其数据传输时间相比计算时间较短,因此适合在GPU上执行。这里需要考虑是否有CPU-GPU传输,当该OP的输入数据已经在GPU上(即其前向OP也是在GPU上执行),那么这个OP就没有数据传输时间,该OP就非常适合在GPU上执行;
对于存储需求非常大的OP,由于GPU显存容量有限,无法在GPU上执行;搜索推荐模型一般都会包括Embedding LookUp,需要对大量特征进行查表,而GPU通常无法容纳这些大容量数据表,因此Embedding LookUp只能在CPU上执行;
对于计算量较小的OP,需要同时考虑其前向OP和后向OP,若前后都在GPU上执行,则该OP也适合在GPU上执行;若其中一个不适合在GPU上执行,那么该OP也不适合在GPU上执行,这主要是由于OP的Kernel Launch时间开销较大,甚至比时间计算时间更大,因此不适合传输到GPU上进行计算。
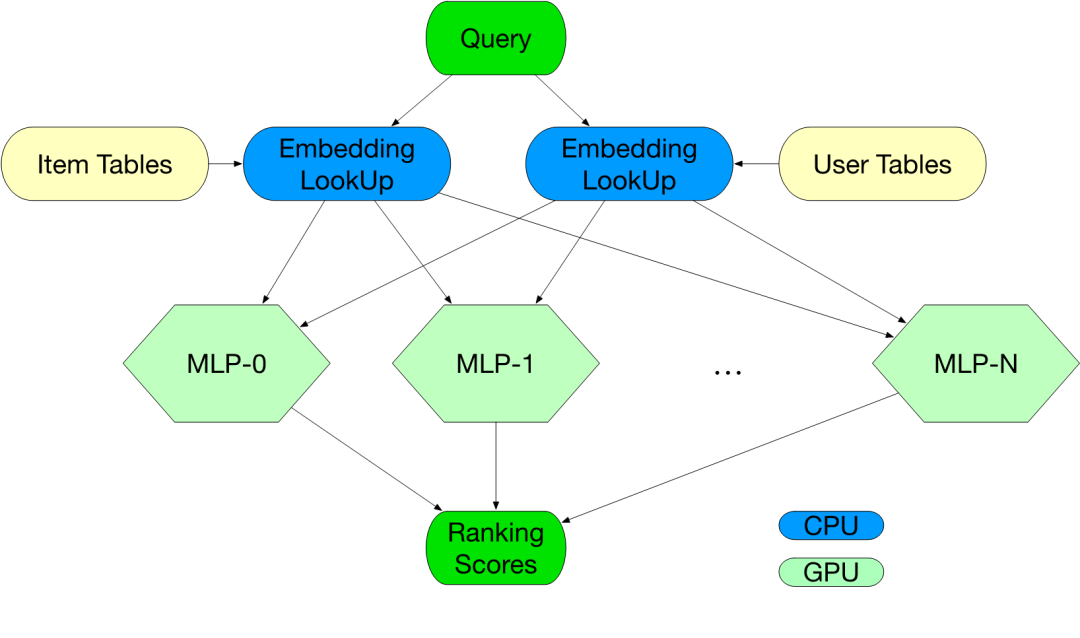
基于以上基本原则,再根据模型每个OP的计算特征进行综合考虑,完成每个算法模型的资源分配。例如典型的搜索模型包含了Embedding LookUp和MLP两部分,其中Embedding LookUp需要大容量来存储Feature Table,而MLP部分需要大量计算完成矩阵乘法运算,因此其最终资源分配方法如下所示:
FP16量化
很多研究表明,FP16精度的算法模型在推理中能够取得与FP32相同的算法准确度,因此通过FP16量化来降低模型的计算需求和数据传输需求能大幅提高GPU的推理性能。NVIDIA 最新两代GPU都通过Tensor Core提供超高的FP16计算力。阿里巴巴采用的NVIDIA T4 GPU具有多精度计算特性,实现了从 FP32、 FP16 到INT8 以及 INT4 精度的突破性 AI 性能,其FP16的峰值性能为65 teraflops,是FP32的8倍。
而且Tensor Core对于矩阵乘法进行了高度优化,与Volta架构所搭载的Tensor Core相类似,NVIDIA T4 搭载的Turing Tensor Core在深度学习神经网络训练和推理矩阵计算提供了极大的速度提升,因此T4 GPU的FP16算力和效率都得到了大幅提升。在训练过程中,模型算法仍然使用FP32进行,在推理时进行FP16量化,大幅降低整个模型的算力需求,提高算法模型的吞吐性能。与 CPU 相比,NVIDIA T4 GPU的训练性能高达 9.3倍,推理性能高达 36 倍。
量化过程中需要尽量降低精度损失,NVIDIA T4 所具有的 Tensor Core可以简化和加速多精度计算和混合精度计算。只需几行代码,就可以在 TensorFlow、PyTorch 和 MXNet 深度学习框架中启用矩阵乘法的自动混合精度功能。但是在某些其他特殊计算上可能会产生FP16溢出,因此在量化过程中需要对这些特殊计算进行FP32处理,保证其精度不会出现较大的损失。例如推荐模型中大量使用了Multihead Attention模块,该模块中包含了一个Softmax操作,Softmax计算可以表示为:
