
如何用基于TensorRT的BERT模型实现实时自然语言理解?
2019-08-23 10:28
 分享到微信
分享到微信
 分享到微博
分享到微博
NLP研究人员和开发者们面临的一个主要问题是在执行某一特定NLP任务时,缺少经过标记的训练数据。而NLP领域最近的一项突破完美地解决了这一难题,让大家可以使用未经过标记的文本进行NLP训练,并将NLP任务分解为两个部分:1)学习如何表示词语的含义及其之间的关系,即:利用辅助任务和大量的文本语料库建立语言模型;2)将语言模型用于一个相对较小的特定任务网络中,并在监督的情况下进行训练,从而将语言模型专门转化为实际任务。
- 将经过微调的权重和网络定义传入TensorRT生成器,以创建TensorRT引擎;
- 使用此引擎启动TensorRT运行时刻程序;
- 向TensorRT运行时刻程序提供一段文章和一个问题,并获得网络预测的答案。
整个工作流程如图2所示。
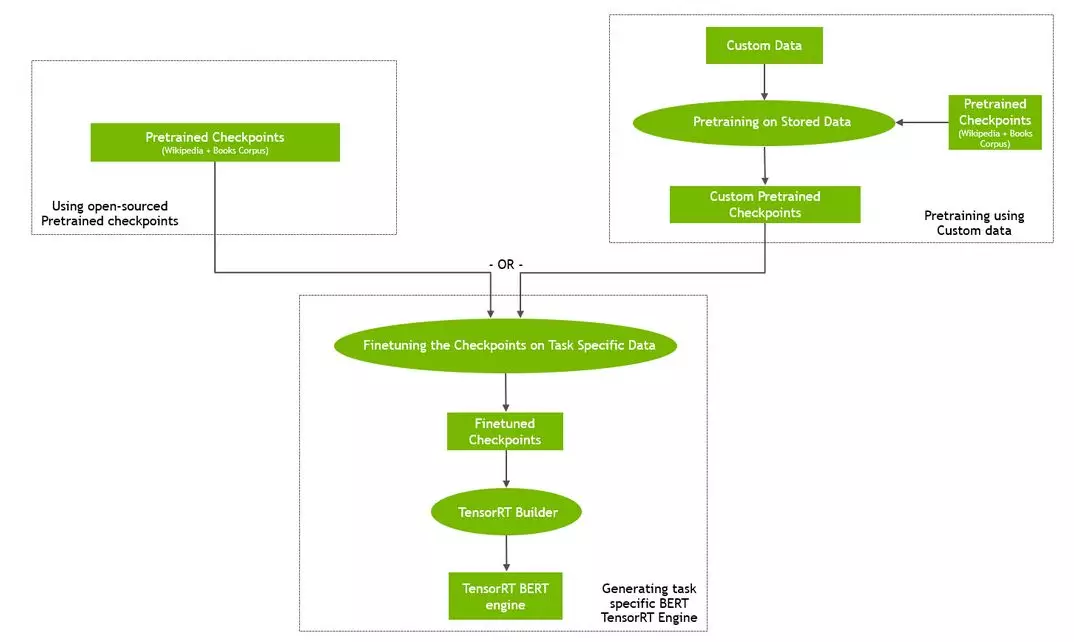
通过以下步骤设置你的环境以进行BERT推理:
- 创建具有前提条件的docker镜像
- 编译TensorRT优化插件
- 基于微调的权重创建TensorRT引擎
- 根据给定的段落和查询进行推理
# Clone the TensorRT repository and navigate to BERT demo directory
git clone --recursive https://github.com/NVIDIA/TensorRT && cd TensorRT/demo/BERT
# Create and launch the docker image
sh python/create_docker_container.sh
# Build the plugins and download the fine-tuned models
cd TensorRT/demo/BERT && sh python/build_examples.sh
# Build the TensorRT runtime engine
python python/bert_builder.py -m /workspace/models/fine-tuned/bert_tf_v2_base_fp16_384_v2/model.ckpt-8144 -o bert_base_384.engine -b 1 -s 384 -c /workspace/models/fine-tuned/bert_tf_v2_base_fp16_384_v2
现在,输入一个段落,通过提出几个问题,看看它能破译多少信息。
python python/bert_inference.py -e bert_base_384.engine -p "TensorRT is a high performance deep learning inference platform that delivers low latency and high throughput for apps such as recommenders, speech and image/video on NVIDIA GPUs. It includes parsers to import models, and plugins to support novel ops and layers before applying optimizations for inference. Today NVIDIA is open sourcing parsers and plugins in TensorRT so that the deep learning community can customize and extend these components to take advantage of powerful TensorRT optimizations for your apps." -q "What is TensorRT?" -v /workspace/models/fine-tuned/bert_tf_v2_base_fp16_384_v2/vocab.txt -b 1
Passage: TensorRTis a high performance deep learning inference platform that delivers low latency and high throughput for apps such as recommenders, speech and image/video on NVIDIA GPUs. It includes parsers to import models, and plugins to support novel ops and layers before applying optimizations for inference. Today NVIDIA is open sourcing parsers and plugins in TensorRT so that the deep learning community can customize and extend these components to take advantage of powerful TensorRT optimizations for your apps.
