一文读懂联邦学习是什么?
2019-11-06 20:14
 分享到微信
分享到微信
 分享到微博
分享到微博
在医学领域,无论是在哪个科室,成为医学专家的关键都在于经验。
如何解释症状,在危急情况下应该采取何种措施,以及针对患者的病症应该提供何种治疗——这一切都取决于一名医生,其接受过的训练和实践经验。
而对于AI算法来说,需要“经验”,只是所需的“经验”是大量、多样、高质量的数据。但是,这些数据集通常很难获得,尤其是在医疗健康领域。
因此,医疗机构不得不依赖自己的数据来源,但是这些数据来源可能会受到患者人口统计、使用的仪器或临床专业化等因素的影响。或者他们需要从其他机构收集数据,从而获得他们需要的所有信息。
而联邦学习(federated learning)恰好能够让AI算法借助位于不同站点的数据中获得经验。
该方法能够让多个组织协作开发模型,而且不需要彼此之间直接共享敏感的临床数据
在多次训练迭代过程中,共享模型所覆盖的数据范围会比任何一个组织内部拥有的数据都要大得多。
联邦学习如何工作
在医学场景中部署的AI算法的最终目标,是达到临床级的准确性。在很大程度上,这意味着它们不仅需要达到这一标准,甚至还要超越这一标准。
想要成为医学领域中某个方面的专家,一名医生通常需要在这一领域工作至少15年。通常一名技师每年都大概需要浏览大约15,000个病例;加起来,在他们整个职业生涯,一共大约要浏览225,000个病例。
然而,面对一些罕见的疾病,即便是医学专家,其治疗经验也是少之又少的。例如,某一个罕见病,大约2,000人中只有1人会患病,那么即便是一位有着30年经验的专家,在其整个职业生涯中,可能也只接触过100位患有此病的患者。
为了将一个模型训练到专家级水平,需要给AI算法输入大量的病例,而且这些病例需要能够充分代表它们所处的临床环境。
但目前,即便是最大的开放性数据集,其中也仅包含10万个病例。
而且,不仅仅是数据量的问题。数据集还需要极高的多样化,并纳入来自不同性别、年龄、人口统计和环境的患者样本。
个别医疗机构可能拥有数十万条记录和图像的档案储备,但这些数据源通常是无法得到利用,因为医疗健康数据极具隐私性,在未得到患者的同意以及社会道德准则认可之前,这些数据是不能使用的。
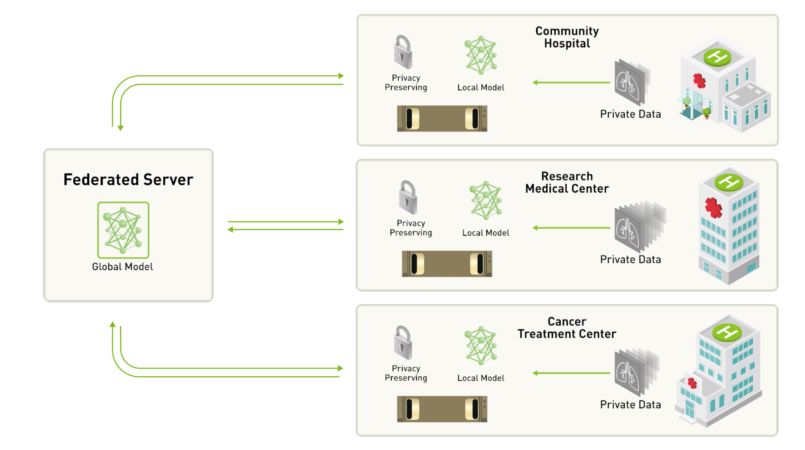
为解决这一问题,联邦学习摒弃了将数据集中到某个位置进行训练的方法,取而代之的是将模型分散到各个不同的站点进行迭代训练。
例如,当前有三家医院决定合作建立一个模型,用于自动分析脑肿瘤图像。
如果他们选择采用联邦学习的方式,那么这里首先将会有一个中心服务器(centralized server)维护全局深度神经网络,每个参与项目的医院都会得到一个副本,在其各自的服务器上使用自己的数据集进行训练。
在本地对模型进行了数次迭代训练之后,参与者会将训练后的更新版模型发送回中心服务器,但在这一过程中,训练所用的数据集则是始终都保存在各个医院自己的安全基础设施中,不曾离开片刻。
随后,中心服务器将汇总所有参与者的训练成果,并将更新后的模型参数再度分发给各参与机构,以便它们能够继续进行本地训练。
在整个项目进行的过程中,如果其中一家医院决定离开训练团队,该模型训练工作也不会因此而中断,因为它不依赖任何具体数据。同理,另外一家新医院也可以随时加入该项目。
当然,这只是联邦学习的众多应用方法之一。纵观其所有的应用方法,它们都有一个共同点,那就是每个参与者都能凭借本地数据获取全局知识——从而达到共赢的结果。
为何选择联邦学习?