softmax = tf.exp(logits) / tf.reduce_sum(tf.exp(logits), axis)
其中的指数运算exp很容易产生FP16溢出,因此在量化过程中,需要对该softmax OP进行改写,输入输出数据采用FP16进行,但计算过程中的累加器采用FP32进行,从而大幅降低softmax量化带来的精度损失。
图变换
在高并发的模型推理过程中,大量Kernel在GPU上排队执行,每个Kernel的执行效率对整体系统吞吐率都有重要影响。阿里巴巴针对搜索推荐模型的计算特征,总结出了三种图变换方式,对模型中的计算OP数量进行大幅降低,从而提高GPU上的模型执行效率。
OP融合:将几个连续的OP融合成一个较大的OP,采用一个GPU Kernel完成几个OP的计算。多个连续OP的中间结果不会写入Global Memory,提高运算效率,同时减少Kernel Launch开销;
Subnet Batching:将几个相同的Subnet进行Batching处理,从而大幅降低模型的OP数量,降低Kernel Launch开销;
计算优化:根据模型计算特征,对模型的计算方法进行优化,从而去除不必要的运算。
通过这三种方式进行图变换,将搜索模型中GPU上执行的OP数量降低了75%,在另一个推荐模型中降低了高达97%的GPU OP数量。下面分别详细介绍这三种图变换方法:
OP融合
OP融合是指将几个连续的OP融合成一个较大的OP来完成计算。虽然很多小OP不适合在GPU上执行,但是由于其前后有较大OP,因此为了避免CPU与GPU之间多次数据传输所带来的额外开销,通常也有很多小OP分配到GPU上执行。GPU的计算速度是非常快的,但是对于小OP,Kernel Launch所带来的额外开销变得不可忽略,Kernel Launch时间甚至比Kernel执行时间更长,例如简单的向量加减等。尤其是在高并发的搜索推荐系统中,每台服务器每秒需要处理的Query数量非常多,大量的Kernel需要Launch到同一块GPU卡上进行运算。即使采用多线程并行对不同Kernel进行Launch,由于不同线程之间互锁机制带来的额外开销也非常高。因此将多个小OP合并成一个较大的OP,可以一定程度提高系统的性能。合并小OP可以大幅降低Kernel Launch时间,降低CPU负载;同时也会降低多线程Kernel Launch之间的互锁竞争,提高GPU吞吐率。
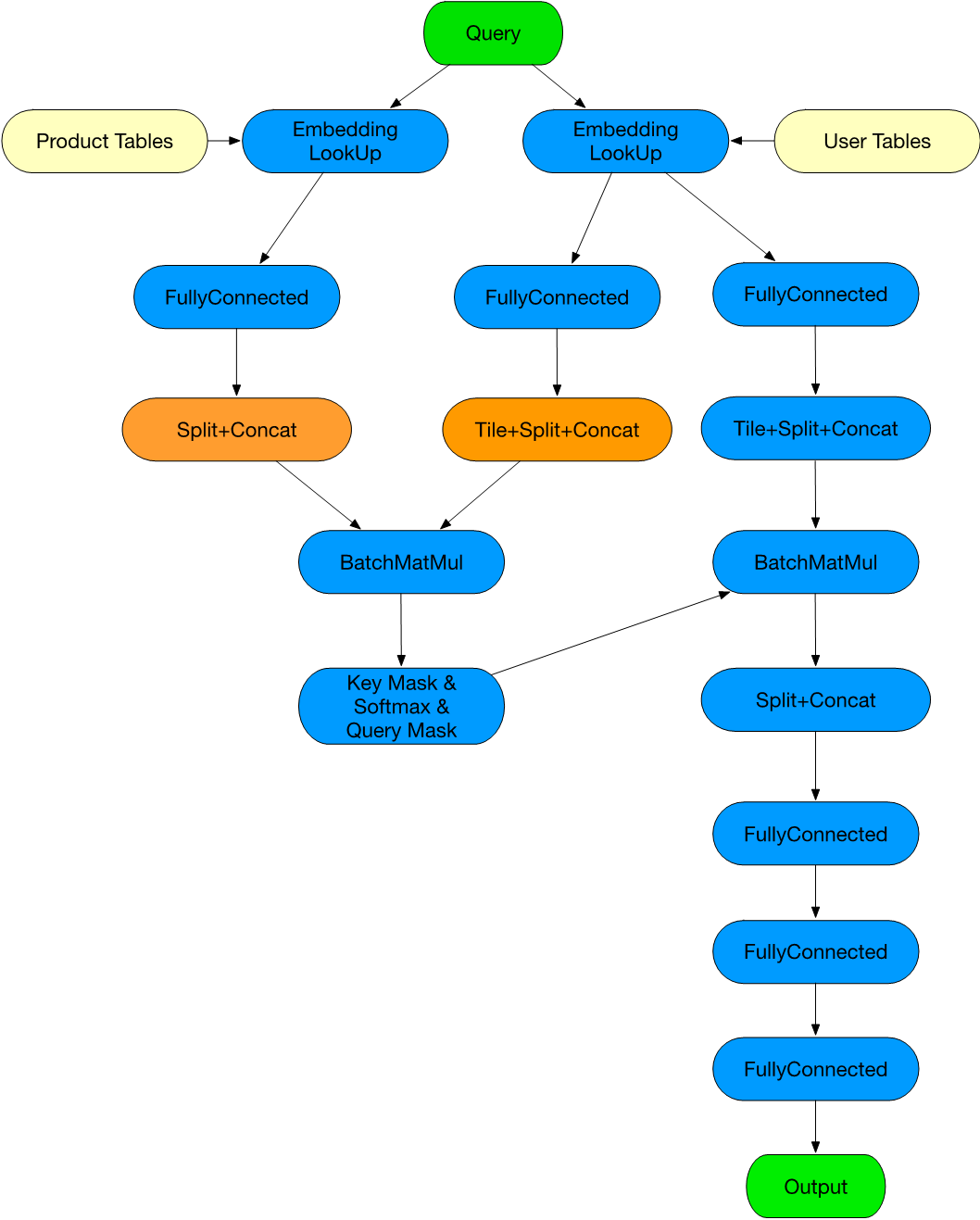