Question: What is TensorRT?
Answer:'a high performance deep learning inference platform'
给定同一篇文章,提出不同的问题。
Question: Whatis included in TensorRT?
Answer: 'parsers to import models, and plugins to support novel ops and layers before applying optimizations for inference'
sh create_docker_container.sh
在完成环境搭建后,下载BERT的微调权重。请注意,你不需要用预先训练的权重来创建TensorRT引擎(只是微调的权重)。除了微调权重之外,还可以使用关联的配置文件,该文件指定诸如注意头数量、层数等参数以及vocab.txt file文件,该文件包含了在训练过程中学习到的词汇。它们将通过自NGC下载的微调模型打包,并可利用build_examples.sh脚本下载。作为该脚本的一部分,你可以为要下载的BERT模型指定一组特定的微调权重。命令行参数控制稍后将用于模型构建和推理的具体BERT模型,其使用方式如下:
用法:sh build_examples.sh [base | large] [ft-fp16 | ft-fp32] [128 | 384]
- base | large——确定是下载Bert-Base还是下载Bert-Large模型进行优化
- ft-fp16 | ft-fp32——确定是下载精度FP16还是FP32的微调BERT模型
- 128 | 384 —— 确定下载序列长度为128还是384的BERT模型
# Running with default parameters
sh build_examples.sh
# Running with custom parameters (BERT-large, FP132 fine-tuned weights, 128 sequence length)
sh build_examples.sh large ft-fp32 128
该脚本将首先使用示例报告中的代码,并构建用于BERT推理的TensorRT插件。接下来,它下载并安装NGC CLI,以便从NVIDIA NGC模型报告中下载经过微调的模型。build_examples.sh的命令行参数指定要使用TensorRT优化的模型。默认情况下,它下载经过微调的BERT-base,精度为FP16,序列长度为384。
- -m,–微调模型的检查点文件
- -o,–输出TensoRT引擎文件(即bert.engine)的路径
- -b,–用于推理的批处理程序大小(默认值=1)
- -s,–与下载的BERT微调模型匹配的序列长度
- -c,–包含BERT参数配置文件的目录(注意头、隐藏层等)