为确保患者数据安全的万无一失,联邦学习的应用实现仍需谨慎。但是,对于那些需要接触到敏感临床数据的应用方法,联邦学习有相应的措施来应对挑战。
对于联邦学习来说,临床数据始终都保存着到医疗机构自身的安全措施之内,不会外泄。每个参与者都独自掌握自己的临床数据。
这使得获取患者信息变得十分困难。凭借此优势,联邦学习为团队开辟了新的可能性,使其使用更大、更多样化的数据集来训练他们的AI算法。
采用联邦学习方法还可以鼓励不同的医院、医疗机构和研究中心合作建立一个可以令所有人受益的模型。
联邦学习将为医疗带来何种改变
联邦学习可以彻底改变AI模型的训练方式,并将其优势渗透到更广泛的医疗生态系统中。
大型医院之间将能够更好地协同工作,并从跨机构的数据中获益。而小型的社区医院和乡村医院则可以借此使用专家级的AI算法。
它可以将AI引入到需要关注的地方,能够在遵守临床数据本地化管理的基础上,将大量来自不同组织的数据应用到模型开发的过程中。
临床医生将能够借此获得更为强大的AI算法,这些算法基于代表特定临床区域的广泛患者人口数据,或来自于医生所在地不会遇到的罕见病例数据。
由于采用了更加安全的方法从更多样化的算法中学习,医疗初创企业可以更快地将尖端创新推向市场。
同时,研究机构将能够根据多样化的真实数据,将其工作引向实际的临床需要,而不再受限于开放数据集的有限数据。
生于医疗,用于医疗
目前,多个大规模联合学习项目已经启动,希望能够借助于联邦学习方法加速药物发现进程,并将AI益处带入到临床应用当中。
MELLODDY是一个位于英国的药物发现联盟,其旨在展示联邦学习技术如何帮助制药合作伙伴在不牺牲数据隐私的情况下,借助于世界上最大的协作药物复合数据集,来进行人工智能训练。
作为伦敦医学影像和人工智能中心价值医疗项目的一部分,伦敦国王学院(King’s College London)希望能够借助于联邦学习,在中风和神经损伤分类、确定癌症的潜在原因方面取得突破性进展,为病人探索出最好的治疗方法。
如何解释症状,在危急情况下应该采取何种措施,以及针对患者的病症应该提供何种治疗——这一切都取决于一名医生,其接受过的训练和实践经验。
而对于AI算法来说,需要“经验”,只是所需的“经验”是大量、多样、高质量的数据。但是,这些数据集通常很难获得,尤其是在医疗健康领域。
因此,医疗机构不得不依赖自己的数据来源,但是这些数据来源可能会受到患者人口统计、使用的仪器或临床专业化等因素的影响。或者他们需要从其他机构收集数据,从而获得他们需要的所有信息。
而联邦学习(federated learning)恰好能够让AI算法借助位于不同站点的数据中获得经验。
该方法能够让多个组织协作开发模型,而且不需要彼此之间直接共享敏感的临床数据
在多次训练迭代过程中,共享模型所覆盖的数据范围会比任何一个组织内部拥有的数据都要大得多。
联邦学习如何工作
在医学场景中部署的AI算法的最终目标,是达到临床级的准确性。在很大程度上,这意味着它们不仅需要达到这一标准,甚至还要超越这一标准。
想要成为医学领域中某个方面的专家,一名医生通常需要在这一领域工作至少15年。通常一名技师每年都大概需要浏览大约15,000个病例;加起来,在他们整个职业生涯,一共大约要浏览225,000个病例。
然而,面对一些罕见的疾病,即便是医学专家,其治疗经验也是少之又少的。例如,某一个罕见病,大约2,000人中只有1人会患病,那么即便是一位有着30年经验的专家,在其整个职业生涯中,可能也只接触过100位患有此病的患者。
为了将一个模型训练到专家级水平,需要给AI算法输入大量的病例,而且这些病例需要能够充分代表它们所处的临床环境。
