
NVDLA 深度学习推理编译器现已开源
2019-09-20 17:47
 分享到微信
分享到微信
 分享到微博
分享到微博
为深度学习设计新的定制化硬件加速器,是件备受广大开发者欢迎的事情,但是如想要这种新的设计能够同时实现最先进的性能和效率,却是一项复杂且具有挑战性的难题。
两年前,NVIDIA为NVIDIA深度学习加速器(NVIDIA Deep Learning Accelerator,简称:NVDLA)的硬件设计开源代码,以帮助推动在定制化硬件设计中采用高效的AI推理。同样的NVDLA也被移植在NVIDIA Jetson AGX Xavier开发工具包中,为AI提供了最佳峰值为7.9 TOPS/W的效率。随着NVDLA在GitHub上的优化编译器的开源发布,系统架构师和软件团队现在已经拥有了世界上第一个完全开放的软硬件推理平台的完整源代码。
本文将解释网络图形编译器在实现专用硬件加速器的电源效率这一关键目标中所扮演的角色,并展示如何通过在云端构建和运行用户自己的自定义NVDLA软件和硬件设计开始。
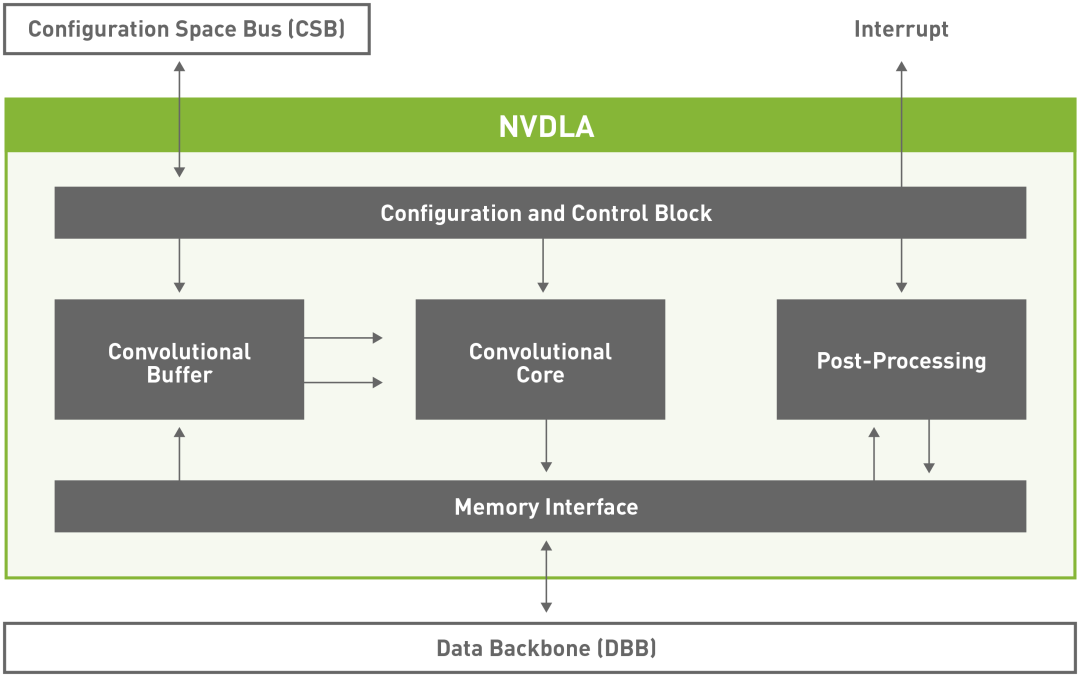
NVDLA Block Diagram

使用NVDLA进行目标检测
NVDLA编译器的性能及效率
该编译器是NVDLA软件栈的关键组件。它生成优化的执行图,将预先训练的神经网络模型层中定义的任务映射到NVDLA中的各个执行单元。它在最大限度地利用计算硬件的同时,尽可能地减少数据移动。
NVDLA核心硬件有六个专门的硬件单元,它们可以同时调度,也可以在流水线配置中调度。它还具有小型和大型硬件配置文件。大的配置文件包括先进的功能,如芯片上的SRAM接口和附加一个微控制器的能力。硬件架构是模块化的,它的设计具有可拓展性,从小型嵌入式物联网设计到使用NVDLA单元阵列的大型数据中心类芯片。编译器可以根据各种选择的因素进行调优:NVDLA硬件配置、系统的CPU和内存控制器配置,以及应用程序的自定义神经网络用例(如果需要的话)。
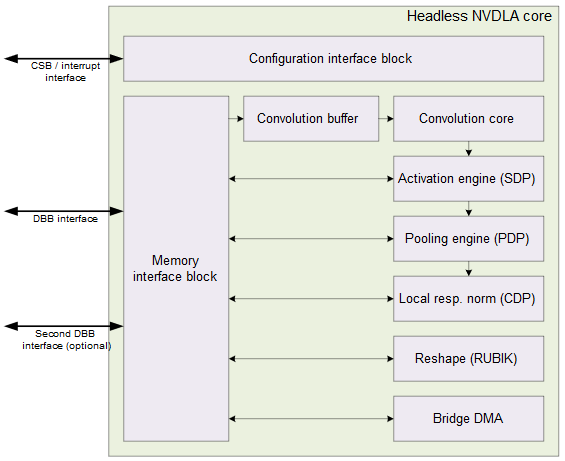
NVDLA Small Profile Model
编译器优化,如层融合和管道调度工作良好的大型NVDLA设计,提供了高达3倍的性能效益,跨广泛的神经网络架构。这种优化灵活性是实现跨大型网络模型(如ResNet-50)和小型网络模型(如MobileNet)的能效的关键。