python python/bert_builder.py -m /workspace/models/fine-tuned/bert_tf_v2_base_fp16_384_v2/model.ckpt-8144 -o bert_base_384.engine -b 1 -s 384 -c /workspace/models/fine-tuned/bert_tf_v2_base_fp16_384_v2
现在你应该已经有了一个TensorRT引擎(即bert.engine)用于问答的推理脚本(bert_inference.py)。我们将在后面的章节中阐述构建TensorRT引擎的过程。现在,你可以向bert_inference.py提供一个段落和一个查询,并查看模型是否能够正确地回答你的查询。与推理脚本交互的方法有几种:可以将段落和问题作为命令行参数提供(使用–passage和–question标志),也可以从给定文件传递(使用–passage_file和–question_file标志)。如果在执行过程中没有给出这两个标志,那么在执行开始后,将提示用户输入段落和问题。bert_inference.py脚本的参数如下:
- -e, –bert_engine——上一步骤中创建的TensorRT引擎的路径
- -p,–passage——Bert QA段落文本
- -pf,–passage_file——包含段落文本的文件
- -q,–question——用于BERT 问答查询/问题的文本
- -qf,–question_file——包含查询/问题文本的文件
- -v,–vocab__file——包含整个单词字典的文件
- -b,–batch_size——用于推理的批处理程序大小
有关推理过程的逐步描述和演练,请参阅示例文件夹中的python脚本bert_inference.py和详细的Jupyter笔记本BERT_TRT.ipynb。在本节中,我们将回顾使用Tensorrt进行推理的一些关键参数和概念。
BERT(更具体地说是编码器层)使用以下参数来控制其操作:
- 批处理程序大小
- 序列长度
- 注意力头文件数量
对于每个编码器,还要指定隐藏层的数量和注意力头文件的大小。你还可以从TensorFlow检查点文件中读取所有上述参数。
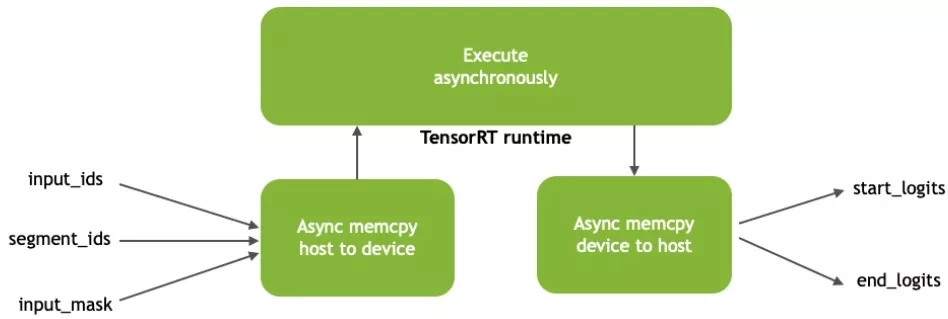
如图3所示,BERT模型的输入包括:
- input_ids:带有段落的标记ids的张量,与用作推理输入的问题连接在一起;
- segment_ids:区分段落和问题;
- input_mask:表示序列中哪些元素是标记,哪些是填充元素。
让我们来浏览一下在TensorRT优化BERT中实施的关键优化。
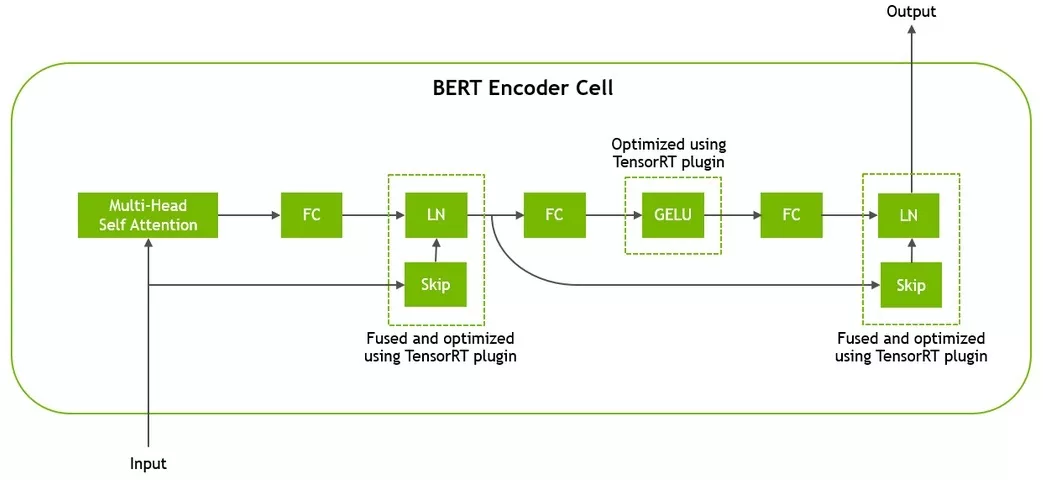
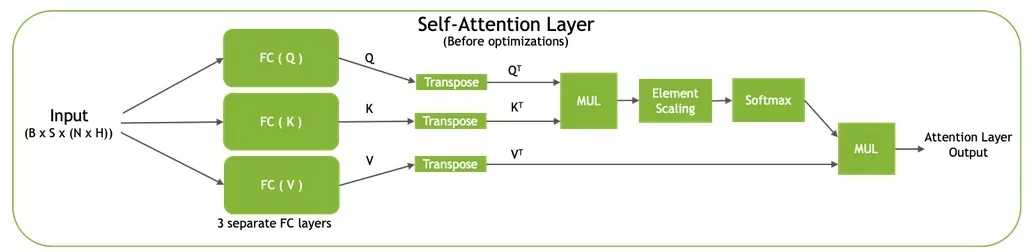
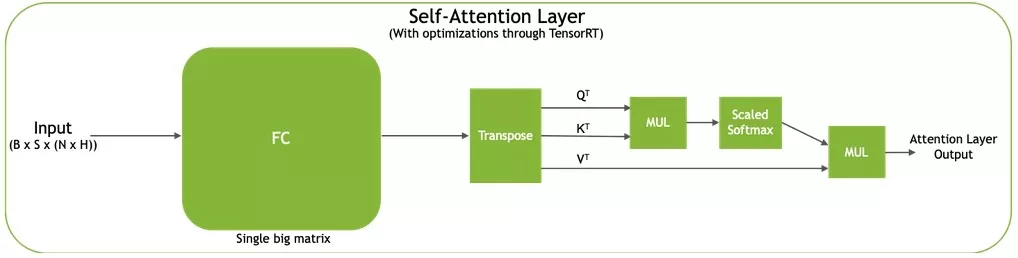