为了达到极致的性能提升,阿里巴巴会尽量多地采用CUDA等手段进行OP融合,NVIDIA提供的CUDA工具包包括GPU加速库、编译器、开发工具和CUDA运行时。其中,NVIDIA cuBLAS库是在NVIDIA CUDA中实现基本线性代数子程序(BLAS)的GPU加速。使用cuBLAS API,用户可以通过将计算密集型操作部署到单个GPU来加快应用程序的速度,或者高效地扩展并跨多个GPU配置分发工作。对于矩阵乘法或卷积运算,NVIDIA的cuBLAS库所具有的高效矩阵乘法是其他矩阵计算方法所无法比拟的,因此进行OP融合时无法通过自定义Kernel达到cuBLAS的计算性能。最佳性能的OP融合方式是尽量融合从一个矩阵乘法到下一个矩阵乘法中的所有OP(不包括矩阵乘法)。
例如上述推荐模型,每个框内的多个OP将会被融合成一个大的OP(FullyConnected内部仅做了BiasAdd+Relu融合),从而大幅降低模型的OP数量。
Subnet Batching
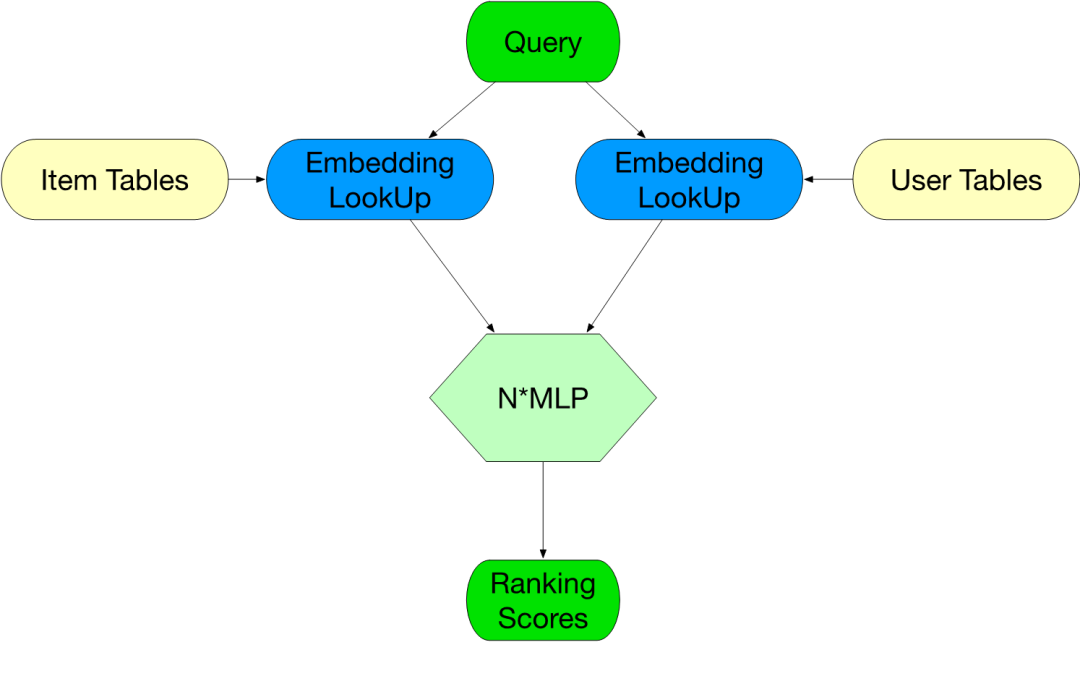
Subnet是指一系列连续OP组合成的一个子网络,而Subnet Batching是指将模型中多个相同的Subnet进行Batching处理,从而将多份相同操作进行合并,将OP数量降低为原有的1/N(N为相同Subnet数量)。这也在很大程度上降低了模型中的OP数量,降低了GPU的Kernel Launch所带来的额外开销。尤其是每个Subnet中的OP都比较小的时候,Kernel Launch的开销非常大,通过Batching合并处理可以带来较大的性能提升。例如以上搜索模型经过Subnet Batching后,N个MLP模型将会被合并成一个Batch Size为N的MLP,内部的MatMul及FusedBiasAddRelu都会进行BatchSize为N的Batch计算处理。
计算优化
计算优化是指,根据每个模型算法的计算方法,分析模型中可以优化掉的OP,或者改变计算方式,减少计算量或者存储访问量等。这种优化方法都是要对模型中计算方法进行分析,虽然不一定每个模型中都存在这些可以被优化的点,但这种现象普遍存在。这是由于算法同学不了解底层硬件或计算库的高效使用方法,导致算法模型代码的编写方法不是最佳的使用硬件或者加速库的方法;另一方面,模型框架例如Tensorflow没有做到最好的优化,没有将不必要或者可优化的计算进行去除或优化。例如推荐模型中每个用户特征需要与所有商品特征进行特征计算,所以算法同学先将用户特征复制出N份,然后1对1地与商品进行特征计算。而实际上矩阵乘法运算是可以不通过复制直接计算出1个用户与N个商品的计算结果(商品特征:NxK,用户特征:Kx1)。由于操作过程中还加入了其他的一些变形数据重组等操作,导致算法同学没有直接发现这里的不必要操作。因此可以对该部分的复制行为进行去除,减少不必要的计算和访存行为。在优化过程中,阿里巴巴也优化了很多Shape获取(OP融合之后可以从很多其他OP获取相同的Shape维度)、恒值输入(由于Shape不确定导致无法通过Const Folding优化)等行为。
