
一文读懂会话AI到底是个啥
2019-08-21 09:42
 分享到微信
分享到微信
 分享到微博
分享到微博
一段高质量的人机对话,应该是响应迅速,应答智能且声音自然的。
但是直到目前,支持实时语音应用程序的语言处理神经网络的开发人员都面临着一个无奈的权衡:想要速度快就会牺牲掉应答的质量,追求智能的应答则响应会变得很慢。
这是因为人类的对话是极其复杂的。每个语句都建立在既定的上下文以及之前的互动基础之上。从圈内玩笑到文化元素和文字游戏,人类一直在以连贯且细致入微的方式讲话。每一个响应几乎都是立即紧跟着上一个句子。朋友们在交流的时候甚至都能预料到对方会说什么。
什么是会话AI?
真正的会话AI是一个语音助手,它可以进行类似人类的对话,捕获上下文并提供智能的应答。满足这些需求的AI模型一定是庞大且高度复杂的。
借助于NVIDIA GPU和CUDA-X AI库可以快速地训练并优化大量最先进的语言模型,从而能够在短短几毫秒,甚至是千分之一秒内运行推理。
这些突破有助于开发人员构建和部署迄今为止最先进的神经网络,并使我们更接近创造真正会话AI的目标。
GPU优化的语言理解模型可以集成到医疗、零售和金融服务等行业的人工智能应用程序中,为智能音响和客户服务线中的高级数字语音助理赋力。这些高质量的会话AI工具可以让各个行业的企业为客户提供前所未有的个性化服务标准。
会话AI的速度需要有多快?
在自然对话中,标准反应间隔时间约为200毫秒。为了让AI模仿人类之间的交流,它可能需要连续运行十几个或更多的神经网络,作为多层任务的一部分——所有这些都在200毫秒或更短的时间内完成。
回答一个问题需要以下几个步骤:先将用户的语音转换为文本,然后理解文本的含义,根据上下文搜索能够提供的最佳应答,最后使用文本转换语音的工具来提供应答。每一个步骤都需要运行多个AI模型,因此每个网络执行的可用时间大约为10毫秒或更少。
如果每个模型运行的时间过长,就会导致响应过慢,从而让对话变得突兀且不自然。
在如此严苛的延迟标准之下,现有语言理解工具的开发人员必须做出权衡。一个高质量、复杂的模型可以用作一个聊天机器人,同在语音接口中相比,延迟在这里并不是那么关键性的问题。或者,开发者可以借助一个不那么庞大的语言处理模型,这种模型可以更快地给出结果,只是缺乏细致的应答。
未来的会话AI听起来会是什么样的?
诸如电话树算法之类的基本语音接口(带有诸如“预订新航班,包含预定关键词”之类的提示)是事务处理性的,需要一组步骤和响应来通过预先编程的队列移动用户。有时只有电话树末端的工作人员才能理解细微的问题并智能地解决来电者的问题。
如今市场上的语音助手可以做得更多,但他们所基于的语言模型并不像他们想象的那么复杂。那些模型其实只包含数百万个参数,而不是数十亿个参数。这些AI工具可能会在对话中停滞不前,在回答提出的问题之前会先给出一个类似“让我帮你查一下”的回答。或者他们会显示一个网络搜索的结果列表,而不是用会话的语言针对查询做出应答。
一个真正的会话AI会更进一步。理想中的模型是一个足够复杂的模型,它能够准确理解一个人对其银行对账单或医疗报告结果的查询,并且能够以近乎即时的自然语言进行无缝响应。
这种技术可以应用在医生办公室的语音助理,帮助患者安排预约和后续血液测试,或者应用到零售语音AI当中,以向来电者解释为什么包裹发货延迟并提供商店信用。
对这种高级的AI会话工具的需求正在上升:到2020年,预计50%的搜索将使用语音进行;到2023年,将有80亿数字语音助理投入使用。
BERT是什么?
BERT是一个大型的计算密集型模型,去年一经发布便为自然语言理解奠定了基础。通过调优,它可以应用于广泛的语言任务当中,如阅读理解、情感分析或提问回答。
BERT学习了包含有33亿个单词的英语语料库,在某些情况下,它比一般人类更擅长理解语言。它的优势在于它能够在未标记的数据集上进行训练,并且在最少修改的情况下被推广到广泛的应用程序中。
同一个BERT可用于理解多种语言,并可以通过微调以执行特定任务,如翻译、自动完成或对搜索结果进行排序。其多功能性的特点使它成为用于开发复杂自然语言理解的一种流行选择。
BERT的基础是Transformer层,这是一种神经网络的替代。它应用了注意力技术,即通过集中注意力在前后最具关联性的单词上解析句子。
目前,跨领域的主要语言处理模型都基于BERT,包括BioBERT(用于生物医学文档)和SciBERT(用于科学出版物)。
NVIDIA技术
如何优化基于Transformer的模型?