对于较小的NVDLA设计,编译器优化(如内存平铺)对于提高能效至关重要。内存平铺使设计能够在权重和激活数据之间平衡片上缓冲区的使用,从而最小化片外内存流量和功耗。
此外,用户可以自由地创建完全定制的层,根据他们自己的特殊用例进行调优,或者使用研究中发表的最新前沿算法进行实验。
用户可以根据下面的性能数字来评估默认NVDLA大概要模型的预期性能。该数据结果是使用Jetson AGX Xavier开发工具包上的两个NVDLA核心之一获取的。

在AWS上使用RISC-V
和FireSim在云端进行设计
通过这个编译器版本,NVDLA用户可以完全访问集成、增长和探索NVDLA平台所需的软件和硬件源代码。开始的最佳方法之一是直接使用NVDLA上的YOLOv3和云中的RISC-V和FireSim进行对象检测。
要使用FireSim- nvdla,请按照FireSim的说明操作,直到能够运行单节点模拟为止。按照步骤操作,在“设置FireSim Repo”一节中,验证您正在使用firesim-nvdla 存储库,如下所示:

使用NVDLA运行单节点模拟之后,按照NVDLA教程中的步骤运行YOLOv3,你应该很快就可以运行YOLOv3了。
NVIDIA很高兴能与SiFive这样的初创公司合作,提供开源的深度学习解决方案。

SiFive使用NVDLA运行深度学习推理
SiFive CTO、联合创始人,及 RISC-V联合发明者Yunsup Lee表示:“我们非常高兴看到NVIDIA在开发开放源代码机器学习生态系统方面的所做出的贡献。一年前,SiFive首次展示了在SiFive Freedom平台上运行的NVDLA,新的性能优化开源NVDLA编译器进一步使SiFive能够创建特定领域的优化SoC设计,以满足物联网边缘AI的现代计算需求。”
两年前,NVIDIA为NVIDIA深度学习加速器(NVIDIA Deep Learning Accelerator,简称:NVDLA)的硬件设计开源代码,以帮助推动在定制化硬件设计中采用高效的AI推理。同样的NVDLA也被移植在NVIDIA Jetson AGX Xavier开发工具包中,为AI提供了最佳峰值为7.9 TOPS/W的效率。随着NVDLA在GitHub上的优化编译器的开源发布,系统架构师和软件团队现在已经拥有了世界上第一个完全开放的软硬件推理平台的完整源代码。
本文将解释网络图形编译器在实现专用硬件加速器的电源效率这一关键目标中所扮演的角色,并展示如何通过在云端构建和运行用户自己的自定义NVDLA软件和硬件设计开始。
NVDLA Block Diagram
使用NVDLA进行目标检测
NVDLA编译器的性能及效率
该编译器是NVDLA软件栈的关键组件。它生成优化的执行图,将预先训练的神经网络模型层中定义的任务映射到NVDLA中的各个执行单元。它在最大限度地利用计算硬件的同时,尽可能地减少数据移动。
NVDLA核心硬件有六个专门的硬件单元,它们可以同时调度,也可以在流水线配置中调度。它还具有小型和大型硬件配置文件。大的配置文件包括先进的功能,如芯片上的SRAM接口和附加一个微控制器的能力。硬件架构是模块化的,它的设计具有可拓展性,从小型嵌入式物联网设计到使用NVDLA单元阵列的大型数据中心类芯片。编译器可以根据各种选择的因素进行调优:NVDLA硬件配置、系统的CPU和内存控制器配置,以及应用程序的自定义神经网络用例(如果需要的话)。
NVDLA Small Profile Model
编译器优化,如层融合和管道调度工作良好的大型NVDLA设计,提供了高达3倍的性能效益,跨广泛的神经网络架构。这种优化灵活性是实现跨大型网络模型(如ResNet-50)和小型网络模型(如MobileNet)的能效的关键。
对于较小的NVDLA设计,编译器优化(如内存平铺)对于提高能效至关重要。内存平铺使设计能够在权重和激活数据之间平衡片上缓冲区的使用,从而最小化片外内存流量和功耗。
此外,用户可以自由地创建完全定制的层,根据他们自己的特殊用例进行调优,或者使用研究中发表的最新前沿算法进行实验。
用户可以根据下面的性能数字来评估默认NVDLA大概要模型的预期性能。该数据结果是使用Jetson AGX Xavier开发工具包上的两个NVDLA核心之一获取的。
在AWS上使用RISC-V
和FireSim在云端进行设计
通过这个编译器版本,NVDLA用户可以完全访问集成、增长和探索NVDLA平台所需的软件和硬件源代码。开始的最佳方法之一是直接使用NVDLA上的YOLOv3和云中的RISC-V和FireSim进行对象检测。
要使用FireSim- nvdla,请按照FireSim的说明操作,直到能够运行单节点模拟为止。按照步骤操作,在“设置FireSim Repo”一节中,验证您正在使用firesim-nvdla 存储库,如下所示:
使用NVDLA运行单节点模拟之后,按照NVDLA教程中的步骤运行YOLOv3,你应该很快就可以运行YOLOv3了。
NVIDIA很高兴能与SiFive这样的初创公司合作,提供开源的深度学习解决方案。
SiFive使用NVDLA运行深度学习推理
SiFive CTO、联合创始人,及 RISC-V联合发明者Yunsup Lee表示:“我们非常高兴看到NVIDIA在开发开放源代码机器学习生态系统方面的所做出的贡献。一年前,SiFive首次展示了在SiFive Freedom平台上运行的NVDLA,新的性能优化开源NVDLA编译器进一步使SiFive能够创建特定领域的优化SoC设计,以满足物联网边缘AI的现代计算需求。”