性能提升
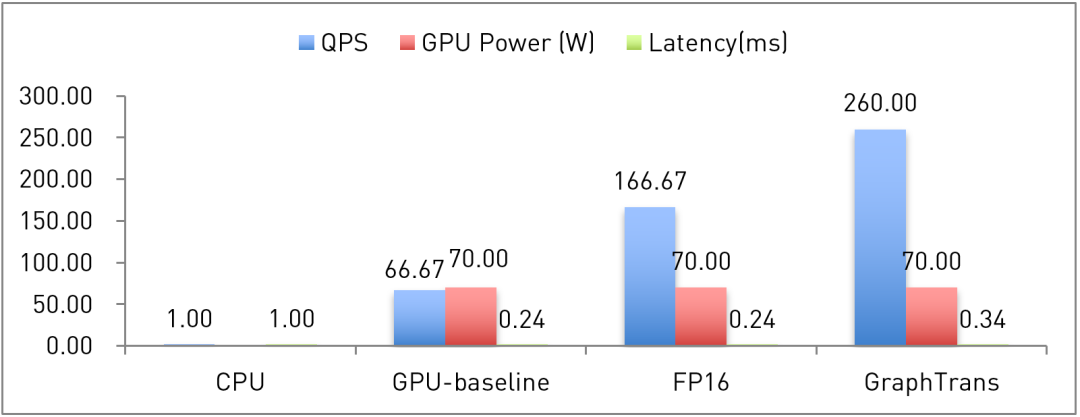
下面以其中的一个搜索模型作为例子说明GPU强大的计算力的支持以及以上GPU优化方法所带来的性能提升:
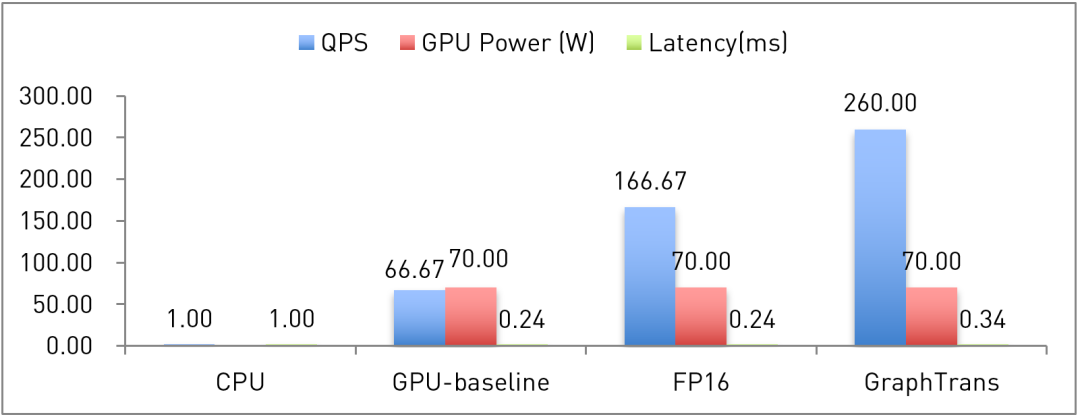
其中,QPS(Query Per Second,每秒查询)、GPU Power和Latency都是在离线压测环境下的数据,GPU为NVIDIA T4 GPU,CPU为两CPU 96核。GPU-baseline是做好资源分配之后的基准性能结果,FP16和GraphTrans分别是FP16量化和图变换之后的优化结果。由于T4限定功耗为70W,因此从GPU-baseline到优化后,阿里巴巴都将GPU负载压到了功耗峰值。压测环境下,延迟Latency略微增高了42%,实际非压测情况下,高流量也不会带来额外的延迟。在典型搜索推荐模型中,CPU的搜索性能和延迟都无法满足实时线上系统的性能需求。而GPU-baseline的基准性能测试就达到了CPU的66.7倍,且将延迟降低了76%,对整体系统性能进行了大幅提升。FP16量化后,搜索性能相较于GPU-baseline提高了1.5倍,比CPU的搜索性能提高了165倍左右。经过图变换优化后,其搜索性能Query Per Second比GPU-baseline提高了2.9倍,大幅降低业务所需要的服务器数量。
阿里巴巴针对搜索和推荐两个场景的优化也被复用到其他场景中,都提供了2~3倍的性能提升。阿里巴巴的优化几乎覆盖了全部无线淘宝搜索流量,同时新算法相较之前算法的算法效果都有了一定的提升。正是由于GPU的计算力以及阿里巴巴基于CUDA、cuBLAS等软件实现的优化方法,大幅降低了新算法的硬件开销,从而使新算法能够大规模部署上线。尤其是搜索模型,双11采用了几千张NVIDIA T4 GPU来支持,而阿里巴巴的优化提供了3倍的性能提升,大幅降低双11流量洪峰所需的硬件需求,将不可能(如果没有优化,没有足够的GPU支持如此大的流量)变为可能。
通过以上GPU优化方法,阿里巴巴在多个主要场景中大幅降低了搜索平台支撑双11洪流所需要的服务器数量,同时也支撑了搜索推荐算法的迭代更新,为双11GMV做出了重大贡献。
通过资源分配、FP16量化及图变换三种优化方法,阿里巴巴对搜索推荐中的常见模型进行了性能优化,将单机业务性能进行了大幅提升,降低了业务支撑双11洪流所需要的服务器数量,同时对业务算法模型迭代进行了支持,确保服务器算力能够支撑算法迭代和更新。同时,针搜索模型的优化方法已成功被体系结构领域顶级国际会议SC19的Poster session录用,会议已于11月份在美国丹佛举行。
针对CPU-GPU异构系统中的计算特点,阿里巴巴采用资源分配、量化和图变换三种优化策略,从根本上对CPU-GPU异构系统的性能问题进行分析和优化,这些优化策略最终应用在搜索和推荐等多个主要场景,取得了2~3倍的性能提升,使得淘宝搜索平台的硬件资源能够支撑双11的流量洪峰。