NVIDIA GPU的并行处理能力和Tensor 核心架构在处理复杂语言模型时可以提供更高的吞吐量和可扩展性,从而为BERT的训练和推理提供记录设置性能。
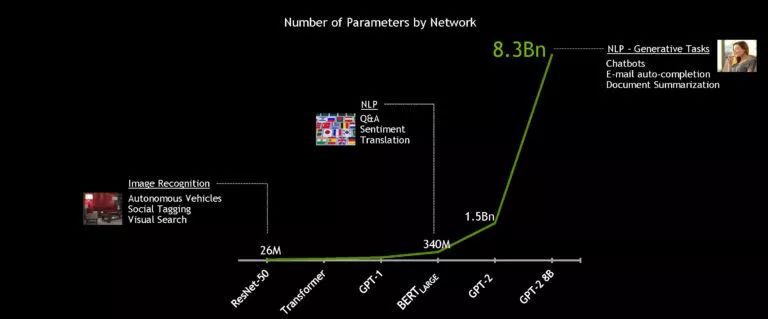
借助强大的NVIDIA DGX SuperPOD系统,3.4亿参数的BERT-Large 模型可以在一小时内完成训练,而一般的训练都需要花费几天的时间。但是对于实时会话AI,关键的加速是推理。
NVIDIA开发人员使用TensorRTsoftware 对拥有1.1亿个参数的BERT基本模型做了优化,以用于推理任务。将该模型运行于NVIDIA T4 GPU之上,使用斯坦福问题回答数据集(Stanford Question Answering Dataset)对其进行测试时,该模型能够在2.2毫秒内计算出响应。这里所采的测试数据集名为SQuAD,是评估模型理解上下文能力的流行基准。
许多实时应用程序的延迟阈值为10毫秒。即使是高度优化的CPU代码,也需要超过40毫秒的处理时间。
通过将推理时间缩短到几毫秒,使得在生产环境中部署BERT成为可能。而且,不仅限于BERT,同样的方法也可以用来加速其他基于Transformer的大型自然语言模型,如GPT-2,XLnet和RoBERTa。
为了实现真正的对话人工智能的目标,语言模型将变得越来越大。未来的模型将比现在使用的模型大很多倍,因此NVIDIA构建并开源了迄今为止最大的基于Transformer的AI:GPT-2 8B,这是一个拥有83亿参数的语言处理模型,比BERT-Large大24倍。
但是直到目前,支持实时语音应用程序的语言处理神经网络的开发人员都面临着一个无奈的权衡:想要速度快就会牺牲掉应答的质量,追求智能的应答则响应会变得很慢。
这是因为人类的对话是极其复杂的。每个语句都建立在既定的上下文以及之前的互动基础之上。从圈内玩笑到文化元素和文字游戏,人类一直在以连贯且细致入微的方式讲话。每一个响应几乎都是立即紧跟着上一个句子。朋友们在交流的时候甚至都能预料到对方会说什么。
什么是会话AI?
真正的会话AI是一个语音助手,它可以进行类似人类的对话,捕获上下文并提供智能的应答。满足这些需求的AI模型一定是庞大且高度复杂的。
借助于NVIDIA GPU和CUDA-X AI库可以快速地训练并优化大量最先进的语言模型,从而能够在短短几毫秒,甚至是千分之一秒内运行推理。
这些突破有助于开发人员构建和部署迄今为止最先进的神经网络,并使我们更接近创造真正会话AI的目标。
GPU优化的语言理解模型可以集成到医疗、零售和金融服务等行业的人工智能应用程序中,为智能音响和客户服务线中的高级数字语音助理赋力。这些高质量的会话AI工具可以让各个行业的企业为客户提供前所未有的个性化服务标准。
会话AI的速度需要有多快?
