麻省理工学院最新视频识别模型可极大改善边缘设备延迟
2019-10-21 19:27
 分享到微信
分享到微信
 分享到微博
分享到微博
为提高视频识别应用程序在NVIDIA Jetson Nano和Jetson TX2等边缘设备上的速度,麻省理工学院(MIT)的研究人员开发了一种新型深度学习模型,该模型性能优于以前视频识别任务中最先进的模型。
该模型在美国能源部下属橡树岭国家实验室的超级计算机Summit上进行训练,使用了1,536个NVIDIA V100 GPU,并在第1版和第2版Something-Something视频数据集公开挑战赛中蝉联冠军。
拟在韩国首尔举行的国际计算机视觉会议(International Conference on Computer Vision)上发表的研究论文详细介绍了该方法,该方法利用时间转移模块(Temporal Shift Module)框架来实现3D卷积神经网络(CNN)的性能,但同时具有2D 卷积神经网络的复杂性。
研究人员在论文中指出:“传统2D CNN在计算上成本低,但无法捕获时间关系。基于3D CNN的方法可以实现良好性能,但计算量庞大,因此部署成本高。在论文中,我们提出了通用且有效的时间转移模块(TSM),它既高效又具有高性能。”
该团队认为,这种方法可以将模型缩小到1/6,也就是将最先进模型中的1.5亿个参数减少到2500万个参数。
麻省理工学院(MIT)的助理教授,及该论文的合著者Song Han说:“我们的目标是使任何通过低功耗设备工作的人都可以使用AI。要做到这一点,我们需要设计耗能更少的高效AI模型,这个模型可以在边缘设备上平稳运行。”
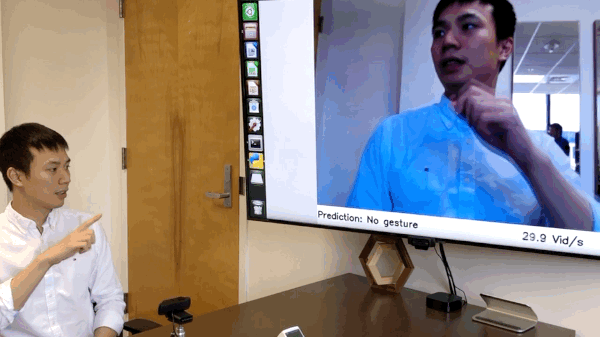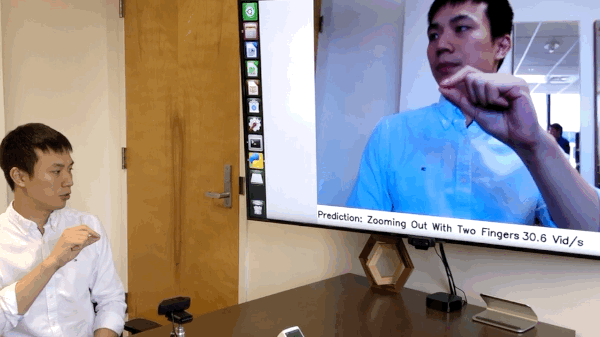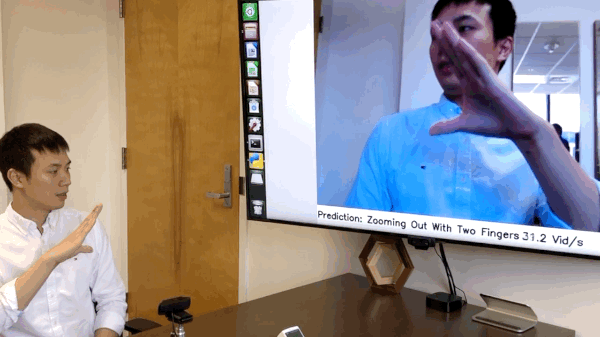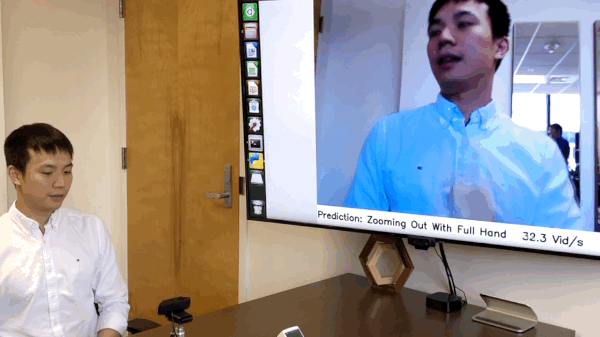
这项研究的主要作者Ji Lin展示了安装在摄像机上的单个NVIDIA Jetson Nano如何能够在仅12.4毫秒的延迟下立即对手势进行分类。
研究小组在橡树岭国家实验室借助Summit训练这种算法。在那里,Lin和他的团队使用NVIDIA V100 GPU和cuDNN加速的PyTorch深度学习框架,仅在14分钟内就训练了他们的模型。
研究人员说:“大型AI训练工作的计算要求每3.5个月翻一番。我们能否继续突破技术极限,取决于超高效算法与强大机器相匹配的战略。”
研究人员还在GitHub上发布了实现PyTorch的代码。
该模型在美国能源部下属橡树岭国家实验室的超级计算机Summit上进行训练,使用了1,536个NVIDIA V100 GPU,并在第1版和第2版Something-Something视频数据集公开挑战赛中蝉联冠军。
拟在韩国首尔举行的国际计算机视觉会议(International Conference on Computer Vision)上发表的研究论文详细介绍了该方法,该方法利用时间转移模块(Temporal Shift Module)框架来实现3D卷积神经网络(CNN)的性能,但同时具有2D 卷积神经网络的复杂性。
研究人员在论文中指出:“传统2D CNN在计算上成本低,但无法捕获时间关系。基于3D CNN的方法可以实现良好性能,但计算量庞大,因此部署成本高。在论文中,我们提出了通用且有效的时间转移模块(TSM),它既高效又具有高性能。”
该团队认为,这种方法可以将模型缩小到1/6,也就是将最先进模型中的1.5亿个参数减少到2500万个参数。
麻省理工学院(MIT)的助理教授,及该论文的合著者Song Han说:“我们的目标是使任何通过低功耗设备工作的人都可以使用AI。要做到这一点,我们需要设计耗能更少的高效AI模型,这个模型可以在边缘设备上平稳运行。”
这项研究的主要作者Ji Lin展示了安装在摄像机上的单个NVIDIA Jetson Nano如何能够在仅12.4毫秒的延迟下立即对手势进行分类。
研究小组在橡树岭国家实验室借助Summit训练这种算法。在那里,Lin和他的团队使用NVIDIA V100 GPU和cuDNN加速的PyTorch深度学习框架,仅在14分钟内就训练了他们的模型。
研究人员说:“大型AI训练工作的计算要求每3.5个月翻一番。我们能否继续突破技术极限,取决于超高效算法与强大机器相匹配的战略。”
研究人员还在GitHub上发布了实现PyTorch的代码。