优化策略
资源分配
对于一个CPU-GPU异构系统,一个最基本的问题就是如何分配资源,模型中哪些计算节点应该放到CPU上执行,哪些在GPU上执行。GPU的计算力远超CPU,那么理论上是尽可能多地将计算节点交给GPU执行。但是,要充分发挥GPU的计算力需要保证数据和计算程序都已经在GPU上了,而这两部分开销是发挥GPU算力的最关键部分。因此阿里巴巴根据算法模型中每个OP的计算特征来完成资源分配:
对于高计算访存比的OP,其数据传输时间相比计算时间较短,因此适合在GPU上执行。这里需要考虑是否有CPU-GPU传输,当该OP的输入数据已经在GPU上(即其前向OP也是在GPU上执行),那么这个OP就没有数据传输时间,该OP就非常适合在GPU上执行;
对于存储需求非常大的OP,由于GPU显存容量有限,无法在GPU上执行;搜索推荐模型一般都会包括Embedding LookUp,需要对大量特征进行查表,而GPU通常无法容纳这些大容量数据表,因此Embedding LookUp只能在CPU上执行;
对于计算量较小的OP,需要同时考虑其前向OP和后向OP,若前后都在GPU上执行,则该OP也适合在GPU上执行;若其中一个不适合在GPU上执行,那么该OP也不适合在GPU上执行,这主要是由于OP的Kernel Launch时间开销较大,甚至比时间计算时间更大,因此不适合传输到GPU上进行计算。
基于以上基本原则,再根据模型每个OP的计算特征进行综合考虑,完成每个算法模型的资源分配。例如典型的搜索模型包含了Embedding LookUp和MLP两部分,其中Embedding LookUp需要大容量来存储Feature Table,而MLP部分需要大量计算完成矩阵乘法运算,因此其最终资源分配方法如下所示:
搜索模型
FP16量化
很多研究表明,FP16精度的算法模型在推理中能够取得与FP32相同的算法准确度,因此通过FP16量化来降低模型的计算需求和数据传输需求能大幅提高GPU的推理性能。NVIDIA 最新两代GPU都通过Tensor Core提供超高的FP16计算力。阿里巴巴采用的NVIDIA T4 GPU具有多精度计算特性,实现了从 FP32、 FP16 到INT8 以及 INT4 精度的突破性 AI 性能,其FP16的峰值性能为65 teraflops,是FP32的8倍。
而且Tensor Core对于矩阵乘法进行了高度优化,与Volta架构所搭载的Tensor Core相类似,NVIDIA T4 搭载的Turing Tensor Core在深度学习神经网络训练和推理矩阵计算提供了极大的速度提升,因此T4 GPU的FP16算力和效率都得到了大幅提升。在训练过程中,模型算法仍然使用FP32进行,在推理时进行FP16量化,大幅降低整个模型的算力需求,提高算法模型的吞吐性能。与 CPU 相比,NVIDIA T4 GPU的训练性能高达 9.3倍,推理性能高达 36 倍。