在自然对话中,标准反应间隔时间约为200毫秒。为了让AI模仿人类之间的交流,它可能需要连续运行十几个或更多的神经网络,作为多层任务的一部分——所有这些都在200毫秒或更短的时间内完成。
回答一个问题需要以下几个步骤:先将用户的语音转换为文本,然后理解文本的含义,根据上下文搜索能够提供的最佳应答,最后使用文本转换语音的工具来提供应答。每一个步骤都需要运行多个AI模型,因此每个网络执行的可用时间大约为10毫秒或更少。
如果每个模型运行的时间过长,就会导致响应过慢,从而让对话变得突兀且不自然。
在如此严苛的延迟标准之下,现有语言理解工具的开发人员必须做出权衡。一个高质量、复杂的模型可以用作一个聊天机器人,同在语音接口中相比,延迟在这里并不是那么关键性的问题。或者,开发者可以借助一个不那么庞大的语言处理模型,这种模型可以更快地给出结果,只是缺乏细致的应答。
未来的会话AI听起来会是什么样的?
诸如电话树算法之类的基本语音接口(带有诸如“预订新航班,包含预定关键词”之类的提示)是事务处理性的,需要一组步骤和响应来通过预先编程的队列移动用户。有时只有电话树末端的工作人员才能理解细微的问题并智能地解决来电者的问题。
如今市场上的语音助手可以做得更多,但他们所基于的语言模型并不像他们想象的那么复杂。那些模型其实只包含数百万个参数,而不是数十亿个参数。这些AI工具可能会在对话中停滞不前,在回答提出的问题之前会先给出一个类似“让我帮你查一下”的回答。或者他们会显示一个网络搜索的结果列表,而不是用会话的语言针对查询做出应答。
一个真正的会话AI会更进一步。理想中的模型是一个足够复杂的模型,它能够准确理解一个人对其银行对账单或医疗报告结果的查询,并且能够以近乎即时的自然语言进行无缝响应。
这种技术可以应用在医生办公室的语音助理,帮助患者安排预约和后续血液测试,或者应用到零售语音AI当中,以向来电者解释为什么包裹发货延迟并提供商店信用。
对这种高级的AI会话工具的需求正在上升:到2020年,预计50%的搜索将使用语音进行;到2023年,将有80亿数字语音助理投入使用。
BERT是什么?
BERT是一个大型的计算密集型模型,去年一经发布便为自然语言理解奠定了基础。通过调优,它可以应用于广泛的语言任务当中,如阅读理解、情感分析或提问回答。
BERT学习了包含有33亿个单词的英语语料库,在某些情况下,它比一般人类更擅长理解语言。它的优势在于它能够在未标记的数据集上进行训练,并且在最少修改的情况下被推广到广泛的应用程序中。
同一个BERT可用于理解多种语言,并可以通过微调以执行特定任务,如翻译、自动完成或对搜索结果进行排序。其多功能性的特点使它成为用于开发复杂自然语言理解的一种流行选择。
BERT的基础是Transformer层,这是一种神经网络的替代。它应用了注意力技术,即通过集中注意力在前后最具关联性的单词上解析句子。
目前,跨领域的主要语言处理模型都基于BERT,包括BioBERT(用于生物医学文档)和SciBERT(用于科学出版物)。
NVIDIA技术
如何优化基于Transformer的模型?
NVIDIA GPU的并行处理能力和Tensor 核心架构在处理复杂语言模型时可以提供更高的吞吐量和可扩展性,从而为BERT的训练和推理提供记录设置性能。
借助强大的NVIDIA DGX SuperPOD系统,3.4亿参数的BERT-Large 模型可以在一小时内完成训练,而一般的训练都需要花费几天的时间。但是对于实时会话AI,关键的加速是推理。
NVIDIA开发人员使用TensorRTsoftware 对拥有1.1亿个参数的BERT基本模型做了优化,以用于推理任务。将该模型运行于NVIDIA T4 GPU之上,使用斯坦福问题回答数据集(Stanford Question Answering Dataset)对其进行测试时,该模型能够在2.2毫秒内计算出响应。这里所采的测试数据集名为SQuAD,是评估模型理解上下文能力的流行基准。
许多实时应用程序的延迟阈值为10毫秒。即使是高度优化的CPU代码,也需要超过40毫秒的处理时间。
通过将推理时间缩短到几毫秒,使得在生产环境中部署BERT成为可能。而且,不仅限于BERT,同样的方法也可以用来加速其他基于Transformer的大型自然语言模型,如GPT-2,XLnet和RoBERTa。
为了实现真正的对话人工智能的目标,语言模型将变得越来越大。未来的模型将比现在使用的模型大很多倍,因此NVIDIA构建并开源了迄今为止最大的基于Transformer的AI:GPT-2 8B,这是一个拥有83亿参数的语言处理模型,比BERT-Large大24倍。