但目前,即便是最大的开放性数据集,其中也仅包含10万个病例。
而且,不仅仅是数据量的问题。数据集还需要极高的多样化,并纳入来自不同性别、年龄、人口统计和环境的患者样本。
个别医疗机构可能拥有数十万条记录和图像的档案储备,但这些数据源通常是无法得到利用,因为医疗健康数据极具隐私性,在未得到患者的同意以及社会道德准则认可之前,这些数据是不能使用的。
为解决这一问题,联邦学习摒弃了将数据集中到某个位置进行训练的方法,取而代之的是将模型分散到各个不同的站点进行迭代训练。
例如,当前有三家医院决定合作建立一个模型,用于自动分析脑肿瘤图像。
如果他们选择采用联邦学习的方式,那么这里首先将会有一个中心服务器(centralized server)维护全局深度神经网络,每个参与项目的医院都会得到一个副本,在其各自的服务器上使用自己的数据集进行训练。
在本地对模型进行了数次迭代训练之后,参与者会将训练后的更新版模型发送回中心服务器,但在这一过程中,训练所用的数据集则是始终都保存在各个医院自己的安全基础设施中,不曾离开片刻。
随后,中心服务器将汇总所有参与者的训练成果,并将更新后的模型参数再度分发给各参与机构,以便它们能够继续进行本地训练。
在整个项目进行的过程中,如果其中一家医院决定离开训练团队,该模型训练工作也不会因此而中断,因为它不依赖任何具体数据。同理,另外一家新医院也可以随时加入该项目。
当然,这只是联邦学习的众多应用方法之一。纵观其所有的应用方法,它们都有一个共同点,那就是每个参与者都能凭借本地数据获取全局知识——从而达到共赢的结果。
为何选择联邦学习?
为确保患者数据安全的万无一失,联邦学习的应用实现仍需谨慎。但是,对于那些需要接触到敏感临床数据的应用方法,联邦学习有相应的措施来应对挑战。
对于联邦学习来说,临床数据始终都保存着到医疗机构自身的安全措施之内,不会外泄。每个参与者都独自掌握自己的临床数据。
这使得获取患者信息变得十分困难。凭借此优势,联邦学习为团队开辟了新的可能性,使其使用更大、更多样化的数据集来训练他们的AI算法。
采用联邦学习方法还可以鼓励不同的医院、医疗机构和研究中心合作建立一个可以令所有人受益的模型。
联邦学习将为医疗带来何种改变
联邦学习可以彻底改变AI模型的训练方式,并将其优势渗透到更广泛的医疗生态系统中。
大型医院之间将能够更好地协同工作,并从跨机构的数据中获益。而小型的社区医院和乡村医院则可以借此使用专家级的AI算法。
它可以将AI引入到需要关注的地方,能够在遵守临床数据本地化管理的基础上,将大量来自不同组织的数据应用到模型开发的过程中。
临床医生将能够借此获得更为强大的AI算法,这些算法基于代表特定临床区域的广泛患者人口数据,或来自于医生所在地不会遇到的罕见病例数据。
由于采用了更加安全的方法从更多样化的算法中学习,医疗初创企业可以更快地将尖端创新推向市场。
同时,研究机构将能够根据多样化的真实数据,将其工作引向实际的临床需要,而不再受限于开放数据集的有限数据。
生于医疗,用于医疗
目前,多个大规模联合学习项目已经启动,希望能够借助于联邦学习方法加速药物发现进程,并将AI益处带入到临床应用当中。
MELLODDY是一个位于英国的药物发现联盟,其旨在展示联邦学习技术如何帮助制药合作伙伴在不牺牲数据隐私的情况下,借助于世界上最大的协作药物复合数据集,来进行人工智能训练。
作为伦敦医学影像和人工智能中心价值医疗项目的一部分,伦敦国王学院(King’s College London)希望能够借助于联邦学习,在中风和神经损伤分类、确定癌症的潜在原因方面取得突破性进展,为病人探索出最好的治疗方法。