量化过程中需要尽量降低精度损失,NVIDIA T4 所具有的 Tensor Core可以简化和加速多精度计算和混合精度计算。只需几行代码,就可以在 TensorFlow、PyTorch 和 MXNet 深度学习框架中启用矩阵乘法的自动混合精度功能。但是在某些其他特殊计算上可能会产生FP16溢出,因此在量化过程中需要对这些特殊计算进行FP32处理,保证其精度不会出现较大的损失。例如推荐模型中大量使用了Multihead Attention模块,该模块中包含了一个Softmax操作,Softmax计算可以表示为:
softmax = tf.exp(logits) / tf.reduce_sum(tf.exp(logits), axis)
其中的指数运算exp很容易产生FP16溢出,因此在量化过程中,需要对该softmax OP进行改写,输入输出数据采用FP16进行,但计算过程中的累加器采用FP32进行,从而大幅降低softmax量化带来的精度损失。
推荐模型
图变换
在高并发的模型推理过程中,大量Kernel在GPU上排队执行,每个Kernel的执行效率对整体系统吞吐率都有重要影响。阿里巴巴针对搜索推荐模型的计算特征,总结出了三种图变换方式,对模型中的计算OP数量进行大幅降低,从而提高GPU上的模型执行效率。
OP融合:将几个连续的OP融合成一个较大的OP,采用一个GPU Kernel完成几个OP的计算。多个连续OP的中间结果不会写入Global Memory,提高运算效率,同时减少Kernel Launch开销;
Subnet Batching:将几个相同的Subnet进行Batching处理,从而大幅降低模型的OP数量,降低Kernel Launch开销;
计算优化:根据模型计算特征,对模型的计算方法进行优化,从而去除不必要的运算。
通过这三种方式进行图变换,将搜索模型中GPU上执行的OP数量降低了75%,在另一个推荐模型中降低了高达97%的GPU OP数量。下面分别详细介绍这三种图变换方法:
OP融合
OP融合是指将几个连续的OP融合成一个较大的OP来完成计算。虽然很多小OP不适合在GPU上执行,但是由于其前后有较大OP,因此为了避免CPU与GPU之间多次数据传输所带来的额外开销,通常也有很多小OP分配到GPU上执行。GPU的计算速度是非常快的,但是对于小OP,Kernel Launch所带来的额外开销变得不可忽略,Kernel Launch时间甚至比Kernel执行时间更长,例如简单的向量加减等。尤其是在高并发的搜索推荐系统中,每台服务器每秒需要处理的Query数量非常多,大量的Kernel需要Launch到同一块GPU卡上进行运算。即使采用多线程并行对不同Kernel进行Launch,由于不同线程之间互锁机制带来的额外开销也非常高。因此将多个小OP合并成一个较大的OP,可以一定程度提高系统的性能。合并小OP可以大幅降低Kernel Launch时间,降低CPU负载;同时也会降低多线程Kernel Launch之间的互锁竞争,提高GPU吞吐率。