BERT架构基于Transformer,由12个用于BERT-base和24个用于BERT-large的Transformer单元组成。在被Transformer处理之前,输入令牌通过一个嵌入层传递,该层查找它们的向量表示并编码它们在句子中的位置。每个Transformer单元由两个连续的残差块组成,每个残差块后接层归一化。第一残差块取代第一完全连接(FC)层并通过多头自注意力机制激活,第二残差块使用高斯误差线性单元(GELU)激活。图4说明了Transformer单元的结构。
Gelu激活执行以下元素计算,其中a、b和c是一些标量常量:
gelu(x) = a * x * (1 + tanh( b * (x + c * x^3) ))
Result= x^3
Result= c * Result
Result= x + Result
Result = b * Result
Result = tanh(Result)
Result = x * Result
Result= a * Result
对于k层,简单的实施将需要k-1不必要的全局内存往返,我们将其合并到单个CUDA核心中的元素计算中。有关详细信息,请参阅插件目录中的geluPlugin.cu。
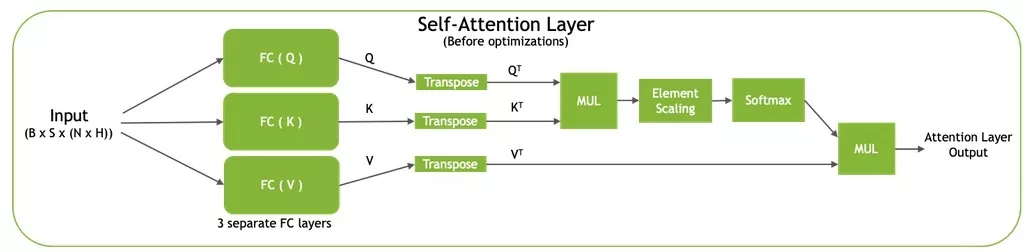
请参阅插件目录中的qkvToContextPlugin.cu了解自注意力的实现。
BERT可以应用于线上用例和离线用例。线上NLU应用程序(例如:会话AI)在推理过程中会有严格的延迟要求。为了响应单个用户查询,需要按顺序执行多个模型。当用作服务时,客户的等待总时间包括了计算时间以及输入和输出的网络延迟。时间越长,客户体验越差。
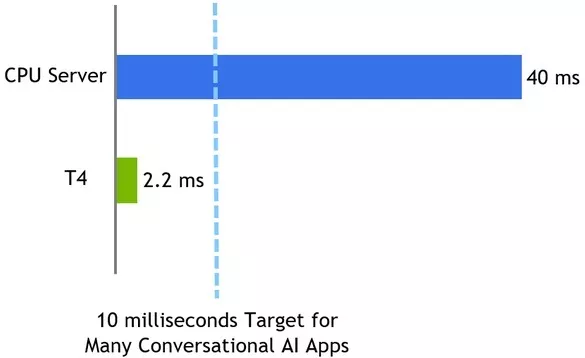
该基准测试通过一个问答任务测量延迟。在此问答任务网络执行过程中,我们把通过张量作为输入,将logits作为输出,计算从输入到输出的过程中计算时间的延迟。你可以在sampleBERT.cpp中找到用于对示例进行基准测试的代码。
NVIDIA正在逐步地将多种优化功能开源,使大家可以利用基于T4 GPU的TensorRT在2.2毫秒内完成BERT推理。这些优化代码在TensorRT开源报告中作为开源示例提供。如需在GCP上运行该示例,你可以从谷歌云人工智能中心访问。该报告演示了如何优化 Transformer层,Transformer层是当前BERT和其他几种语言模型的核心要素。我们希望你能够轻松地自定义这些要素,以适用于你的自定义模型和应用程序。本文概述了如何使用TensorRT示例、关键优化和性能结果。我们进一步阐述了如何将BERT示例用作简单应用程序和Jupyter笔记本的一部分工作流,你可以在其中传递一个段落并提出与之相关的问题。
我们一直在寻找分享新示例和应用的新思路。你会将BERT用于哪些NLP应用?将来你又希望从我们这里了解到哪些示例?