为了达到极致的性能提升,阿里巴巴会尽量多地采用CUDA等手段进行OP融合,NVIDIA提供的CUDA工具包包括GPU加速库、编译器、开发工具和CUDA运行时。其中,NVIDIA cuBLAS库是在NVIDIA CUDA中实现基本线性代数子程序(BLAS)的GPU加速。使用cuBLAS API,用户可以通过将计算密集型操作部署到单个GPU来加快应用程序的速度,或者高效地扩展并跨多个GPU配置分发工作。对于矩阵乘法或卷积运算,NVIDIA的cuBLAS库所具有的高效矩阵乘法是其他矩阵计算方法所无法比拟的,因此进行OP融合时无法通过自定义Kernel达到cuBLAS的计算性能。最佳性能的OP融合方式是尽量融合从一个矩阵乘法到下一个矩阵乘法中的所有OP(不包括矩阵乘法)。
例如上述推荐模型,每个框内的多个OP将会被融合成一个大的OP(FullyConnected内部仅做了BiasAdd+Relu融合),从而大幅降低模型的OP数量。
Subnet Batching
Subnet是指一系列连续OP组合成的一个子网络,而Subnet Batching是指将模型中多个相同的Subnet进行Batching处理,从而将多份相同操作进行合并,将OP数量降低为原有的1/N(N为相同Subnet数量)。这也在很大程度上降低了模型中的OP数量,降低了GPU的Kernel Launch所带来的额外开销。尤其是每个Subnet中的OP都比较小的时候,Kernel Launch的开销非常大,通过Batching合并处理可以带来较大的性能提升。例如以上搜索模型经过Subnet Batching后,N个MLP模型将会被合并成一个Batch Size为N的MLP,内部的MatMul及FusedBiasAddRelu都会进行BatchSize为N的Batch计算处理。
搜索模型
计算优化
计算优化是指,根据每个模型算法的计算方法,分析模型中可以优化掉的OP,或者改变计算方式,减少计算量或者存储访问量等。这种优化方法都是要对模型中计算方法进行分析,虽然不一定每个模型中都存在这些可以被优化的点,但这种现象普遍存在。这是由于算法同学不了解底层硬件或计算库的高效使用方法,导致算法模型代码的编写方法不是最佳的使用硬件或者加速库的方法;另一方面,模型框架例如Tensorflow没有做到最好的优化,没有将不必要或者可优化的计算进行去除或优化。例如推荐模型中每个用户特征需要与所有商品特征进行特征计算,所以算法同学先将用户特征复制出N份,然后1对1地与商品进行特征计算。而实际上矩阵乘法运算是可以不通过复制直接计算出1个用户与N个商品的计算结果(商品特征:NxK,用户特征:Kx1)。由于操作过程中还加入了其他的一些变形数据重组等操作,导致算法同学没有直接发现这里的不必要操作。因此可以对该部分的复制行为进行去除,减少不必要的计算和访存行为。在优化过程中,阿里巴巴也优化了很多Shape获取(OP融合之后可以从很多其他OP获取相同的Shape维度)、恒值输入(由于Shape不确定导致无法通过Const Folding优化)等行为。
性能提升
下面以其中的一个搜索模型作为例子说明GPU强大的计算力的支持以及以上GPU优化方法所带来的性能提升:
其中,QPS(Query Per Second,每秒查询)、GPU Power和Latency都是在离线压测环境下的数据,GPU为NVIDIA T4 GPU,CPU为两CPU 96核。GPU-baseline是做好资源分配之后的基准性能结果,FP16和GraphTrans分别是FP16量化和图变换之后的优化结果。由于T4限定功耗为70W,因此从GPU-baseline到优化后,阿里巴巴都将GPU负载压到了功耗峰值。压测环境下,延迟Latency略微增高了42%,实际非压测情况下,高流量也不会带来额外的延迟。在典型搜索推荐模型中,CPU的搜索性能和延迟都无法满足实时线上系统的性能需求。而GPU-baseline的基准性能测试就达到了CPU的66.7倍,且将延迟降低了76%,对整体系统性能进行了大幅提升。FP16量化后,搜索性能相较于GPU-baseline提高了1.5倍,比CPU的搜索性能提高了165倍左右。经过图变换优化后,其搜索性能Query Per Second比GPU-baseline提高了2.9倍,大幅降低业务所需要的服务器数量。
阿里巴巴针对搜索和推荐两个场景的优化也被复用到其他场景中,都提供了2~3倍的性能提升。阿里巴巴的优化几乎覆盖了全部无线淘宝搜索流量,同时新算法相较之前算法的算法效果都有了一定的提升。正是由于GPU的计算力以及阿里巴巴基于CUDA、cuBLAS等软件实现的优化方法,大幅降低了新算法的硬件开销,从而使新算法能够大规模部署上线。尤其是搜索模型,双11采用了几千张NVIDIA T4 GPU来支持,而阿里巴巴的优化提供了3倍的性能提升,大幅降低双11流量洪峰所需的硬件需求,将不可能(如果没有优化,没有足够的GPU支持如此大的流量)变为可能。
通过以上GPU优化方法,阿里巴巴在多个主要场景中大幅降低了搜索平台支撑双11洪流所需要的服务器数量,同时也支撑了搜索推荐算法的迭代更新,为双11GMV做出了重大贡献。
通过资源分配、FP16量化及图变换三种优化方法,阿里巴巴对搜索推荐中的常见模型进行了性能优化,将单机业务性能进行了大幅提升,降低了业务支撑双11洪流所需要的服务器数量,同时对业务算法模型迭代进行了支持,确保服务器算力能够支撑算法迭代和更新。同时,针搜索模型的优化方法已成功被体系结构领域顶级国际会议SC19的Poster session录用,会议已于11月份在美国丹佛举行。











